85倍速度碾压:苹果开源FastVLM,能在iphone直接运行的视觉语言模型
作者:+0、刘欣
FastVLM—— 让苹果手机拥有极速视觉理解能力
当你用苹果手机随手拍图问 AI:「这是什么?」,背后的 FastVLM 模型正在默默解码。
最近,苹果开源了一个能在 iPhone 上直接运行的高效视觉语言模型 ——FastVLM(Fast Vision Language Model)。

代码链接:https://github.com/apple/ml-fastvlm
代码仓库中还包括一个基于 MLX 框架的 iOS/macOS 演示应用,优化了在苹果设备上的运行性能。
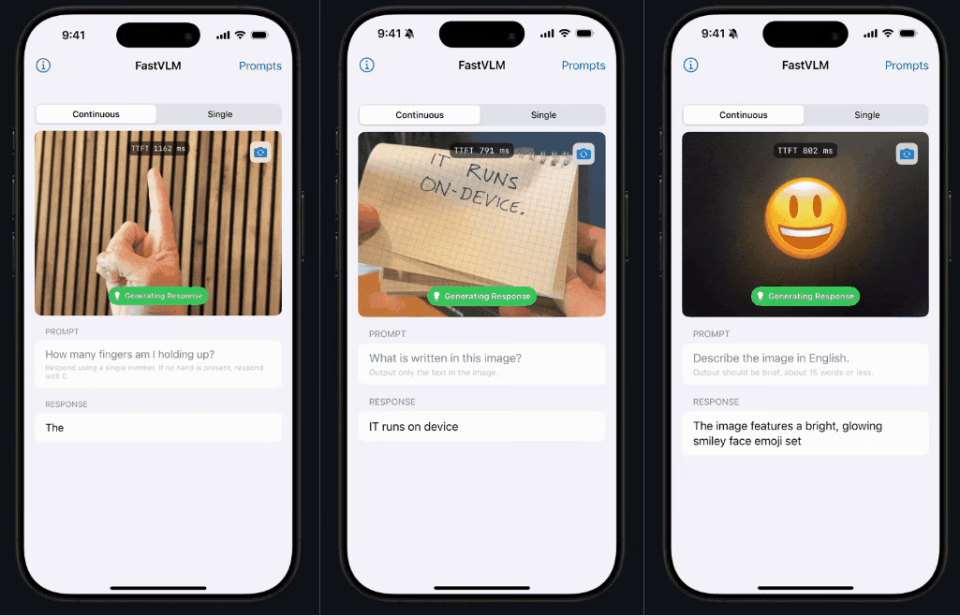
看这个 demo,反应速度是不是反应非常「Fast」!这就是 FastVLM 的独特之处。
相较于传统模型,FastVLM 模型专门注重于解决体积、速度这两大问题,速度快到相对同类模型,首个 token 输出速度提升 85 倍。
该模型引入了一种新型混合视觉编码器 FastViTHD,融合了卷积层和 Transformer 模块,配合多尺度池化和下采样技术,把图片处理所需的「视觉 token」数量砍到极低 —— 比传统 ViT 少 16 倍,比 FastViT 少 4 倍。它以卓越的速度和兼容性,极大地提升了 AI 与图像之间的用户体验能力。
FastVLM 模型不仅可以用于给模型自动生成陈述、回答「这张图是什么」的问题、分析图中的数据或对象等途径,还兼容主流 LLM 并轻松适配 iOS/Mac 生态,特别适合落地在边缘设备、端侧 AI 应用和实时图文任务场景。
目前,FastVLM 模型主要推出 0.5B、1.5B、7B 三个不同参数量级的版本,每个版本均有 stage2 和 stage3 两阶段微调权重,用户可以根据自身需求灵活选择。
苹果团队在发布的论文中详细阐述了更加具体的技术细节和优化路径。

论文标题: FastVLM: Efficient Vision Encoding for Vision Language Models
论文地址:https://www.arxiv.org/abs/2412.13303
研究背景
视觉语言模型(Vision-Language Models, VLMs)是一类能够同时理解图像和文本信息的多模态模型。VLMs 通常通过一个投影层(也称连接模块)将来自预训练视觉骨干网络的视觉 token 输入到一个预训练的 LLM 中。
此前的研究已经探讨了视觉骨干网络、适配器(adapter)以及通常为解码器结构的 LLM 这三大组件的训练和微调策略。
已有多项研究指出,图像分辨率是影响 VLM 性能的关键因素,尤其在面对文本密集或图表密集的数据时表现尤为明显。然而,提升图像分辨率也带来了若干挑战。
首先,许多预训练视觉编码器在设计时并不支持高分辨率图像输入,因为这会显著降低预训练效率。
为了解决这一问题,一种方法是持续对视觉骨干进行预训练,使其适应高分辨率图像;另一种则是采用图像分块策略(tiling strategies),如 Sphinx、S2 和 AnyRes,将图像划分为多个子区域,并由视觉骨干分别处理各个子区域。
这类方法特别适用于基于视觉 Transformer(ViT)的模型架构,因为 ViT 通常不支持可变输入分辨率。
另一个挑战来自于高分辨率推理时的运行时计算成本。无论是单次高分辨率推理,还是在较低分辨率下多次推理(即采用切片策略),在生成视觉 token 时都存在显著延迟。
此外,高分辨率图像本身生成的 token 数量更多,这会进一步增加 LLM 的预填充时间(prefilling time,即 LLM 对包括视觉 token 在内的所有上下文 token 进行前向计算的时间),从而整体拉长初始输出时间(time-to-first-token, TTFT),即视觉编码器延迟与语言模型前填充时间之和。
本研究以 VLM 的设备端部署为动力,从运行时效率的角度出发,对其设计和训练进行系统性研究。我们重点研究图像分辨率提升对优化空间的影响,目标是改进精度 - 延迟之间的权衡,其中延迟包括视觉编码器的推理时间和 LLM 的前填充时间。
研究者通过在不同的 LLM 规模与图像分辨率下的大量实验证明,在特定的视觉骨干条件下,可以建立一条帕累托最优曲线(Pareto optimal curve),展示在限定运行时间预算(TTFT)内,不同的图像分辨率和语言模型规模组合能达到的最佳准确率。
研究者首先探索了一种混合卷积 - Transformer 架构 FastViT(预训练于 MobileCLIP)作为 VLM 视觉骨干的潜力。
实验证明,该混合骨干在生成视觉 token 方面的速度是标准 ViT 模型的四倍以上,同时基于多尺度视觉特征还实现了更高的整体 VLM 准确性。然而,若目标主要是高分辨率 VLM(而非如 MobileCLIP 那样仅关注嵌入生成),则该架构仍有进一步优化空间。
为此,研究者提出了一种新型混合视觉编码器 FastViTHD,其专为在处理高分辨率图像时提升 VLM 效率而设计,并以此为骨干网络,通过视觉指令微调得到 FastVLM。
在不同输入图像分辨率和语言模型规模下,FastVLM 在准确率与延迟的权衡上均显著优于基于 ViT、卷积编码器及我们先前提出的混合结构 FastViT 的 VLM 方法。
特别地,相比于运行在最高分辨率(1152×1152)的 LLaVa-OneVision,FastVLM 在相同 0.5B LLM 条件下达到了可比的性能,同时拥有快 85 倍的 TTFT 和小 3.4 倍的视觉编码器规模。
模型架构
研究者首先探讨了将 FastViT 混合视觉编码器应用于 VLM 中的潜力,随后提出若干架构优化策略以提升 VLM 任务的整体表现。
在此基础上,研究者提出 FastViT-HD—— 一款专为高分辨率视觉 - 语言处理任务量身定制的创新型混合视觉编码器,兼具高效率与高性能特点。
通过大量消融实验,研究者全面验证了 FastViT-HD 在多种大型语言模型 (LLM) 架构和不同图像分辨率条件下,相比原始 FastViT 及现有方法所展现的显著性能优势。
如图 2 所示,展示了 FastVLM 与 FastViT-HD 的整体架构。所有实验均使用与 LLaVA-1.5 相同的训练配置,并采用 Vicuna-7B 作为语言解码器,除非特别说明。

FastViT 作为 VLM 图像编码器
典型的 VLM (如 LLaVA)包含三个核心组件:图像编码器(image encoder)、视觉 - 语言映射模块(vision-language projector)以及大型语言模型(LLM)。
VLM 系统的性能及运行效率高度依赖其视觉主干网络(vision backbone)。在高分辨率下编码图像对于在多种 VLM 基准任务中取得良好表现尤其关键,特别是在文本密集型任务上。因此,支持可扩展分辨率的视觉编码器对 VLM 尤为重要。
研究者发现,混合视觉编码器(由卷积层与 Transformer 块组成)是 VLM 极为理想的选择,其卷积部分支持原生分辨率缩放,而 Transformer 模块则进一步提炼出高质量的视觉 token 以供 LLM 使用。
实验使用了一个在 CLIP 上预训练过的混合视觉编码器 ——MobileCLIP 提出的 MCi2 编码器。该编码器拥有 35.7M 参数,在 DataCompDR 数据集上预训练,架构基于 FastViT。本文后续均将该编码器简称为「FastViT」。
然而,正如表 1 所示,若仅在其 CLIP 预训练分辨率(256×256)下使用 FastViT,其 VLM 表现并不理想。

FastViT 的主要优势在于其图像分辨率缩放所具有的高效性 —— 相比采用 patch size 为 14 的 ViT 架构,其生成的 token 数量减少了 5.2 倍。
这样的 token 大幅裁剪显著提升了 VLM 的运行效率,因为 Transformer 解码器的预填充时间和首个 token 的输出时间(time-to-first-token)大大降低。
当将 FastViT 输入分辨率扩展至 768×768 时,其生成的视觉 token 数量与 ViT-L/14 在 336×336 分辨率下基本持平,但在多个 VLM 基准测试中取得了更优的性能。
这种性能差距在文本密集型任务上尤为明显,例如 TextVQA 和 DocVQA,即使两种架构生成的 visual token 数量相同。
此外,即便在高分辨率下 token 数量持平,FastViT 凭借其高效的卷积模块,整体图像编码时间依然更短。
1、多尺度特征(Multi-Scale Features)
典型的卷积或混合架构通常将计算过程划分为 4 个阶段,每个阶段之间包含一个下采样操作。VLM 系统一般使用倒数第二层输出的特征,但网络前几层所提取的信息往往具有不同的粒度。结合多个尺度的特征不仅可提升模型表达能力,也能补强倒数第二层中的高层语义信息,这一设计在目标检测中尤为常见。
研究者在两个设计方案之间进行了消融对比,用于从不同阶段汇聚特征:均值池化(AvgPooling)与二维深度可分离卷积(2D depthwise convolution)。
如表 2 所示,采用深度可分卷积在性能上更具优势。除多尺度特征外,研究者还在连接器设计(connector design)上进行了多种尝试(详见补充材料)。这些结构性模型改进对于使用分层主干的架构(如 ConvNeXt 与 FastViT)特别有效。

FastViT-HD:面向 VLM 的高分辨率图像编码器
在引入上述改进后,FastViT 在参数量比 ViT-L/14 小 8.7 倍的情况下已具备良好性能。然而,已有研究表明,扩大图像编码器的规模有助于增强其泛化能力。
混合架构中,常见的做法是同时扩展第 3、4 阶段中的自注意力层数量和宽度(如 ViTamin 所采用的方式),但我们发现在 FastViT 上简单扩展这些层数并非最优方案(详见图 3),甚至在速度上不如 ConvNeXT-L。

为避免额外的自注意力层带来的性能负担,研究者在结构中加入一个额外阶段,并在其前添加了下采样层。在该结构中,自注意力层所处理的特征图尺寸已经被以 1/32 比例降采样(相比 ViTamin 等常见混合模型的 1/16),最深的 MLP 层甚至处理降采样达 1/64 的张量。
此设计显著降低了图像编码的延迟,同时为计算密集型的 LLM 解码器减少了最多 4 倍的视觉 token,从而显著缩短首 token 输出时间(TTFT)。研究者将该架构命名为 FastViT-HD。
FastViT-HD 由五个阶段组成。前三阶段使用 RepMixer 模块,后两阶段则采用多头自注意力(Multi-Headed Self-Attention)模块。
各阶段的深度设定为 [2, 12, 24, 4, 2],嵌入维度为 [96, 192, 384, 768, 1536]。ConvFFN 模块的 MLP 扩展倍率为 4.0。整体参数量为 125.1M,为 MobileCLIP 系列中最大 FastViT 变体的 3.5 倍,但依然小于多数主流 ViT 架构。
研究者采用 CLIP 的预训练设置,使用 DataComp-DR-1B 进行预训练后,再对该模型进行 FastVLM 训练。
如表 3 所示,尽管 FastViT-HD 的参数量比 ViT-L/14 小 2.4 倍,且运行速度快 6.9 倍,但在 38 项多模态零样本任务中的平均表现相当。相比另一种专为 VLM 构造的混合模型 ViTamin,FastViT-HD 参数量小 2.7 倍,推理速度快 5.6 倍,检索性能更优。

表 4 比较了 FastViT-HD 与其他 CLIP - 预训练层次型主干网络(如 ConvNeXT-L 和 XXL)在 LLaVA-1.5 训练后的多模态任务表现。尽管 FastViT-HD 的参数量仅为 ConvNeXT-XXL 的 1/6.8、速度提升达 3.3 倍,其性能仍然相当。

2、视觉编码器与语言解码器的协同作用
在 VLM 中,性能与延迟之间的权衡受到多个因素的影响。
一方面,其整体性能依赖于:(1) 输入图像分辨率、(2) 输出 tokens 的数量与质量、(3) LLM 的建模能力。
另一方面,其总延迟(特别是首 token 时间,TTFT)由图像编码延迟和 LLM 预填充时间组成,后者又受到 token 数量和 LLM 规模的共同影响。
鉴于 VLM 优化空间的高度复杂化,针对视觉编码器最优性的任何结论都须在多组输入分辨率与 LLM 配对下加以验证。我们在此从实证角度比较 FastViT-HD 相较 FastViT 的最优性。研究者测试三种 LLM(Qwen2-0.5B/1.5B/7B),并在不同输入分辨率下进行 LLaVA-1.5 训练与视觉指令调优,然后在多个任务上评估结果,结果见图 4。

首先,图 4 中的帕累托最优曲线(Pareto-optimal curve)表明,在预算固定的情况下(如运行时间 TTFT),最佳性能对应的编码器 - LLM 组合是动态变化的。
例如,将高分辨率图像输入配备小规模 LLM 并不理想,因为小模型无法有效利用过多 token,同时,TTFT 反而会因视觉编码延迟增大(详见图 5)。

其次,FastViT-HD 遍历 (分辨率,LLM) 所形成的帕累托最优曲线明显优于 FastViT —— 在固定延迟预算下平均性能提升超过 2.5 个点;相同时序目标下可加速约 3 倍。
值得注意的是,在此前已有结论表明,基于 FastViT 的 VLM 已超越 ViT 类方法,而 FastViT-HD 在此基础上进一步大幅提升。
3、静态与动态输入分辨率
在调整输入分辨率时,存在两种策略:(1) 直接更改模型的输入分辨率;(2) 将图像划分成 tile 块,模型输入设为 tile 尺寸。
后者属于「AnyRes」策略,主要用于让 ViT 能处理高分辨率图像。然而 FastViT-HD 是专为高分辨率推理效率而设计,因此我们对这两种策略的效率进行了对比分析。
图 6 显示:若直接将输入分辨率设定为目标分辨率,则 VLM 在准确率与延迟之间获得最佳平衡。仅在极高输入分辨率(如 1536×1536)时,动态输入才显现优势,此时瓶颈主要表现为设备上的内存带宽。

一旦使用动态策略,tile 数量越少的设定能获得更好的精度 - 延迟表现。随着硬件发展与内存带宽提升,FastVLM 在无需 tile 拆分的前提下实现更高分辨率处理将成为可行方向。
4、与 token 剪枝及下采样方法的比较
研究者进一步将不同输入分辨率下的 FastViT-HD 与经典的 token 剪枝方法进行对比。如表 5 所示,采用层次化主干网络的 VLM 在精度 - 延迟权衡上明显优于基于等维(isotropic)ViT 架构并借助 token 剪枝优化的方法。在不使用剪枝方法、仅利用低分辨率训练的前提下,FastViT-HD 可将视觉 token 数降至仅 16 个的水平,且性能优于近期多个 token 剪枝方案。
有趣的是,即便是当前最先进的 token 剪枝方法(如所提出的 [7, 28, 29, 80]),在 256×256 分辨率下,整体表现亦不如 FastViT-HD。
更多详细内容请参见原论文。