Harmon:协调视觉表征,统一多模态理解和生成(模型已开源)
吴思泽,南洋理工大学MMLab@NTU四年级博士生,导师是Chen Change Loy,研究方向为基于多模态模型的视觉理解和生成、开放世界的检测分割等,在ICCV/CVPR/ICLR等顶级学术会议上发表过多篇论文。

论文标题:Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
论文链接: https://arxiv.org/abs/2503.21979
代码地址: https://github.com/wusize/Harmon
项目主页:https://wusize.github.io/projects/Harmon
在线 Demo: https://huggingface.co/spaces/wusize/Harmon
1. 背景:统一多模态理解生成
GPT-4o 生图功能的出现揭示了统一理解与生成模型的巨大潜力,然而如何在同一个框架内协调图像理解与生成这两种不同粒度的任务,是一个巨大的挑战。从视觉表征的维度看,现有的统一模型通常采用如下三种范式:
(1)理解生成统一使用 CLIP/SigLIP 表征,并使用 Diffusion Model 将视觉表征解码成图像,如 EMU2、ILLUME 等。此类方案的图像生成过程缺少与 LLM 的交互,本质上是将 LLM 输出的 embeddings 作为生成 condition。
(2)理解生成统一使用 VQGAN/VAE 表征,如 Transfusion、Show-o、ViLA-u 等,由于 VQGAN/VAE 用于图像压缩,主要表征纹理等细节,缺乏视觉语义的建模,此类方法通常理解能力偏弱。
(3)解耦理解生成表征,理解任务使用编码高层语义的 CLIP/SigLIP,生成任务使用 VQGAN,如 Janus、UniFluid 等。
2. 协调理解和生成的视觉表征
不同于 Janus 割裂理解和生成的视觉编码,Harmon 探索在统一的视觉表征上协调图像理解和生成。
(1)MAR 的启发
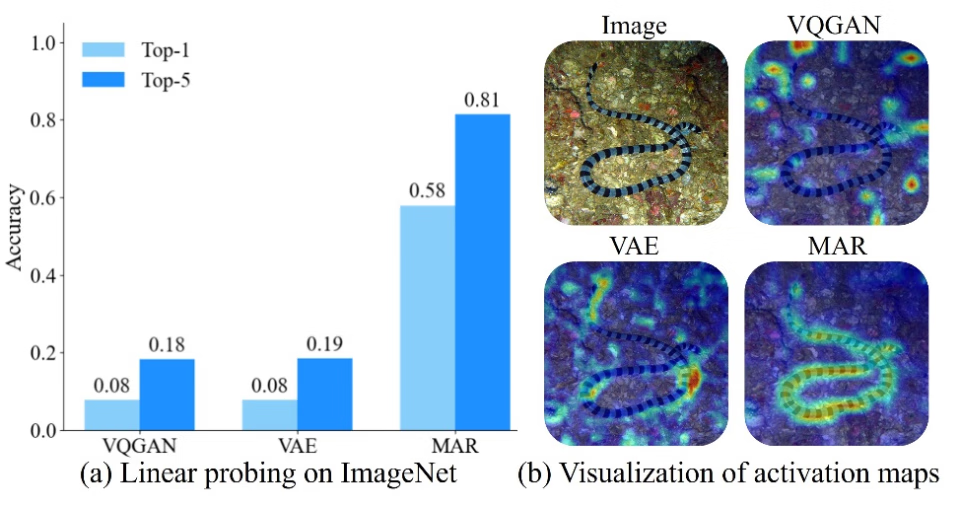
图一:Linear Probing 和特征图激活
MAR 作为一种基于图像掩码建模的生成范式,沿袭了表征学习 MAE 的 Encoder-Decoder 框架,Harmon 的作者们发现 MAR Encoder 在图像生成训练中,同时学会对视觉语义的建模。如图一所示,MAR 的 Linear Probing 结果远超 VQGAN、VAE,同时对视觉语义概念有更精确的响应。
(2)Harmon:理解生成共享 MAR Encoder
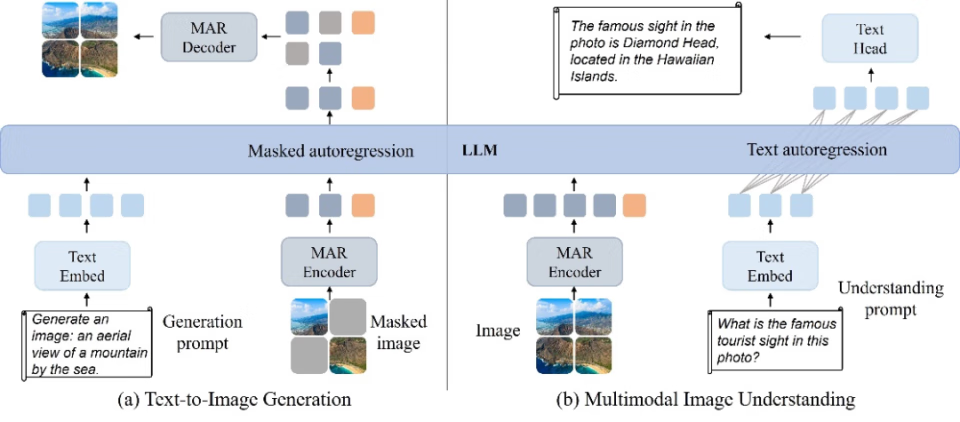
图二: Harmon 框架图
Harmon 框架如图所示,通过共享 MAR Encoder 同时促进理解和生成:
i)图像理解:MAR Encoder 处理完整图像,LLM 根据图像内容和用户指令输出文本
ii) 图像生成:沿用 MAR 的掩码建模范式,MAR Encoder 处理可见(已经生成)的图像内容,LLM 中实现模态交互,MAR Decoder 预测剩余的图像内容。
(3)Harmon 的三阶段训练
i)模态对齐:第一阶段对齐 MAR 与 LLM,冻结 LLM 参数,仅训练 MAR Encoder 和 Decoder
ii)联合训练:在大规模图文数据上联合训练,并更新所有模型参数
iii)高质量微调:最后一个阶段使用高质量数据微调,并将图片分辨率从 256 提升至 512
3. 实验结果:理解生成两开花
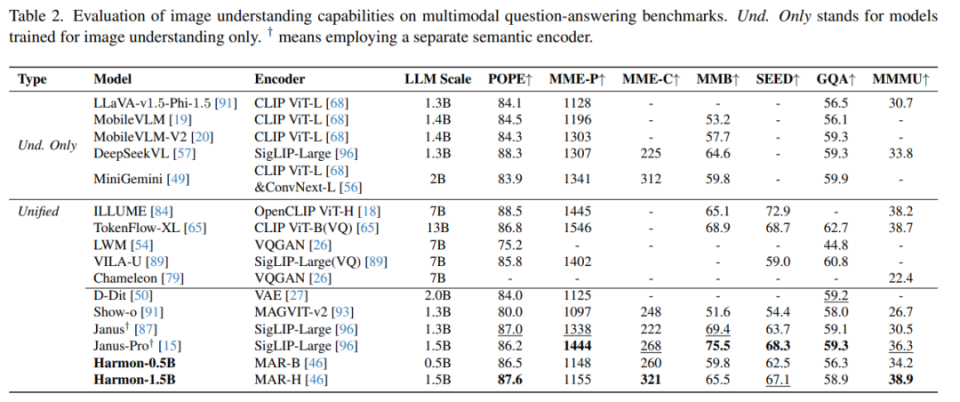
(1)Harmon 在多模态理解基准上,取得接近 Janus-Pro 的效果
(2)在文生图基准上,Harmon 优势显著
i) 在图像生成美学基准如 MJHQ-30K 上,Harmon 大幅领先同类的统一模型,并接近或超过文生图专家模型如 SDXL。

ii) 在衡量指令跟随和一致性的 GenEval 基准上,Harmon 大幅领先所有专家模型和统一模型。
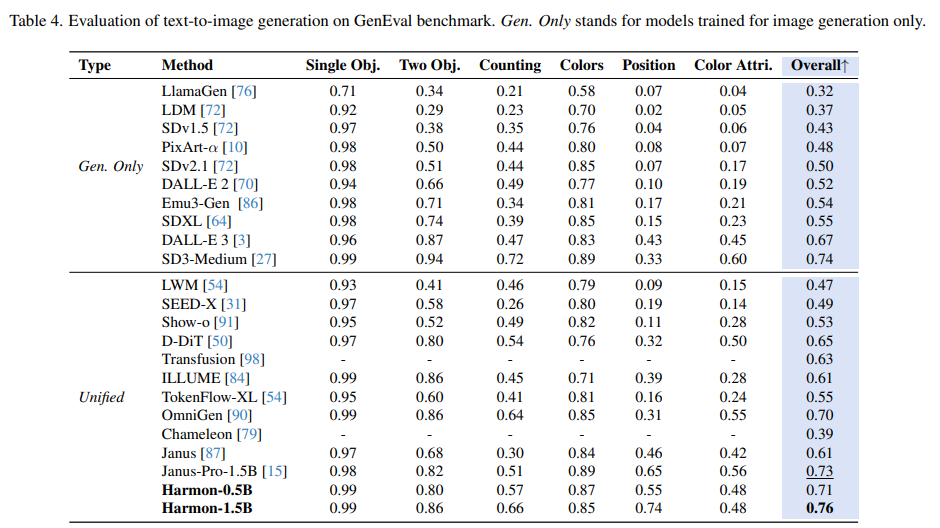
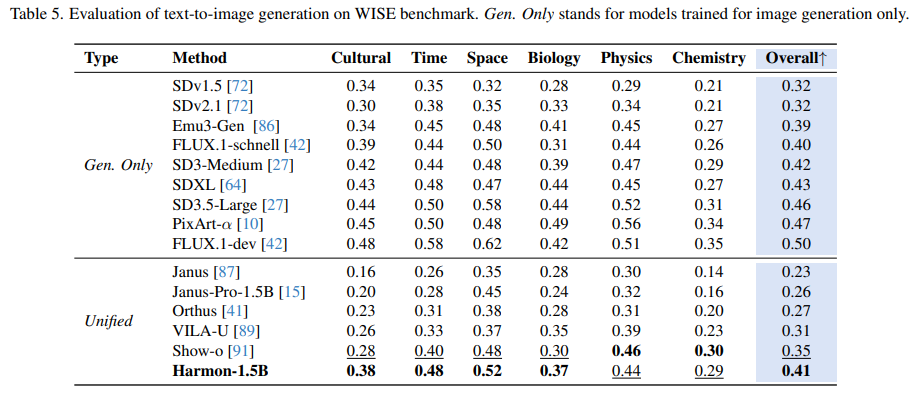
iii) 同时,Harmon 能在文生图中更好地利用多模态大模型的世界知识,在 WISE benchmark 上远超 Janus 等统一模型。
(3) 协同生成理解
实验中,相较于解耦理解生成地视觉编码器(图三d),Harmon 的协同视觉表征表征使理解 loss 能显著提升生成指标(图三b),显示出统一视觉表征对于生成理解协同进化的巨大潜力。
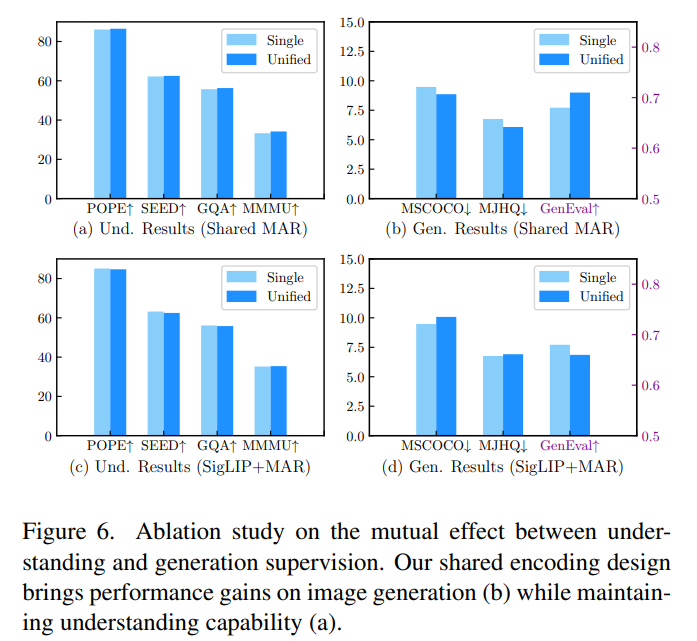
图三:理解生成的相互作用
4.可视化效果
