视频生成1.3B碾压14B、图像生成直逼GPT-4o!港科&快手开源测试时扩展新范式
测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?
为了回答这一问题,最近香港科技大学联合快手可灵团队推出 Evolutionary Search (EvoSearch)方法,通过提高推理时的计算量来大幅提升模型的生成质量,支持图像和视频生成,支持目前最先进的 diffusion-based 和 flow-based 模型。EvoSearch 无需训练,无需梯度更新,即可在一系列任务上取得显著最优效果,并且表现出良好的 scaling up 能力、鲁棒性和泛化性。
随着测试时计算量提升,EvoSearch 表明 SD2.1 和 Flux.1-dev 也有潜力媲美甚至超过 GPT4o。对于视频生成,Wan 1.3B 也能超过 Wan 14B 和 Hunyuan 13B,展现了 test-time scaling 补充 training-time scaling 的潜力和研究空间。
目前,该项目的论文和代码均已开源。

论文标题:Scaling Image and Video Generation via Test-Time Evolutionary Search
项目主页:https://tinnerhrhe.github.io/evosearch/
代码:https://github.com/tinnerhrhe/EvoSearch-codes
论文:https://arxiv.org/abs/2505.17618
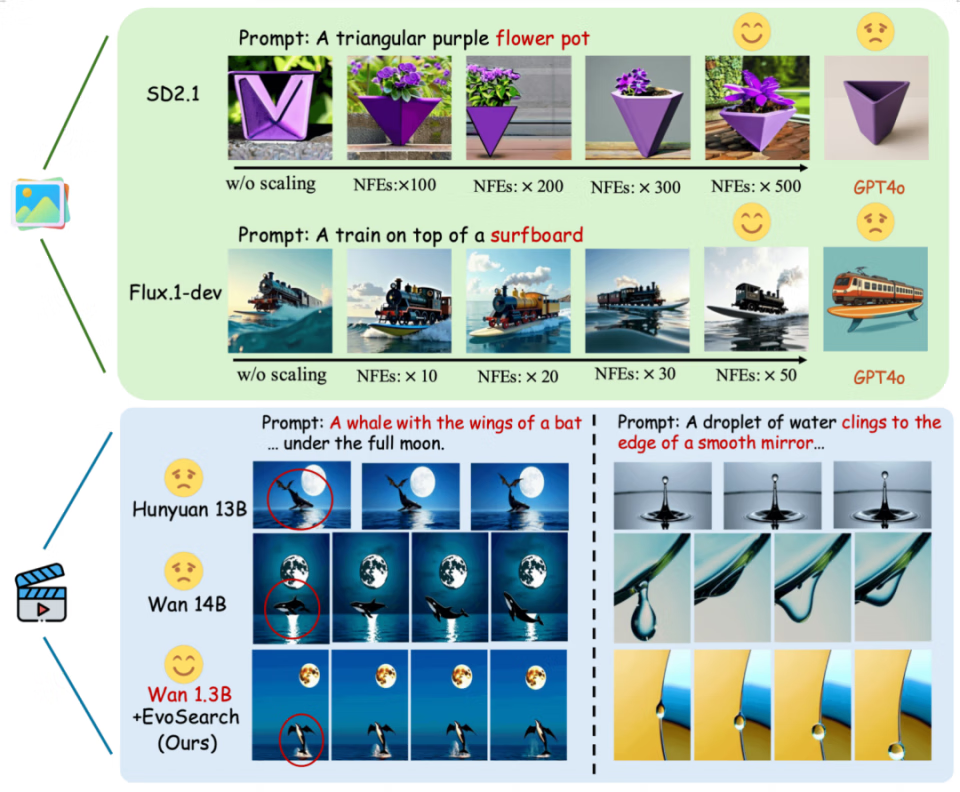
我们来看 EvoSearch 与其他一些方法的效果对比:

1.Test-Time Scaling 的本质
这里团队将测试时扩展(Test-Time Scaling)和 RL post-training 分开来看,定义前者无需参数更新,后者需要计算资源进行后训练。Test-time scaling 和 RL post-training 本质都是为了激发预训练模型的能力,使其与人类偏好(奖励)对齐。给定一个预训练模型和奖励函数,目的是拟合如下的目标分布:
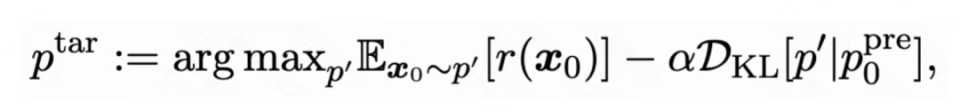
其中是奖励函数代表(人类)偏好,KL 距离()防止预训练模型的分布与目标分布偏离太远,避免知识遗忘。该目标分布可以重新写成如下形式:

其中是归一化常数,需要遍历整个状态空间来计算。这是不可行的,因为 diffusion 和 flow 模型的状态空间都是高维的。这导致直接从目标分布采样不可行。
2. 当前方法的局限性
诸如 RL 的后训练方法虽然也能从目标分布采样,但需要构造数据以及大量计算资源重新更新模型参数,导致代价很大并且很难 scale up。目前在视觉领域,最有效的 test-time scaling 方法包括 Best-of-N,它基于重要性采样(Importance Sampling)来拟合目标分布采样。Best-of-N 随机采样多个样本,并筛选出奖励最高的 N 个。在基于 diffusion 和 flow 模型的图像和视频生成任务上,Best-of-N 的样本通常是初始噪声。
最近的一些工作提出了更高级的采样方法,可以统一称为 Particle Sampling。这类方法将搜索空间拓展为整条去噪轨迹,在去噪过程中不断保留好的样本,并丢掉表现差的样本(类似 beam search)。这类方法虽然也能表现出 scaling up 性质,但缺少探索新的状态空间能力,并且会减少生成样本的多样性。
团队做了一个小实验,当目标分布和预训练分布不一致(甚至可能是 o.o.d.),基于学习的 RL 方法会出现奖励过优化的现象(reward over-optimization)。诸如 best-of-N 和 particle sampling 的搜索方法也不能找到目标分布所有的模态。但团队的方法 EvoSearch 成功拟合了目标分布,并且取得了最高的奖励值。
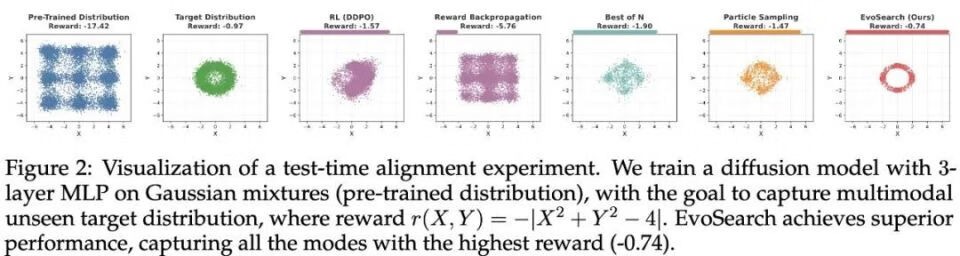
3. EvoSearch 解读
团队将图像和视频生成的 test-time scaling 问题重构成演化搜索问题。
具体来说,受生物的自然选择和演化所启发,团队将 diffusion 和 flow 模型中的去噪轨迹看成演化路径,每个去噪步的样本都可以进行变异演化来探索更高质量的子代,最后得到最优的符合目标分布的去噪样本(图片或者视频)。
不同于一般的演化方法,样本空间局限于一个固定的状态空间进行演化,团队提出的 EvoSearch 的演化空间沿着去噪轨迹动态前移,即起始于高斯噪声,终止于。
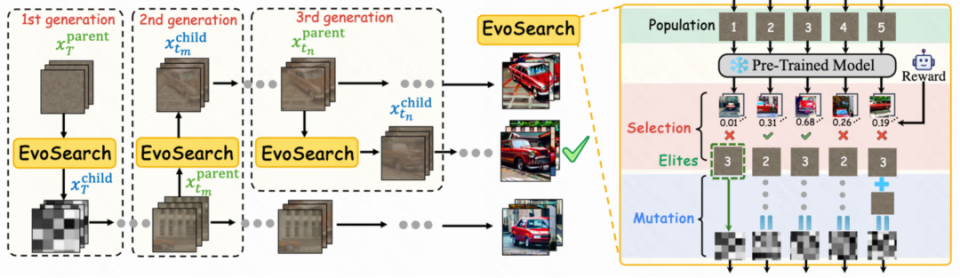
EvoSearch 框架图
团队的方法受如下的洞见启发:他们发现在整个去噪轨迹中,高质量的样本往往会聚集在一起。因此,当搜索到高质量的父代,则可以在父代周围的空间进行探索从而有效找到更高质量的样本。从下图可以看到去噪轨迹中的样本在低维空间的分布与奖励空间具有强相关性。
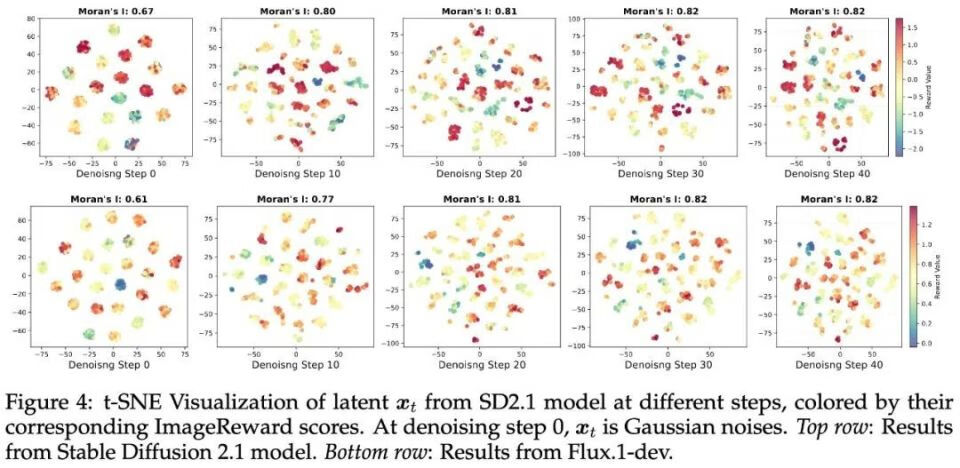
基于此,团队设计了如下两种变异模式:
初始噪声变异:EvoSearch 通过如下正交操作保持初始噪声仍然符合高斯分布
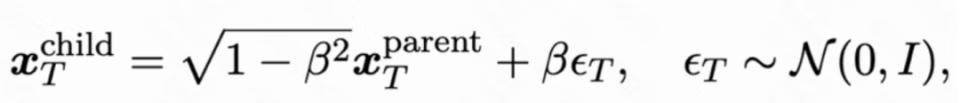
其中是变异率来控制探索强度。
中间去噪状态变异:由于中间去噪状态的分布是复杂的且在搜索过程中不可知。团队受 SDE 方程启发,设计如下变异模式:
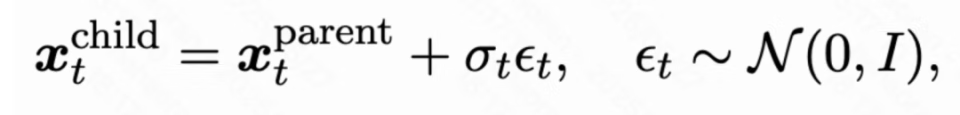
其中是 SDE 去噪过程中的扩散系数。
这些变异方式一方面加强了对于新的状态空间探索,另一方面又避免了偏离去噪轨迹的预训练分布。
我们定义了 evolution schedule 和 population size schedule 来进行演化搜索,这两种 schedule 的设置取决于可用的测试时计算量大小。
Evolution Schedule 定义为
![]() ,用于指定应该在哪些时间步骤进行 EvoSearch。该调度模式避免了冗余去噪步数,节省了计算开销。
,用于指定应该在哪些时间步骤进行 EvoSearch。该调度模式避免了冗余去噪步数,节省了计算开销。Population Size Schedule 定义为
![]() ,其中
,其中代表了初始噪声样本的种群大小,后续每个
规定了在时间步
的演化子代种群大小。


EvoSearch 算法伪代码如下:


4.EvoSearch 实验结果
1. 对于图片生成任务,在 Stable Diffusion 2.1 和 Flux.1-dev 上,EvoSearch 展示了最优的 scaling up 性质。即使测试时计算量扩大了 1e4 量级,仍能保持上升势头。对于视频生成任务,EvoSearch 在 VBench,VBench2.0 以及 VideoGen-Eval 中的 prompts 上也能达到最高的 reward 提升幅度。
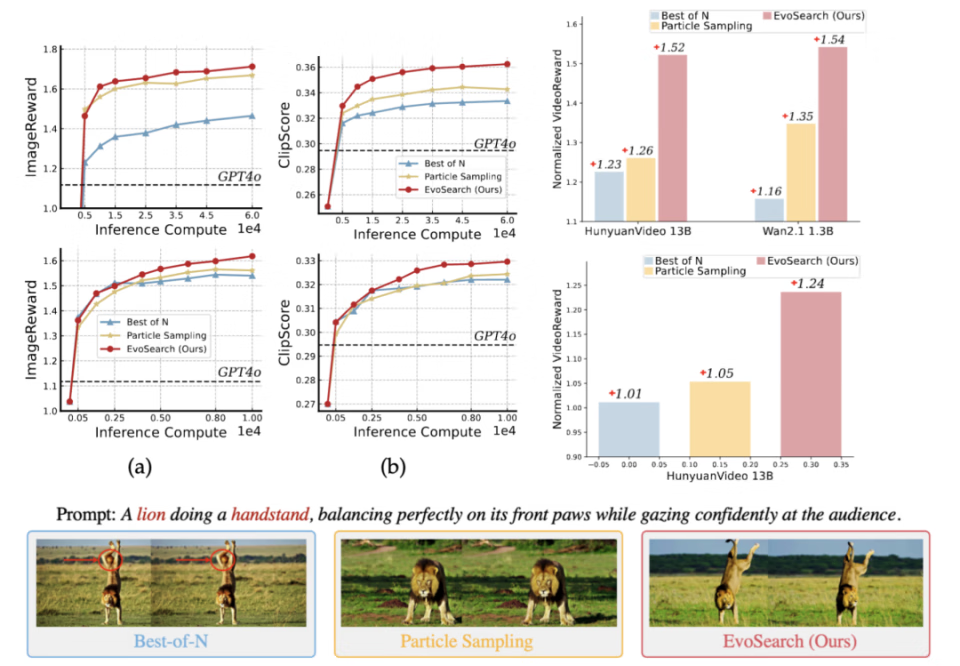
2.EvoSearch 也能泛化到分布外(unseen)的评估指标,显示了最优的泛化性和鲁棒性。
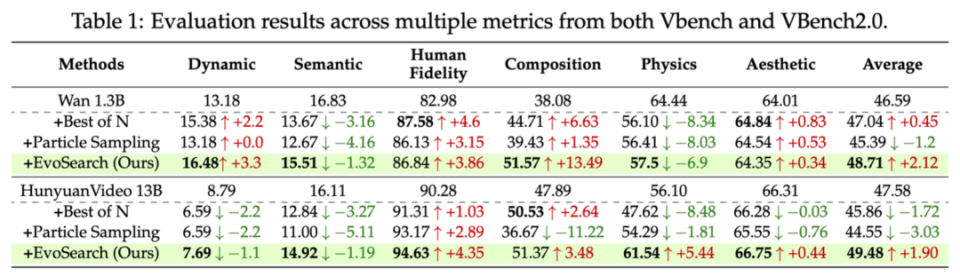
3. EvoSearch 在人类评估上也达到最优胜率。这得益于他高的生成多样性,平衡了 exploration 和 exploitation。

4. 下面是更多的可视化结果:
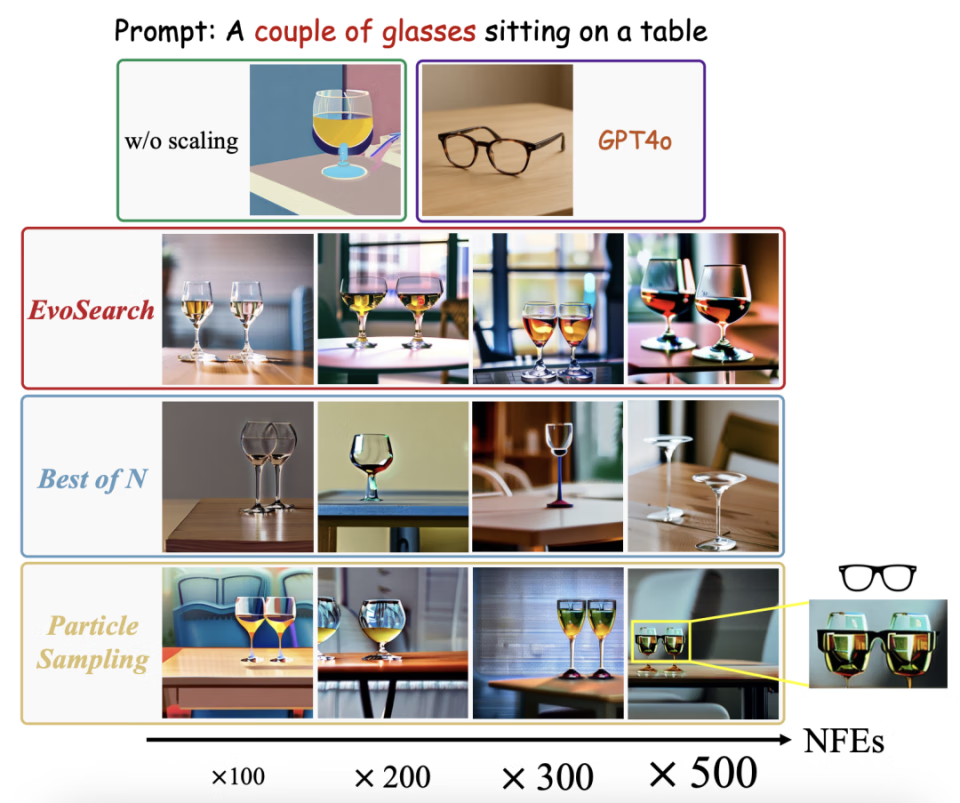


更多细节请见原论文和项目网站。
