秒杀同行!Kimi开源全新音频基础模型,横扫十多项基准测试,总体性能第一
编辑:Sia、杨文
六边形战士来了。
今天,kimi 又发布了新的开源项目 —— 一个全新的通用音频基础模型 Kimi-Audio,支持语音识别、音频理解、音频转文本、语音对话等多种任务,在十多个音频基准测试中实现了最先进的 (SOTA) 性能。
结果显示,Kimi-Audio 总体性能排名第一,几乎没有明显短板。
例如在 LibriSpeech ASR 测试上,Kimi-Audio 的 WER 仅 1.28%,显著优于其他模型。VocalSound 测试上,Kimi 达 94.85%,接近满分 。MMAU 任务中,Kimi-Audio 摘得两项最高分;VoiceBench 设计评测对话助手的语音理解能力,Kimi-Audio 在所有子任务中得分最高,包括一项满分。

研发人员开发了评估工具包,可在多个基准任务上对音频 LLM 进行公平、全面评估 ,五款音频模型(Kimi-Audio、Qwen2-Audio、Baichuan-Audio、StepAudio、Qwen2.5-Omni)在各类音频基准测试中的表现对比。紫线(Kimi-Audio)基本覆盖最外层,表明其综合表现最佳。
目前,模型代码、模型检查点以及评估工具包已经在 Github 上开源。
项目链接:https://github.com/MoonshotAI/Kimi-Audio
新颖的架构设计
为实现 SOTA 级别的通用音频建模, Kimi-Audio 采用了集成式架构设计,包括三个核心组件 —— 音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
这一架构使 Kimi-Audio 能够在单一模型框架下,流畅地处理从语音识别、理解到语音对话等多种音频语言任务。
 Kimi-Audio 由三个主要组件组成:音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
Kimi-Audio 由三个主要组件组成:音频分词器(Audio Tokenizer)、音频大模型(Audio LLM)、音频去分词器(Audio Detokenizer)。
具体而言,音频分词器(Audio Tokenizer)负责将输入音频转化为通过矢量量化(vector quantization)得到的离散语义 token,帧率为 12.5Hz。同时,音频分词器还提取连续的声学向量,以增强感知能力。
这种结合方式使模型既具有语义上的压缩表示,又保留了丰富的声学细节,从而为多种音频任务提供了坚实的表示基础。
音频大模型(Audio LLM)是系统的核心,负责生成语义 token 以及文本 token,以提升生成能力。其架构基于共享 Transformer 层,能够处理多模态输入,并在后期分支为专门用于文本和音频生成的两个并行输出头。
音频去分词器(Audio Detokenizer)使用流匹配(flow matching)方法,将音频大模型预测出的离散语义 token 转化为连贯的音频波形,生成高质量、具有表现力的语音。
数据建构与训练方法
除了新颖的模型架构,构建 SOTA 模型的核心工作还包括数据建构和训练方法。
为实现 SOTA 级别的通用音频建模,Kimi-Audio 在预训练阶段使用了约 1300 万小时覆盖多语言、音乐、环境声等多种场景的音频数据,并搭建了一条自动处理 “流水线” 生成高质量长音频 - 文本对。
预训练后,模型进行了监督微调(SFT),数据涵盖音频理解、语音对话和音频转文本聊天三大类任务,进一步提升了指令跟随和音频生成能力。

Kimi-Audio 预训练数据处理流程的直观展示。简单来说,就是把原始音频一步步净化、切分、整理,变成干净、有结构、有标注的训练数据。
在训练方法上,为实现强大的音频理解与生成能力,同时保持模型的知识容量与智能水平,研发人员以预训练语言模型为初始化,设计了三个类别的预训练任务:
仅文本和仅音频预训练,用于分别学习两个模态的知识;音频到文本的映射,促进模态转换能力;音频文本交错训练,进一步弥合模态间的鸿沟。
在监督微调阶段,他们设计了一套训练配方,以提升训练效率与任务泛化能力。
考虑到下游任务的多样性,研究者没有设置特殊的任务切换操作,而是为每个任务使用自然语言作为指令;对于指令,他们构建了音频和文本版本(即音频由 Kimi-TTS 在零样本方式下基于文本生成),并在训练期间随机选择一种;为了增强遵循指令能力的鲁棒性,他们使用大语言模型为 ASR 任务构建了 200 条指令,为其他任务构建了 30 条指令,并为每个训练样本随机选择一条。他们构建了大约 30 万小时的数据用于监督式微调。
如表 1 和表 2 所示,他们基于全面的消融实验,在每个数据源上对 Kimi-Audio 进行了 2-4 个训练周期的微调,使用 AdamW 优化器,学习率从 1e⁻⁵ 到 1e⁻⁶ 进行余弦衰减,使用 10% 的 token 进行学习率预热。
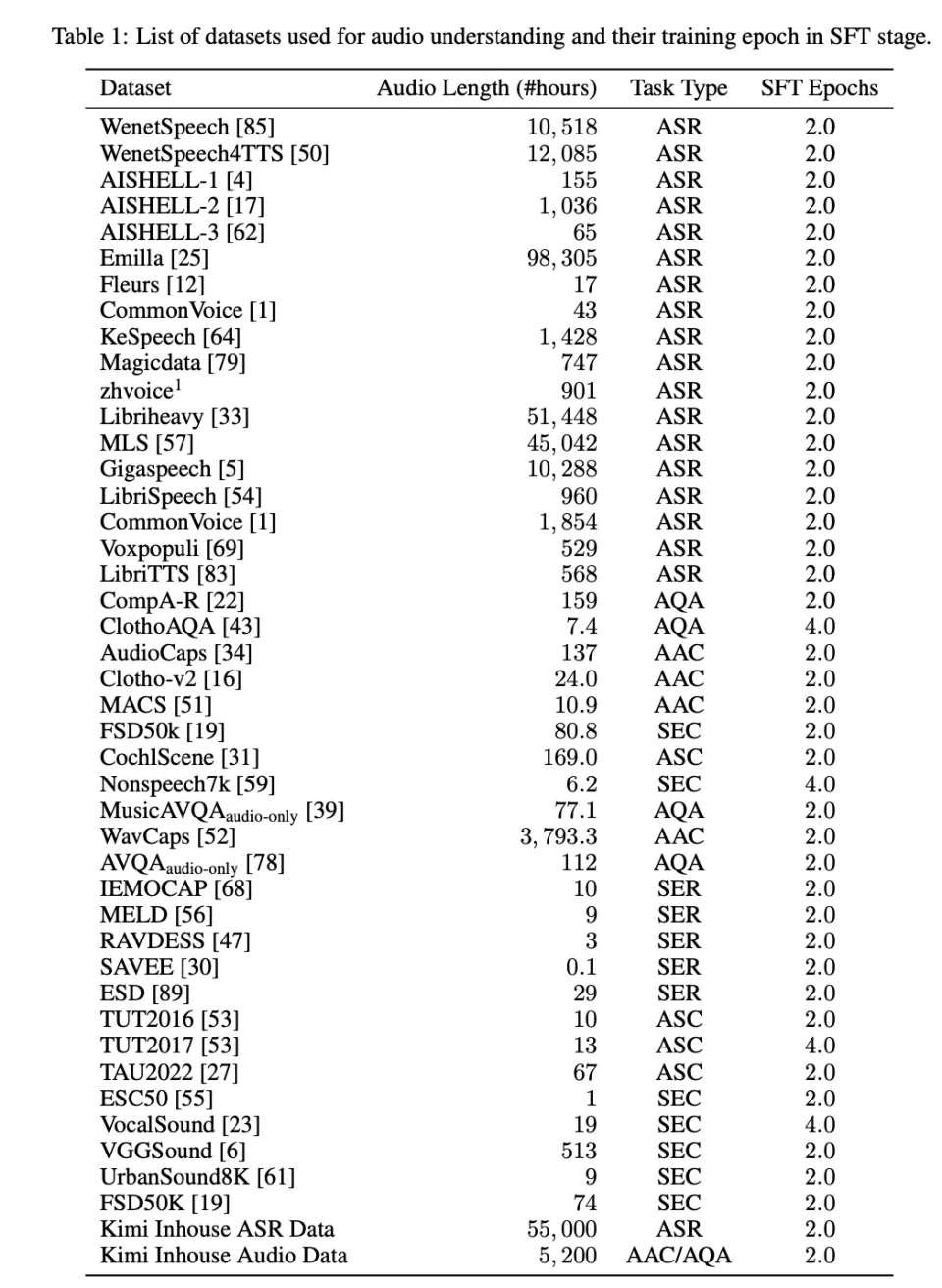

此外,他们还分三个阶段训练音频解码器。首先,使用预训练数据中的大约 100 万小时的音频,对流匹配模型和声码器进行预训练,以学习具有多样化音色、语调和质量的音频。其次,采用分块微调策略,在相同的预训练数据上将动态块大小调整为 0.5 秒到 3 秒 。最后,在 Kimi-Audio 说话者提供的高质量单声道录音数据上进行微调。
评估结果
研究者基于评估工具包,详细评估了 Kimi-Audio 在一系列音频处理任务中的表现,包括自动语音识别(ASR)、音频理解、音频转文本聊天和语音对话。他们使用已建立的基准测试和内部测试集,将 Kimi-Audio 与其他音频基础模型(Qwen2-Audio 、Baichuan-Audio、Step-Audio、GLM4-Voice 和 Qwen2.5-Omini )进行了比较。
自动语音识别
研究者对 Kimi-Audio 的自动语音识别(ASR)能力进行了评估,涵盖了多种语言和声学条件的多样化数据集。如表 4 所示,Kimi-Audio 在这些数据集上持续展现出比以往模型更优越的性能。他们报告了这些数据集上的词错误率(WER),其中较低的值表示更好的性能。

值得注意的是,Kimi-Audio 在广泛使用的 LibriSpeech 基准测试中取得了最佳结果,在 test-clean 上达到了 1.28 的错误率,在 test-other 上达到了 2.42,显著超越了像 Qwen2-Audio-base 和 Qwen2.5-Omni 这样的模型。在普通话 ASR 基准测试中,Kimi-Audio 在 AISHELL-1(0.60)和 AISHELL-2 ios(2.56)上创下了最先进的结果。此外,它在具有挑战性的 WenetSpeech 数据集上表现出色,在 test-meeting 和 test-net 上均取得了最低的错误率。最后,研究者在内部的 Kimi-ASR 测试集上的评估确认了该模型的鲁棒性。这些结果表明,Kimi-Audio 在不同领域和语言中均具有强大的 ASR 能力。
音频理解
除了语音识别外,研究者还评估了 Kimi-Audio 理解包括音乐、声音事件和语音在内的各种音频信号的能力。表 5 总结了在各种音频理解基准测试上的性能,通常较高的分数表示更好的性能。

在 MMAU 基准测试中,Kimi-Audio 在声音类别(73.27)和语音类别(60.66)上展现出卓越的理解能力。同样,在 MELD 语音情感理解任务上,它也以 59.13 的得分超越了其他模型。Kimi-Audio 在涉及非语音声音分类(VocalSound 和 Nonspeech7k )以及声学场景分类(TUT2017 和 CochlScene)的任务中也处于领先地位。这些结果突显了 Kimi-Audio 在解读复杂声学信息方面的高级能力,超越了简单的语音识别范畴。
音频到文本聊天
研究者使用 OpenAudioBench 和 VoiceBench 基准测试 评估了 Kimi-Audio 基于音频输入进行文本对话的能力。这些基准测试评估了诸如指令遵循、问答和推理等各个方面。性能指标因基准测试而异,较高的分数表示更好的对话能力。结果如表 6 所示。
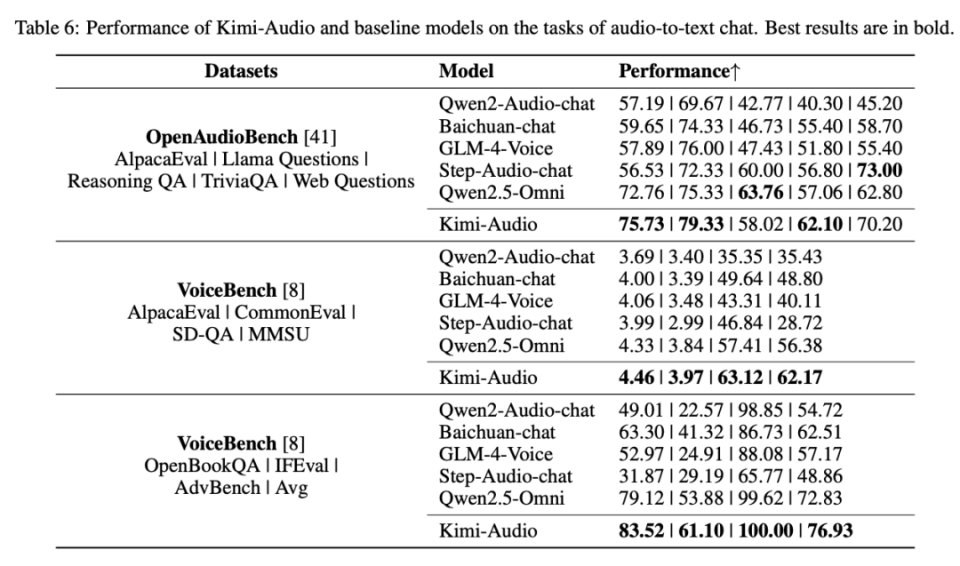
在 OpenAudioBench 上,Kimi-Audio 在多个子任务上实现了最先进的性能,包括 AlpacaEval、Llama Questions 和 TriviaQA,并在 Reasoning QA 和 Web Questions 上取得了极具竞争力的性能。VoiceBench 评估进一步证实了 Kimi-Audio 的优势。它在 AlpacaEval(4.46)、CommonEval(3.97)、SD-QA(63.12)、MMSU(62.17)、OpenBookQA(83.52)、Advbench(100.00)和 IFEval(61.10)上均持续超越所有对比模型。Kimi-Audio 在这些全面的基准测试中的整体表现证明了其在基于音频的对话和复杂推理任务中的卓越能力。
语音对话
最后,他们基于多维度的主观评估,评估了 Kimi-Audio 的端到端语音对话能力。如表 7 所示,Kimi-Audio 与 GPT-4o 和 GLM-4-Voice 等模型在人类评分(1-5 分量表,分数越高越好)的基础上进行了比较。

除去 GPT-4o,Kimi-Audio 在情感控制、同理心和速度控制方面均取得了最高分。尽管 GLM-4-Voice 在口音控制方面表现略佳,但 Kimi-Audio 的整体平均得分仍高达 3.90,超过了 Step-Audio-chat(3.33)、GPT-4o-mini(3.45)和 GLM-4-Voice(3.65),并与 GPT-4o(4.06)仅存在微小差距。总体而言,评估结果表明,Kimi-Audio 在生成富有表现力和可控性的语音方面表现出色。
