小红书发布FireRedChat:首个可私有化部署的全双工大模型语音交互系统
小红书智创音频团队推出业内首个支持私有化部署的全双工大模型语音交互系统 FireRedChat,自研流式 pVAD 与 EoT 让语音交互更加自然,首发级联与半级联两套实现,端到端时延逼近工业级应用。彻底开源、可私域落地,打造真正 “知冷暖、能共情、懂表达” 的语音 AI。
小红书智创音频团队发布 FireRedChat—— 业内首个支持私有化部署的全双工大模型语音交互系统,直击延迟高、噪声敏感、可控性差、依赖外部 API 等痛点。
FireRedChat 基于 “交互控制器+交互模块+对话管理器” 的完整架构,将任意半双工链路一键升级为全双工;集成自研流式个性化打断 pVAD、语义判停 EoT、FireRedTTS-1s、FireRedASR、FireRedTTS2 等核心模型,提供级联与半级联两种端到端服务部署方案,覆盖从 “稳定易部署” 到 “更有温度” 的不同需求,显著提升实时性、鲁棒性与可控性。
实验结果显示,系统在多项关键指标领先其他开源框架,为 “更智能、更自然” 的全双工语音交互提供了一套真正可用、可落地的开源方案。

技术报告:https://arxiv.org/pdf/2509.06502
在线体验:https://fireredteam.github.io/demos/firered_chat
开源代码:https://github.com/FireRedTeam/FireRedChat
通过 FireRedChat 构建的 AI 聊天助手不仅具备「快速打断,智能判停,实时响应」的自然对话能力,还能依托内置的情绪感知与情感合成,让 AI 不再是一个冷冰冰的机器人,而是一个「知冷暖、能共情、懂表达」的好朋友。
她能细腻感知你的情绪变化:在你失落时,轻声安慰、真诚鼓励;在你遇到惊喜时,和你一样心潮澎湃、享受 surprise;在你开心时,陪你分享喜悦、一起欢笑。
FireRedChat 让 AI 聊天助手不只是回应文字,更能用富有温度的声音、情感和表达方式,带给你一种被理解、被陪伴的真实感受,让 AI 真正拥有「人感」。
为什么全双工语音交互难,难在何处?
用户期待的是 “你说我听、我说你懂” 的自然对话,而非机械的一问一答。为了实现自然对话,要求系统既要能精准感知双方交互中的轮次变化,又要能抵抗外部其他说话人以及环境噪声的干扰;既要知道 “何时打断” 不出错,又要把握 “何时回复” 的最佳时机;还要摆脱闭源 API 的束缚,做到全链路可控、可私有化部署。这些挑战长期压制着开源生态的产品化落地。
FireRedChat 的硬核突破:五个 “真牛” 的点
第一,行业首创的 “全双工 + 私有化” 组合。FireRedChat 从设计之初就面向企业级落地,完整覆盖从音频输入到语音合成的全链路,并提供一键私有化部署能力,在数据安全、成本可控和系统扩展性上全面领先。
第二,自研 pVAD + 轻量 EoT,让 “打断” 又稳又准。pVAD 专注识别主要说话人,有效抑制环境噪声与他人说话带来的误触;EoT 准确判断用户的表达是否已经具备完整语义,避免过早打断或迟缓回应,实现自然轮次转换。
第三,级联与半级联双路线并行,兼顾成熟度与体验。级联链路(ASR → LLM → TTS)部署灵活,各模块可独立优化;半级联链路(AudioLLM → TTS)直连音频输入,可感知情绪与副语言信息,生成更贴心的回应,并进一步降低延迟与误差传播。两套方案都可直接升级为全双工,满足不同业务场景的精度、时延与成本权衡。
第四,端到端低时延,逼近工业级。凭借模块解耦与流式优化,FireRedChat 在本地级联部署下实现接近工业级系统的端到端延迟,真正把 “实时”“自然” 落到体验里。
第五,不仅能听懂,还能 “听出情绪、说出温度”。通过 AudioLLM 与 FireRedTTS2 的联动,系统可捕捉用户声学线索(情绪、语调、节奏),在回应中自然体现关怀与共情:你失落时能安慰鼓励,你兴奋时共情分享,让 AI 从 “能回答” 走向 “有温度” 的陪伴与理解。
解耦带来可控,可插拔带来进化
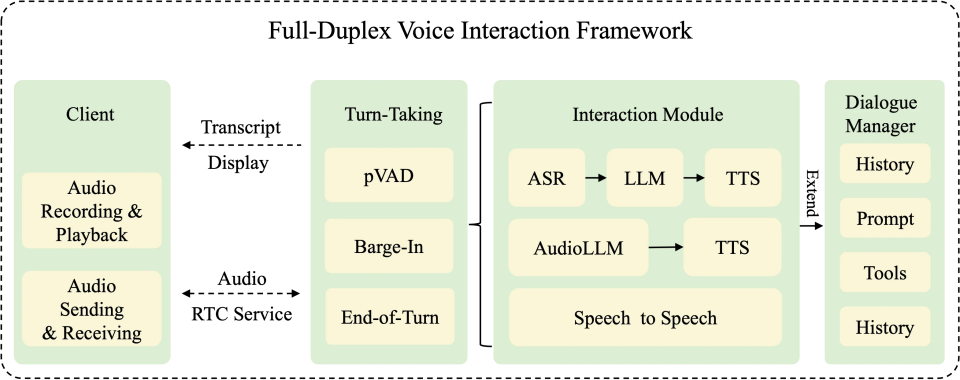
FireRedChat 将全双工语音交互解耦为三个核心模块,既保留端到端链路的高性能,又确保系统的可维护性和可扩展性。
轮次转换控制器(Turn-taking Controller):基于自研 pVAD 与轻量 EoT,实时判断 “谁在说、何时停、何时该我说”,像一位聪明的主持人维持对话秩序,显著降低噪声与多说话人场景下的误打断。
交互模块(Interaction Module):支持两种模式。级联模式整合 FireRedASR 与 FireRedTTS-1s,TTS 支持上下文感知,声音更贴合语境;半级联模式以 AudioLLM 直达语音语义与情感,再接 FireRedTTS-2 完成富表达的合成,打造更顺滑的 “听 —— 想 —— 说” 链路。
对话管理器(Dialogue Manager):负责对话状态管理并扩展系统能力,支持工具调用(如 WebSearch)、RAG 检索增强、插件扩展与工作流管理。系统内置与 Dify 的集成样例,便于开发者进行提示词工程、知识库构建与应用编排,快速把 Demo 变成产品。
开源、免费、可私有化
为了给开发者与企业真正的掌控力,FireRedChat 坚持彻底开源:核心模块 TTS、ASR、pVAD、EoT 全部开放,无需 API 费用与外部依赖。系统支持在企业私有环境一键部署,数据资产不出域,安全合规可审计。基于 LiveKit 的清晰模块化与完善文档、简洁 Web UI,使得普通用户即开即用,开发者可快速二次开发与深度定制。
典型应用场景
智能语音助手:自然打断、即时回应,贴近真人对话节奏。
客服与外呼:商场、车站等复杂声场仍能稳定识别与响应。
教育与心理陪伴:情绪感知与表达丰富度带来更强的同理心体验。
更客观的结果背书
FireRedChat 设立系统级指标,聚焦真实体验的三件事:更少的误打断,更准的语义端点检测,更低的延迟。
打断准确率方面,pVAD 显著减少噪声和无关说话人的误打断,并通过微小等待(如 50ms)在鲁棒与灵敏之间取得更优权衡。

语义端点检测准确率方面,EoT 让系统更懂 “你说完没”,减少尬等与抢话。
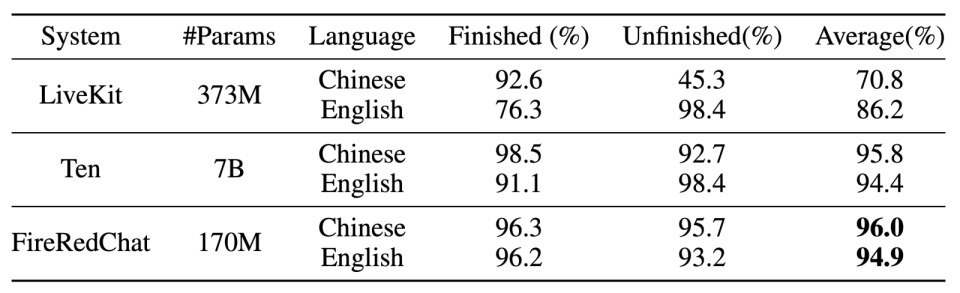
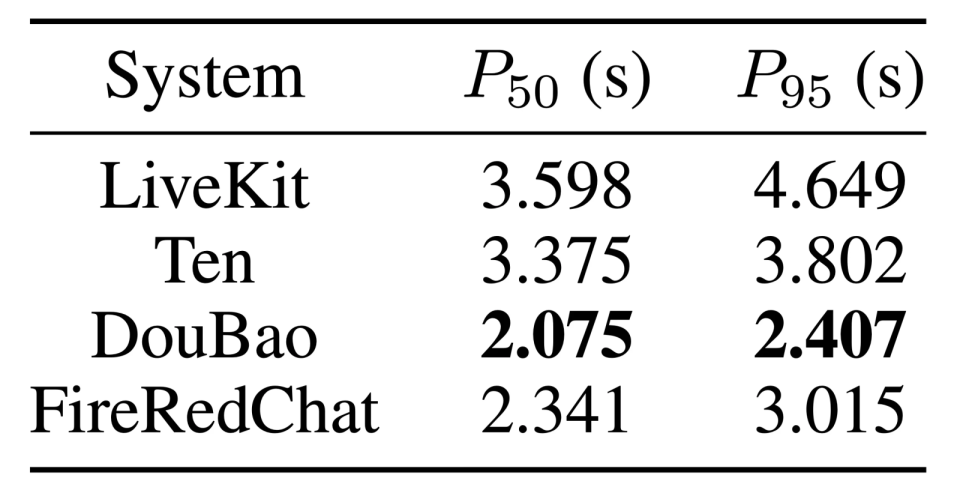
端到端延迟方面,本地级联部署下的响应接近工业级闭源系统,全面超越开源框架,将 “即时反馈” 变成常态。
总结与展望
FireRedChat 以 “全双工+私有化+全链路开源” 的组合拳,为全双工语音交互贡献了小红书方案。通过可插拔架构、精准轮次控制与双路线深度优化,系统在自然度、鲁棒性与时延上取得突破性进展,影响语音交互体验的性能领先其他开源框架,时延上逼近工业级闭源系统。
未来,FireRed Team 将持续迭代 FireRedChat,融入更强大的 AudioLLM、更丰富的多模态交互,并与全球开源社区共建,把语音 AI 从 “能用” 推向 “好用”,再到 “人人可用、处处可用”。
