翁荔称为“优雅”的在蒸馏策略,如何颠覆成本与效率的传统认知?|新论文解读
文|博阳
编辑|郑可君
模型的后训练,长久以来存在着一个不可能三角。
研究人员渴望模型在整个过程中同时拥有强大的能力、高效的训练成本,以及可控的对齐。
然而两种主流后训练模式都各有致命缺陷:SFT和蒸馏虽然简单可并行,但这种填鸭式教育让模型在完美数据中变得僵化,无法应对自己犯错时的未知局面;RL赋予了模型探索能力,但稀疏奖励导致的大规模试错让成本激增。
在这个背景下,Thinking Machines 对 Qwen 团队工作的深入分析和复现,揭示了一种被称为在策略蒸馏(On-Policy Distillation, OPD)的方法,试图破解这个不可能三角。
Thinking Machines 是由前OpenAI首席技术官Mira Murati在2025年2月创立的AI研究与产品公司,汇聚了来自 OpenAI、DeepMind、Meta 等公司的顶尖人才,包括 ChatGPT、DALL·E 等项目的核心贡献者,OpenAI前安全研究副总裁Lilian Weng(翁荔)是该公司的联合创始人之一。

他们提出的这个方法的最大特点,就是翁荔所说的“优雅的结合”。它以一种违反直觉的融合,解决了上述两大范式最棘手的问题。

那么,它到底优雅在哪儿呢?
在策略的蒸馏,和传统蒸馏有何不同?
要理解OPD的优雅,我们必须首先理解传统蒸馏的局限性。
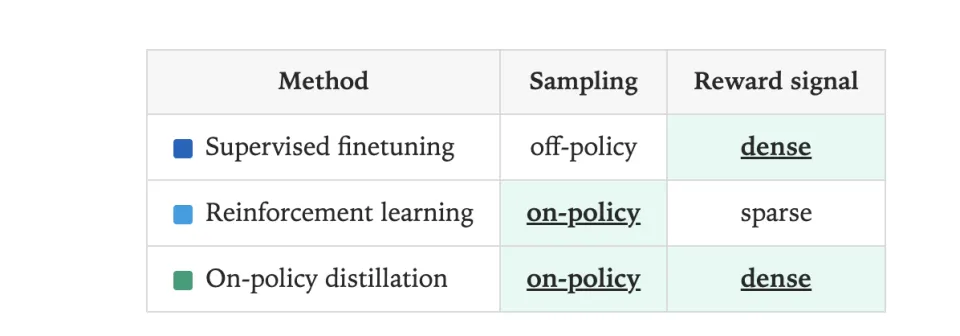
传统蒸馏本质上是离策略(Off-Policy)的:学生学习的是老师预先生成的静态数据集,充满完美轨迹的标准答案。而OPD更接近强化学习RL,其训练数据不再是老师的完美录像,而是学生自己(On-Policy)实时生成的轨迹。
学生自己的真实分布(它自己会犯的错)上,受到来自老师每个token水平上的密集指导。这样它就会被训练成一个学习者。

传统蒸馏中,学生只学会了在“老师会遇到的状态”下如何做。一旦学生在推理链里犯了错,走了一步老师棋谱里没有的臭棋,就会导致复合错误,即一步错、步步错。
而Thinking Machines这种更具RL属性的在策略蒸馏(OPD),让学生学会了在“自己真实会遇到的状态”下如何思考,解决了传统蒸馏,也是SFT的复合错误难题。
这本是强化学习相较于SFT整体性的一种优势。
但强化学习也有自己的问题,那就是效率太低。
在RL和SFT之间的优雅融合
RL通过在试错中学习,因此可以规避 SFT 存在的复合错误问题。
但标准的RL因为要大量试错效率太低,比如说在稀疏奖励型RL中,信用分配(Credit Assignment)极其困难。模型输出了100个token,最后答案错了,完全不知道是第1步想错了还是第50步算错了。为了找到哪一步是坏棋,需要海量样本巨量的 rollouts)去猜,方差极大,收敛极慢,成本高企。
为了解决这个问题,研究者们提出了过程奖励模型(Process Reward Models, PRM)。训练一个裁判给每一步都打分。这已经非常接近OPD了,因为它同样是On-Policy采样和密集反馈。
但OPD的构思显然更进了一步,它提出了一个极其优雅的简化:我们为什么需要一个费力训练的裁判(RM),直接用蒸馏的思路,让老师(Teacher Model)本人上场不好吗?
PRM的反馈是标量分数(-0.5分),学生拿到分数后依然需要自己探索如何提升。而OPD的反馈是KL散度,即直接告诉学生和老师的差距在哪里。
这就是OPD的融合之妙:它拥有RL的灵魂(让学生在自己的真实轨迹上学习),同时拥有它拥有SFT蒸馏的肉体(密集的KL散度监督)。
而且它既规避了SFT的易错,又避免了RL的低效。
也避免了SFT中固有的灾难性遗忘(因为教师KL散度也是全领域的),以及RLHF(包括PRM)流程中最昂贵的步骤:训练奖励模型(RM)。
优雅的成本控制
所有人的第一直觉都是OPD这种在线方法一定贵得离谱,因为学生每一步都要调用巨大的老师模型去做一次正向传播。
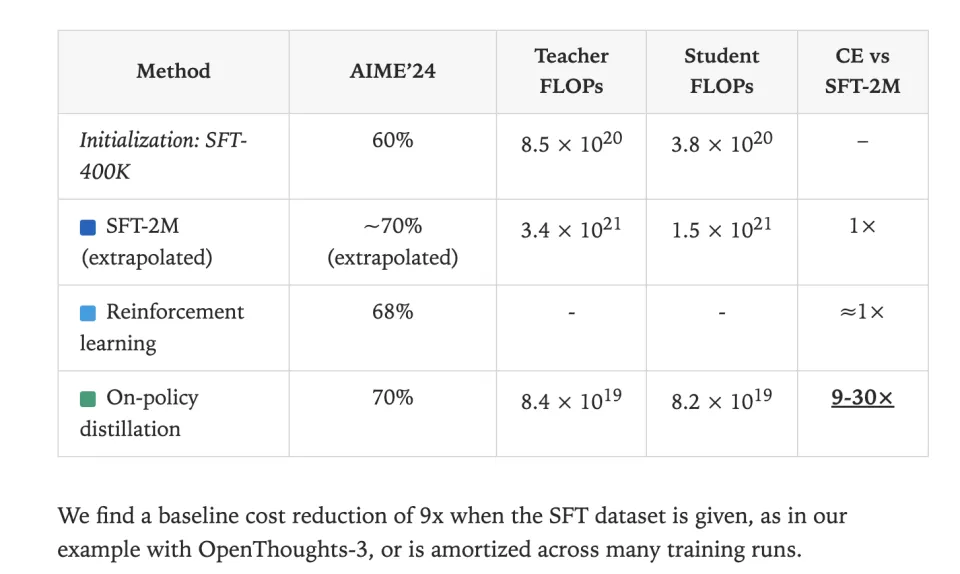
然而,Thinking Machines 博客中的图表给出了一个完全反直觉的答案:OPD 的总成本效率,甚至碾压了 SFT,达到了 9-30 倍之多。
这是因为OPD确实单步成本高,但样本效率(Sample Efficiency)也高。
SFT在打基础阶段(0到400K数据)确实低廉,但当模型达到瓶颈(比如AIME'24得分60%)后,边际效益急剧递减。为了将分数从60%提升到70%,如果继续使用SFT,需要用5倍数据量去硬灌那10%的提升,成本高到无法接受。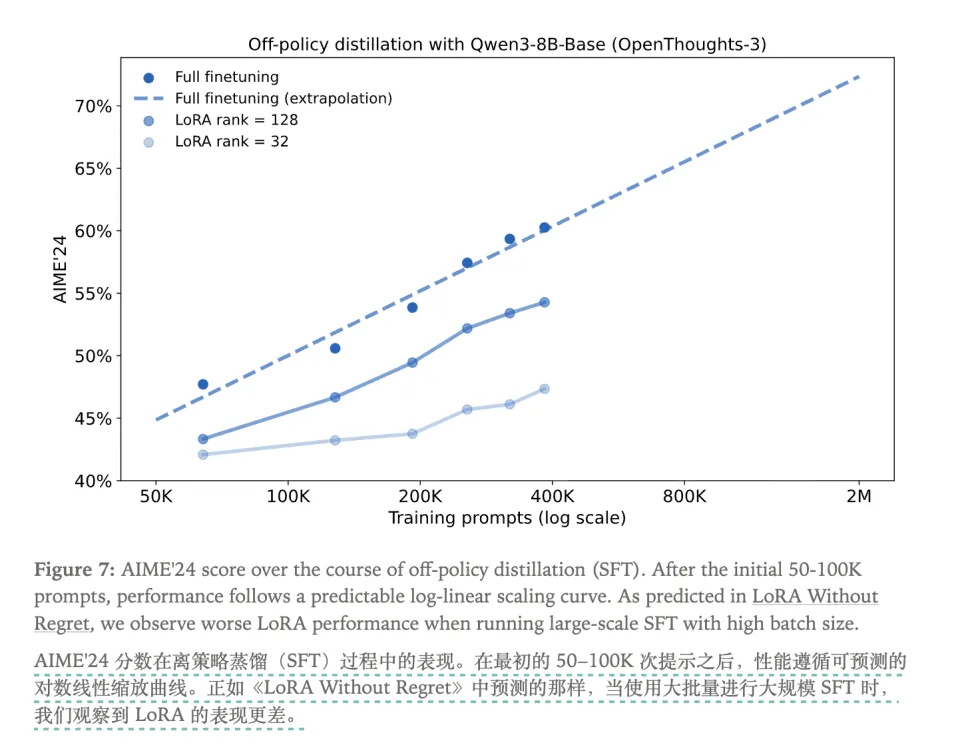
而RL的稀疏奖励导致海量无效试错,为了找到通往+1分的路径,99.9%的算力都浪费在错误答案的探索上。它在初期的成本效率比SFT还低,后期提升部分才能基本持平。
而OPD 的“单步成本”确实非常高,但它换来的是极致的样本效率。在 OPD 中,没有一步是浪费的。
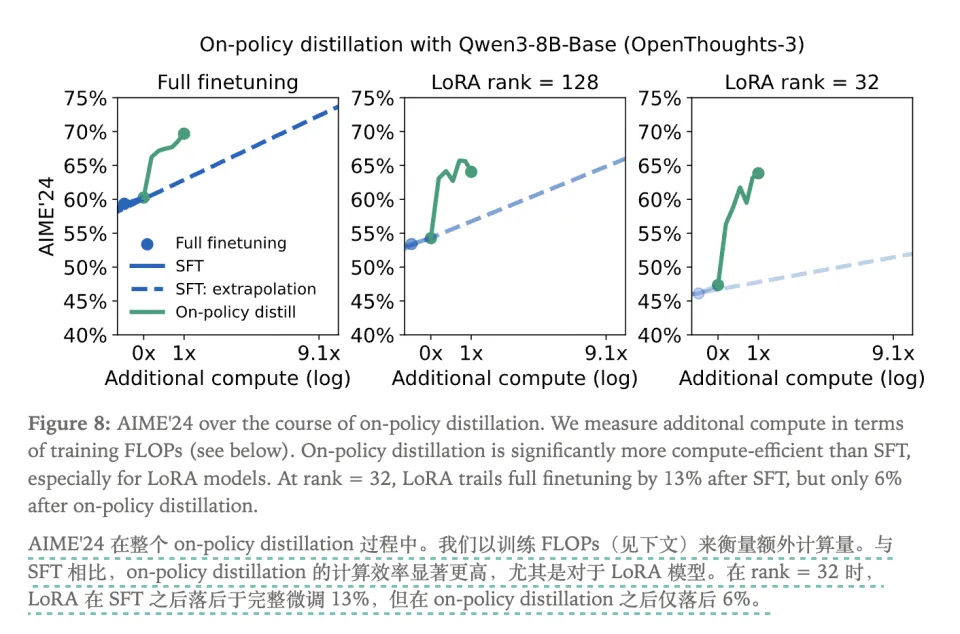
当学生走对了,老师确认并给予正反馈;当学生走错了(这恰恰是SFT无法处理的时刻),这个"错误样本"反而成了最有价值的数据。因此OPD根本不需要SFT-2M那样海量的样本,只需要SFT-400K之后少量高质量纠错练习,就能实现从60%到70%的飞跃。
这就是那张图表所揭示的真相:OPD 的额外成本,仅是 SFT(硬灌)的 1/13.6。它用高质量的单步指导替换了低质量的海量试错,彻底颠覆了“RL很贵、SFT很便宜”的传统认知。
这是 OPD 的第二层优雅。
最优雅的,在于想象力的一跃
OPD这种用RL的On-Policy采样,去跑SFT的蒸馏目标的想法,似乎并不难想到。为什么在这么长的时间里,几乎没有人把这两者做一个如此简单直接的结合呢?
这背后,恰恰是两大后训练阵营壁垒带给研究者的认知误区。
SFT/蒸馏阵营的误区,是成本洁癖。他们的核心优势是离线带来的廉价,本能地无法接受在线调用大模型老师的昂贵范式,认为这在成本上不可能优于SFT。
而RL阵营的误区,则是奖励模型(RM)崇拜,和对模仿的鄙视。自RLHF成功以来,全部精力都用于训练更好的RM,痴迷于标量奖励和探索。而OPD这种逐帧模仿老师分布的做法,在他们看来根本不是真正的RL,它太Low、离元学习太远。
OPD的优雅一跃,在于它用一个反直觉的实验,同时击碎了两个阵营的认知枷锁。
OPD用一个反直觉的实验,同时击碎了两个阵营的枷锁:这种看似昂贵的在线方法,由于样本效率的碾压,总成本反而比廉价的SFT低了10倍;而且根本不需要复杂的奖励模型,最简单的模仿就能更快、更稳、更便宜地教会模型思考。
这种用最简单的组合(On-Policy采样 + KL散度损失),去解决两个最复杂范式(SFT和RL)的难题,这才是OPD最优雅的地方——一次想象力的飞跃。
(本文作者博阳,微信号为haoboyang001,如有讨论沟通或线索提供,可添加微信交流)