文件系统是Agent的省钱答案?token消耗降低45%,费用减少39%

新智元报道
新智元报道

【新智元导读】文件系统可以让Agent更高效地「找东西」,降低了认知负担,提高了任务执行效率,减少了45%的token消耗和39%的成本,同时保持较高准确率。
当同一个模型面对同一份数据时,接口长什么样,会不会直接改变它花掉多少 token(模型上下文与计费的基本单位)?
答案是会,而且差别不小。

博客链接:https://nokv.io/blog/agents-want-filesystems
研究人员在博客中分享了自己的实验,做了一个开放benchmark:让同一个模型,在同一份机器学习实验数据上,完成同一组研究任务。唯一变化是接口。
一边是原生SQLite/SQL;另一边是NoKV的文件系统形态namespace,也就是让训练run像目录、日志像文件、搜索像grep一样工作。
结果很直接:文件系统形态的接口少用了45%的token,账单低了39%,正确率还略高。
NoKV是一个面向 智能体工作空间 (AI Agent workspace) 的元数据控制层:它把实验run、日志、checkpoint(检查点)、artifact(实验产物)等工作结果,放进一个文件系统形态的命名空间里,让 Agent 可以像工程师一样用ls、grep、read去找线索、看证据、引用行号。
在公开资料中,NoKV已经出现在CNCF Cloud Native Landscape(云原生基金会前瞻项目)中。
CNCF是Linux Foundation(Linux 基金会)体系下的云原生计算基金会;NoKV在这张 landscape 里被归类到了AI Native Infra / Storage分区。
NoKV早期自研的Go原生存储引擎,也以历史数据库条目被 CMU Database of Databases(dbdb.io)收录。这里需要说明一下:DBDB条目对应的是历史上的Go存储引擎;当前NoKV主线已经演进为Rust实现的Agent workspace文件系统产品线。
想象你让一个AI Agent帮你做实验复盘:
「帮我找出验证集损失最低的5个训练run,顺便告诉我它们的学习率、batch size、stdout 有多大,以及当时的git状态。」
一个人类工程师会怎么做?大概率不是先背下整张数据库的表结构,也不是先在脑子里推导所有 join关系。更自然的路径是:进入实验目录,列一下有哪些run,搜索相关字段,打开必要日志,再把证据贴出来。
也就是:ls → grep → read → 引用行号
但如果把同一件事交给一个只看SQL表的Agent,它要先理解:run元数据在哪张表,指标在哪张表,参数怎么展开,日志blob在哪里,run id和 artifact id怎么关联,stdout/stderr如何映射到文件内容。
SQL当然能表达这些关系。问题是,Agent在找到答案之前,就已经开始付费了。
每多读一段 schema、每多试一次错误查询、每多把一整段日志拖进上下文,都会消耗token;错误运行不因为错误就免费。
研究人员认为:决定Agent token 效率的变量不只有模型和提示词,还包括Agent面对的操作界面(Interface/Surface)。
Fable 5的横空出世给了开发者们一个警醒,如果独立开发者能调用强模型、迅速搭建自己的 Agent,那么「有 Agent」本身很快就不再稀缺。
真正拉开差距的,是Agent每天执行成千上万次任务时的token economy harness:一次任务要读多少上下文、走多少步、犯多少错、烧掉多少 token。
说「Agent 想要文件系统」,听上去像拟人化。更准确地说,是今天的大语言模型在训练数据、后训练任务和工具生态里,反复学到了一套非常稳定的工作模式:进入目录 → 列文件 → 搜关键词 → 打开局部内容 → 引用具体行号
这套模式并不神秘。互联网上有大量shell、Unix 工具、Git、日志排查、代码仓库浏览和命令行调试语料;过去两年英文coding agent大火,导致后训练中在不断强化基础模型对目录树、文件路径、grep、cat、diff和行号的使用能力。今天最稳定能力最强的一批Agent还仍然主要是Coding Agent,不只是因为代码任务重要,也因为代码仓库天然给了模型一个它熟悉的操作空间。
文件系统语义对 Agent 友好,主要不是因为「文件」这个存储介质,而是因为它提供了一种 progressive disclosure(渐进式披露)的交互方式:
先低成本发现:
ls看有哪些东西,stat看对象卡片,catalog看可查询字段。再按需读取:只有找到目标后,才用
read打开内容。搜索可以限定范围:全局
grep用来发现线索,目录内grep用来提取证据。路径是稳定句柄:
/runs/abc/stdout.log既是名字,也是后续继续操作的地址。
相比之下,SQL 更像是要求 Agent 先理解一张地图,然后一次性写出正确路线。对于清晰的结构化聚合,这很强;但对于「先找 cohort(样本组),再查日志,再引用证据」的复合探索任务,前置认知成本会变高。
近两年,大模型公司和 Agent 系统开发者也在独立收敛到类似结论:
Letta的Agent memory benchmark中,一个把对话历史保存为文件的Agent,在LoCoMo长对话记忆任务上取得了有竞争力的结果。
Anthropic在MCP code execution(用代码执行MCP工具)的设计里,把工具呈现为TypeScript文件树,而不是把所有工具定义平铺塞进上下文;他们报告的代表性工作负载从150,000 token降到2,000 token。
OpenAI 的 tool search文档也建议把大量延迟加载工具组织到namespace或MCP server里,让模型按需搜索和加载。
这些案例指向同一个模式:Agent擅长搜索有名字、有层级、可局部打开的空间。
所以,文件系统形态不等于「把数据库换成磁盘文件」。更准确的说法是:底层数据仍然可以在数据库、对象存储和API里;但对于Agent而言,最好有一个可浏览、可搜索、可快照、可监听的 workspace 视图。
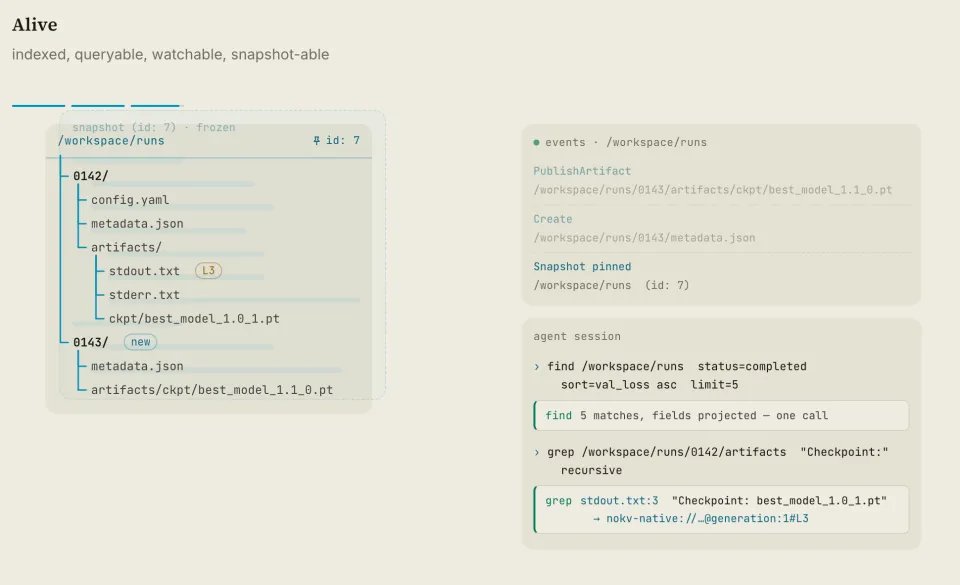
图 1:文件系统形态不是把数据库换成磁盘文件,而是给Agent一个可浏览、可搜索、可快照和可监听的工作空间视图。
由于大模型是个黑盒,所以为了把问题测清楚,我们把变量尽量压到了足够少。
实验语料是一份真实机器学习实验追踪数据:875个训练、采样和评估run,包含元数据、参数、80.6万行指标、artifact、git 状态,以及原始stdout/stderr日志。
这份数据不是手写的玩具demo。它来自Yanex(Yet Another Experiment Tracker,一个轻量、Git-aware / 感知Git状态的开源Python实验追踪系统)的真实运行记录。
据NoKV团队披露,数据由一位曾任MongoDB ML Research负责人的研究者,基于自己的开源项目运行记录以私下合作方式提供。为了避免把私人合作事实包装成公开第三方背书,下面所有可复算的实验结论仍以公开提交的harness(实验框架)、judge(判分器)和telemetry(运行遥测)为准。
同一份数据通过两种接口暴露给 Agent:
sqlite_raw_v1:原生 SQL 接口。Agent 可以发现 schema,可以在物化表上跑只读 SQL,也能读取 blob,并使用行级grep_blob搜索日志。nokv_native_v1:NoKV 的 namespace 接口。Agent 可以使用ls、stat、catalog、find、aggregate、read和递归grep。run 是目录,日志是文件,索引字段可以在一次调用里下推过滤、排序、limit 和投影。
任务设计也尽量贴近日常ML研究人员会问Agent的方式,比如:
找出验证集损失最低的训练run,并报告学习率、batch size、stdout 大小和 git 状态。
找出某个数据集的TabDiff采样run加载了哪个checkpoint,以及模型参数量。
为未完成或被取消的任务整理事故记录,指出stderr中是否出现
KeyboardInterrupt,并给出最后一次出现的行号。
实验设置为:同一个Agent模型gpt-5.4-mini,每个接口、每个任务重复10次,共100次独立运行。
还保证了每次运行都保证Agent是stateless的——新runner进程、只给 system message、接口说明和任务prompt,不把上一次回答串进下一次。
成本按模型公开价格计算,并逐次写入遥测。
主要结果如下:
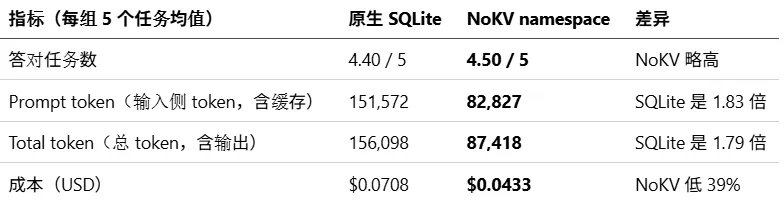
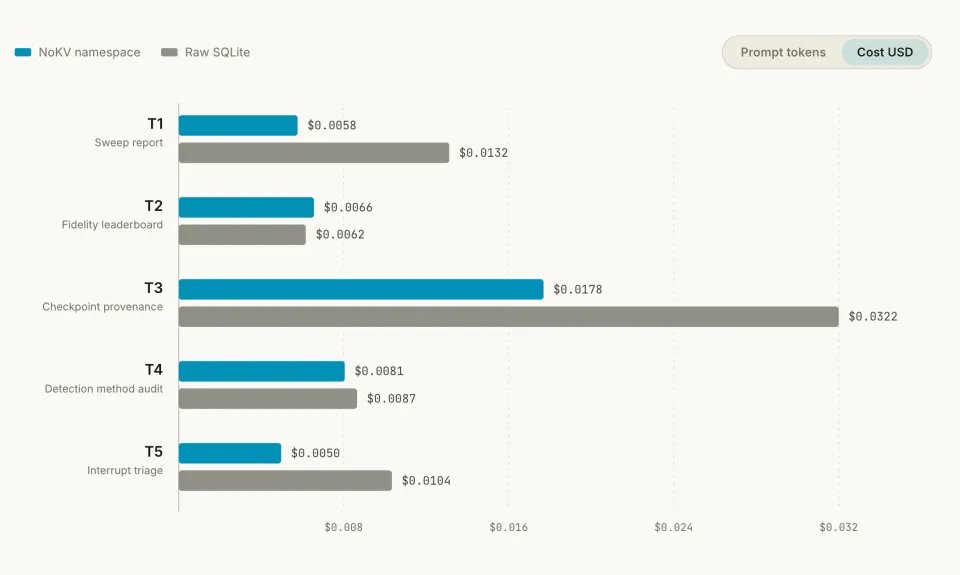
图 2:逐任务成本对比。蓝色是NoKV namespace,灰色是原生SQLite;复合探索任务上的差距最明显。
更有意思的是「复合探索」任务。Agent需要先定位一批run,再从日志里找事实,最后给出可审计的行号证据。
三个复合任务合起来看,namespace版本的prompt token是53,300,而SQL版本是127,450,后者约为前者的2.39倍;成本上,SQL是$0.0558,NoKV是$0.0286,接近2倍差距。
换句话说,Agent不是只需要更多工具,它还需要一种更适合自己「找东西」的工作空间。
这里还有一个不太直观、但对Agent系统很重要的现象:在公开benchmark主表之外,研究人员在内部运行记录里还观察到一个额外信号:用NoKV做interface的后端,模型在执行任务的时候,内部推理 (reasoning token)消耗明显更少。
这件事值得单独解释一下。很多人谈token成本时,只看输入prompt有多长、输出回答有多长。但对具备推理能力的模型来说,每个工具调用轮次里的一部分预算会花在「我现在看到了什么、下一步该查哪里、这些字段之间怎么关联、刚才的结果是否足够回答问题」上。换句话说Agent不只是在读取数据,它还在不断维护一张临时的任务地图。
如果接口迫使Agent先理解复杂schema、猜join路径、拼blob_ref、回忆哪些id对应哪些日志,那么模型的注意力就会被大量消耗在「拼上下文」和「找路」上。它虽然还在工作,但越来越像一个人一边翻十几张表、一边记临时编号、一边担心自己有没有漏掉关键字段。这种状态下,token不是被花在真正的判断上,而是被花在维持工作记忆上。
文件系统形态的接口会减轻这种负担。路径本身就是稳定句柄,目录天然表达范围,grep返回的是带位置的证据,find和aggregate可以把过滤、排序、limit和字段投影下推给系统Agent不需要在脑子里反复重建「数据在哪里」,而是可以顺着路径逐步缩小搜索空间。
所以,NoKV降低的并不只是prompt token和账单。更深一层看,它减少了Agent在每一轮工具调用中维持上下文、修正路线、重新组织线索所消耗的计算资源。更少的「找路成本」,意味着模型有更多有效注意力留给真正的问题:判断、归纳、交叉验证和生成最终答案。
这也解释了为什么研究人员会关心注意力偏移的问题 (attention drifting)。当上下文里塞进太多schema、临时查询结果、无关日志和中间失败尝试的时候,模型容易被早期的错误线索带偏,或者在多轮调用后忘记最初的问题。一个更清晰的workspace接口,本质上是在帮Agent减少这种偏移的几率,让它每一步都看到更少但更相关的信息,并且能用稳定路径回到证据现场。
因此,token efficiency不只是财务指标。它也是一种面向Agent的认知层面上的工程优化:好的接口把复杂性留在系统里,把清晰、局部、可引用的操作面交给Agent。对长链路Agent来说,这往往会反映到更稳定的行为、更低的成本,以及更少的无效推理上。
平均值说明了「差距存在」,但真正重要的是差距从哪里来。
在简单的单发结构化查询上,SQL仍然很强。
例如某个leaderboard类任务,schema一展开,一条SELECT就能完成,SQLite只用了约4.8ktoken,而namespace用了约9.3ktoken。
这个结果并不意外:关系型接口本来就擅长明确的聚合与排序。
真正拉开差距的是复合探索任务。
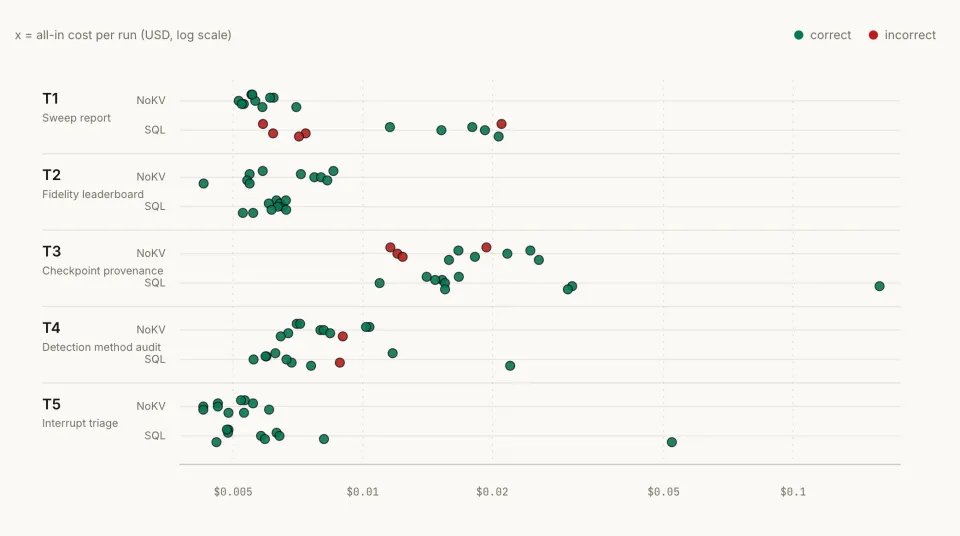
图 3:100次独立运行的成本分布。散点图展示了平均值之外的稳定性问题:某些SQL运行会拖出更长尾的成本,错误运行仍然照样计费。
任务要求Agent找出已完成训练run中val_loss最低的5个,并报告学习率、batch size、stdout大小和git状态。
在namespace接口上,Agent 先用一次 catalog 发现字段,再用一次 find 把过滤、排序、limit 和字段投影一起 push down给系统,答案 100% 正确,约 7.9k token。
在SQL接口上,Agent需要在80.6万行指标表上做每个 run 的最小值聚合,再 join 参数、artifact和git状态。模型有一半次数把查询写错,而且错得并不明显;即便失败,token仍然照样计费,约23.6k token。
这个案例说明:很多Agent错误不是「模型不会思考」,而是接口要求它在找答案前先跨过一堆间接层。SQL把信息组织得很严谨,但对Agent来说,严谨不等于低成本。
任务要求找出某个数据集所有TabDiff采样run加载的checkpoint文件,以及模型参数量。这些事实只存在于stdout日志中。
在namespace接口上,一次递归grep就能找到相关run目录。目录路径本身就是后续操作的 cohort handle,随后在这些目录里继续限定范围搜索Checkpoint: 和 Model parameters:行即可。
在SQL接口上,即使我们也给了grep_blob,Agent 然要先解开params、artifact、blob_ref之间的间接关系,再对多个 blob 分别搜索。很多时候,它会把整段stdout拉进上下文里再处理,答案可以对,但 token 成本很高。
这里也有一个需要诚实说明的点:namespace 接口在这个任务上10次里有4次失手,正确率是60%,SQL是100%。但按「每个正确答案的成本」计算,namespace仍然更便宜:$0.0297对$0.0322。
这不是为了证明namespace永远赢,而是为了说明接口选择会改变成本结构。SQL在这个任务上更稳;NoKV在同一任务上的平均token和平均成本更低,但还需要在可靠性上继续工程化。
任务要求列出所有非completed run的状态、stderr大小、是否包含KeyboardInterrupt,以及最后一次出现的行号。
namespace 的优势很直接:一次find拿到cohort和stderr大小,再用限定目录的grep返回带行号的匹配行。行号就是天然的审计证据。
SQL也能答对,但要贵得多。原因是行号不是关系型投影里的原生概念。要在 SQL 世界里得到「最后一次出现在哪一行」,Agent要做额外的字符串和换行计算,或者依赖额外工具。
把三个案例合在一起看,namespace赢在四个地方:
路径就是句柄。 找到一个run和读取它的日志,发生在同一个地址空间里。
搜索可以递归,也可以限定范围。 同一个
grep既能全局发现,也能在某个目录内精确提取。行号天然适合引用。 审计、debug(调试)、事故分析都需要「证据在哪一行」。
下推减少对话轮数。 过滤、排序、limit、投影放进一次调用,就少一次上下文回灌和重新计费。
不是「文件系统替代数据库」,而是给 Agent 做一层工作空间
这也是最容易被误解的地方。
不是说数据库没用了,也不是说所有数据都应该搬进真实文件系统。数据库仍然应该负责可靠性、结构化查询、事务和持久化;对象存储仍然应该负责大文件、checkpoint、日志和二进制内容;业务API仍然应该负责权限和领域逻辑。
真正的问题是:对Agent暴露的后端视图形态,是否需要重新设计?
对人类工程师来说,SQL、对象存储key、日志blob、临时脚本、Excel、仪表盘都能用,因为我们能在脑子里做跨系统导航。但 Agent 的上下文窗口和工具调用都有成本。每次让它先猜schema、再找id、再拼blob_ref、再读日志,都是把预算花在「找路」上,而不是「回答问题」上。
更合理的架构是分两层:
底层: 继续使用数据库、对象存储和API。
上层: 维护元数据、路径、版本、权限、索引和引用关系。并且给 Agent 提供一个友好的类 POSIX 语义的 workspace以提供比如:路径寻址、目录列举、按需读取、局部搜索、权限边界、原子发布和可审计引用等功能
NoKV想做的就是上层:提供一个 Agent(或者说模型) 更偏爱的统一命名空间和元数据控制层。
未来应用:产物密集型 (artifact-heavy) 智能体系统都会遇到这个问题
第一个已经很明显的应用场景,是实验追踪和观测,但它不是唯一的场景。一般来讲,只要一个智能体系统高度依赖大量文件、日志、报告、模型、合同、图片、音视频、checkpoint 等外部产物,就会遇到类似问题。可以把这类系统称为 artifact-heavy(产物密集型)Agentic 系统。
今天的训练、评测和推理系统会产生大量run、trace、日志、模型checkpoint、指标和配置。作为人的我们会问:「哪组配置最好?」「这批失败任务为什么取消?」「这个采样run到底加载了哪个模型?」这些问题往往不是一条SQL能解决的,而是要在结构化指标、非结构化日志和 artifact 元数据之间来回探索。
法律咨询类代理系统是另一个很直观的例子。用户把合同、判例、尽调材料和邮件附件丢进去,让 Agent 做摘要、问答、风险提示和后续行动建议。真正让系统变复杂的,不只是大模型本身,而是这些文件对象背后的元数据:来源、版本、权限、引用关系、解析状态、向量索引状态、审计记录、用户批注、任务输出等。如果这些元数据散落在对象存储key、向量数据库、业务数据库、临时缓存和工作流组件里,没有一个统一的管理层,Agent每次工作都要重新拼接上下文,徒增心智负担和token cost。
从 token efficiency 的角度看,这是一种很差的接口选择:Agent的预算被花在「我该去哪找这份文件、哪个版本才是当前版本、这个摘要对应哪段原文」上,而不是花在法律分析、实验判断或业务决策上。
类似的场景还包括:
数据分析Agent:需要在notebook、CSV、数据库结果、图表和报告之间来回引用。
多媒体Agent:需要管理原图、缩略图、转写文本、时间戳、向量表示和版本。
研发Agent:需要跨 issue、PR、日志、CI 结果、构建产物和部署记录定位问题。
多Agent协作系统:不同Agent需要共享中间产物、锁定版本、监听更新、回滚错误状态。
如果这些系统没有统一workspace,Agent就会不断重复「重新发现世界」的过程。反过来,如果系统提供一个稳定、可搜索、可快照、可审计的namespace,Agent就能把更多token花在推理和产出上。
这就是研究人员认为「文件系统语义」会重新变重要的原因_LLM 被训练得非常擅长在这种形态的空间里工作。
如果越来越多的人开始意识到token是一种新型的计算单元,那么接口形态就是这个计算成本结构的一部分。在实际业务场景中,Agent在执行任务的时候,被有限分配的token和注意力应该更多花在推理和执行任务上,而不是用在定位和拼接上下文。
文中涉及的公开事实均按公开资料核查:
NoKV 项目状态:CNCF Cloud Native Landscape中NoKV条目位于Runtime / Cloud Native Storage,并标注second_path为AI Native Infra / Storage;NoKV GitHub README 也说明其被列入CNCF Landscape与DBDB.io,同时说明DBDB是历史数据库条目、当前NoKV是Rust文件系统产品线。
DBDB 条目:dbdb.io将NoKV描述为Go-native log-structured key-value DBMS。本文据此写作「早期自研存储引擎的历史条目被收录」,不把它表述为当前 Rust 主线产品的完整描述。
benchmark 数字:875个Yanex run、80.6万行 metric、100次stateless run、
gpt-5.4-mini、5个任务、45%token 降低、39%成本降低等,均来自NoKV benchmark报告和已提交运行遥测。外部案例:Letta、Anthropic、OpenAI tool search、Linux Foundation Tokenomicon等,仅用于解释「按需发现、延迟加载、命名空间组织」这一接口趋势。
实验数据来源:Yanex是公开可核验的轻量Git-aware Python实验追踪项目;「数据由一位曾任MongoDB ML Research负责人的研究者私下提供」属于NoKV团队披露,非公开第三方 benchmark站点声明。
参考资料:
https://nokv.io/blog/agents-want-filesystems
编辑:LRST