Kimi最新论文,让线性注意力结束妥协时代,进入超越时代
文|博阳
编辑|可君
在 2024 年和 2025 年的中国 AI 牌桌上,线性注意力(Linear Attention)是一个绕不开的词。
阿里、Minimax,以及几乎所有试图在万亿参数游戏中下注的玩家,都面临一个残酷的现实:算力的瓶颈。传统全注意力的复杂度,在算力受限的情况下就是自杀式消耗。序列长度翻倍,计算量和显存需求翻四倍。
线性注意力承诺用 O(N) 的计算量和恒定的推理内存,换取还能接受的性能。中国的 AI 工程师们在这条道路上投入了很多,试图在算力受限的绝境中,"抠"出一条通往 AGI 的新路。
但这条路并不顺利。Minimax 这个最坚定的探索者之一,在最新模型中转回了混合架构。行业开始质疑:线性注意力是不是终究只是个备胎?
这个转向的背后,是线性注意力从精神祖先 RNN(循环神经网络)那里继承来的原罪:有限的状态容量和随之而来的长程检索能力不足。
就在这条技术路线即将被判处死缓之际,Kimi 发布了 Kimi Linear 技术报告,宣称他们找到了破解这个诅咒的钥匙。

这篇论文,也许宣告着线性注意力作为"妥协"的时代已经结束,而超越的时代即将开始。
源自 RNN,却难逃 RNN 的诅咒的线性注意力
要理解 Kimi 做了什么,我们必须先直面线性注意力的最大问题。
全注意力处理 100 万个 Token 时,会把所有词全部摆开,让每个新词都能看到之前的所有词。代价是 100 万 × 100 万 = 1 万亿次巨量计算,以及巨大的 KV 缓存。
线性注意力的核心目标,是把全注意力那个存储了所有历史信息的NXN的巨大矩阵,压缩成一个小巧的、可以持续更新的记忆胶囊。
它维护一个固定大小的状态向量(比如 128 维),每来一个新词就更新这个状态。写入新信息,部分保留旧信息,部分遗忘。无论序列多长,只存储这个固定大小的状态,计算量降到 O(N),内存变成恒定。
这就像一个速记员拿着固定大小的笔记本,每次更新都要擦掉一些旧内容腾出空间。线性注意力相比RNN的优势在于状态更新机制更复杂(有Query/Key/Value三种值),理论上能携带更丰富的信息。但本质上,它还是在用"有损压缩"换取效率。
这种有损压缩带来的核心问题是精确检索困难。当你需要从 100 万个 Token 中精确找回第 3 万个位置的某个关键信息时,那个被压缩了 97 万次的状态,已经很难给你准确答案了。
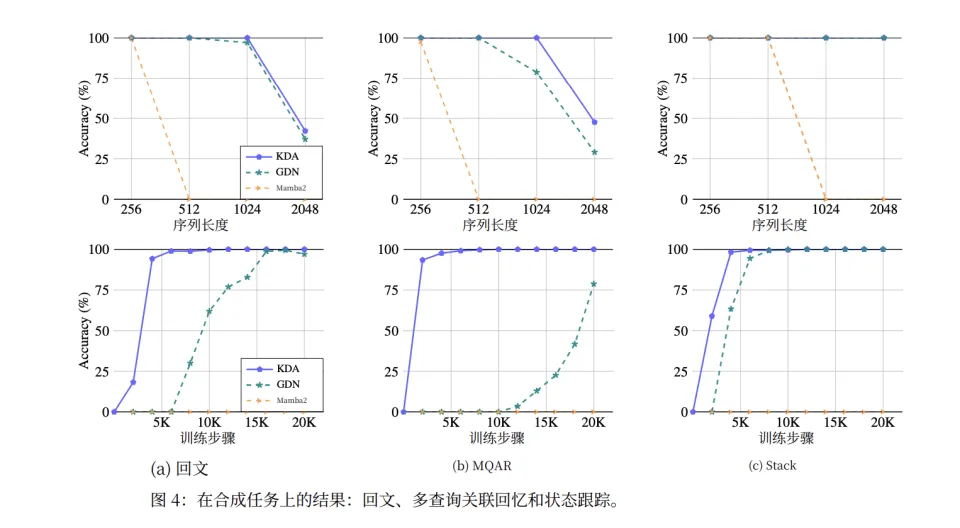
Kimi 的论文设置了几个经典的"杀手级"测试任务:回文复制(需要精确逆序输出)、多查询关联回忆(散布的键值对检索)、栈状态追踪(64 个独立栈的 PUSH/POP)。
结果,传统的线性注意力方法在这些任务上几乎完全失败,精度接近随机猜测。即使是改进版的 GDN(Gated DeltaNet),虽然有所改善,但收敛速度慢,最终精度也不理想。
当模型无法在长距离上精确回忆起关键信息时,它在长文本问答、代码生成等严肃任务上的表现就会直线下降。
这就是线性注意力一直被视为"妥协"的根本原因。
用精细化遗忘,拯救线性注意力
既然问题出在记忆上,就要从记忆解决。
在讲 Kimi 如何解决这个问题之前,我们需要先理解 Delta Rule。
最早的线性注意力本质上就是一个累加器。每来一个新的键值对,就往状态里加。没有遗忘,没有纠错,只会无限堆积,旧信息和新信息混在一起,无法分辨。
2023年的DeltaNet提出了一项重要改变。把状态更新看作在线梯度下降。它给那个笔记本设置了一个新目标。当前状态乘以当前的 key,应该能准确重构出当前的 value。如果重构不准确,就对状态做一次梯度下降更新,进行纠错。这个更新规则就是经典的 Delta Rule(Householder 变换)。
这让线性注意力从"只会记忆的笔记本"变成了"会学习和纠错的智能助手"。
但DeltaNet虽然会纠错,但不会遗忘。所有旧信息都会被无限期保留,在长序列中依然会导致干扰。
2024年英伟达的Gated DeltaNet为此加入了遗忘门。用一个标量 αt(0 到 1 之间)让模型可以动态决定保留多少旧信息,遗忘多少。
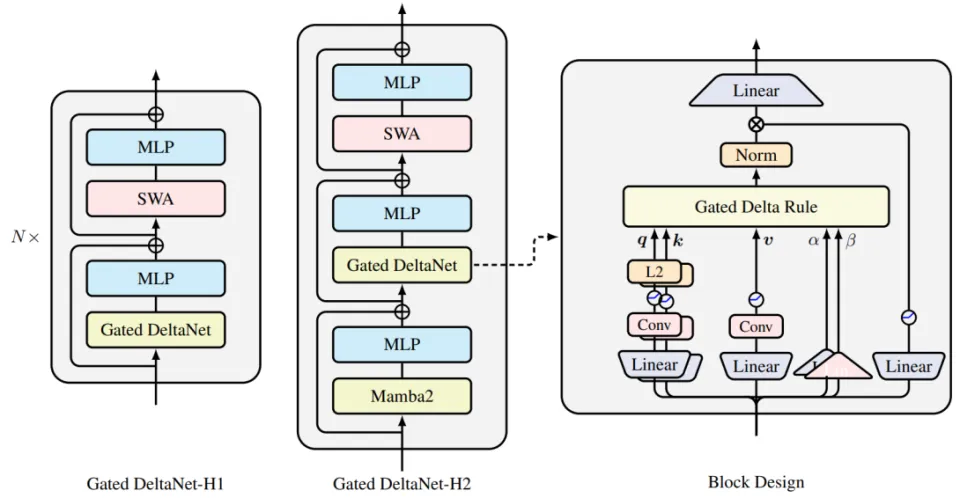
这是从累加到学习,再到选择性学习的进化路径。Delta Rule 是这条路径上的关键转折点。
而 Kimi 的 KDA,则是在这个基础上,进行了最后一次、也是最关键的一次跃迁。
KDA,一次注意力的变革
GDN 虽然引入了遗忘机制,但它的遗忘是粗放的。一个值作用于整个状态矩阵,相当于对所有特征通道一视同仁地打折。
这就像一个速记员,每次更新笔记时,都会对所有内容统一"淡化 30%"。如果模型需要精确记住一个关键实体,同时忘掉一个无关紧要的语气词,这个粗糙的速记员根本做不到。关键信息会在一次又一次"全局遗忘 30%"的冲刷下,变得越来越模糊,最终和那些不重要的信息混在一起,无法分辨。
Kimi 团队的解决方法就是,既然“一刀切”的全局遗忘不行,那我们就给每一个特征通道配一个独立的“遗忘开关”。
这就是 Kimi Linear 架构的核心,KDA(Kimi Delta Attention)注意力机制。它彻底抛弃了那个“全局遗忘 30%”的粗放命令,在注意力头中引入了“通道级别”的细粒度门控机制。
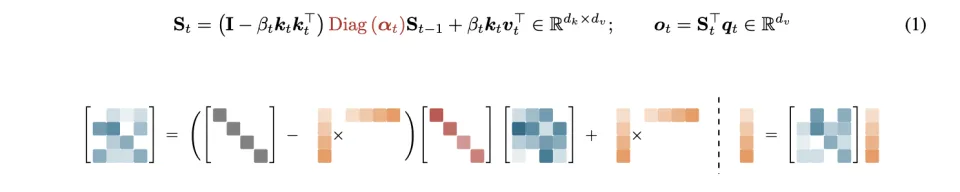
KDA 相当于给这位速记员配备了一个由 128 个独立开关组成的精细控制面板。当模型处理信息时,它可以动态地、可学习地决定本子里哪些行(通道)的内容负责记忆重要的实体词,不能忘。哪些行负责理解上下文语义,要少忘一点。哪些部分只是用来做语气词、语法框架用了,就干脆统统忘了。
这种从粗放遗忘到精细遗忘的转变,允许了模型在有限的内存中,记住更多有用的东西。
这种方法的效果也是立竿见影,效果是立竿见影的。在前面提到的"杀手级"任务上,KDA 在 2048 长度的回文任务上达到近 100% 精度,而 GDN 只有约 60%,Mamba2 完全失败。更重要的是,KDA 的收敛速度远快于 GDN。
然而,Kimi 的野心不止于此。如果 KDA虽然缓解了记忆问题,但性能还是追不上全注意力,那它依然只是一个妥协。而Kimi 的目标是超越。
夹心的混合架构更稳定
为此他们设计了一个新的混合架构,将 KDA 的优势发挥到了极致。
Kimi Linear 并未完全抛弃全注意力。它采用了 3:1 混合比例,每 3 层高效的 KDA 线性层,就穿插 1 层 MLA 全局注意力层 。这个 3:1 的比例,是 Kimi 团队通过大量消融实验找到的黄金比例/它在模型质量和吞吐量之间实现了最佳平衡。
这不是妥协,而是对理论限制的清醒认识。论文明确指出:长上下文精确检索,仍然是纯线性注意力的主要瓶颈。
在这个混合架构中,KDA 负责高效地处理时序信息、压缩上下文、并承担主要的计算负载。靠着它这一项,可以节省了 75% 的 KV 缓存。
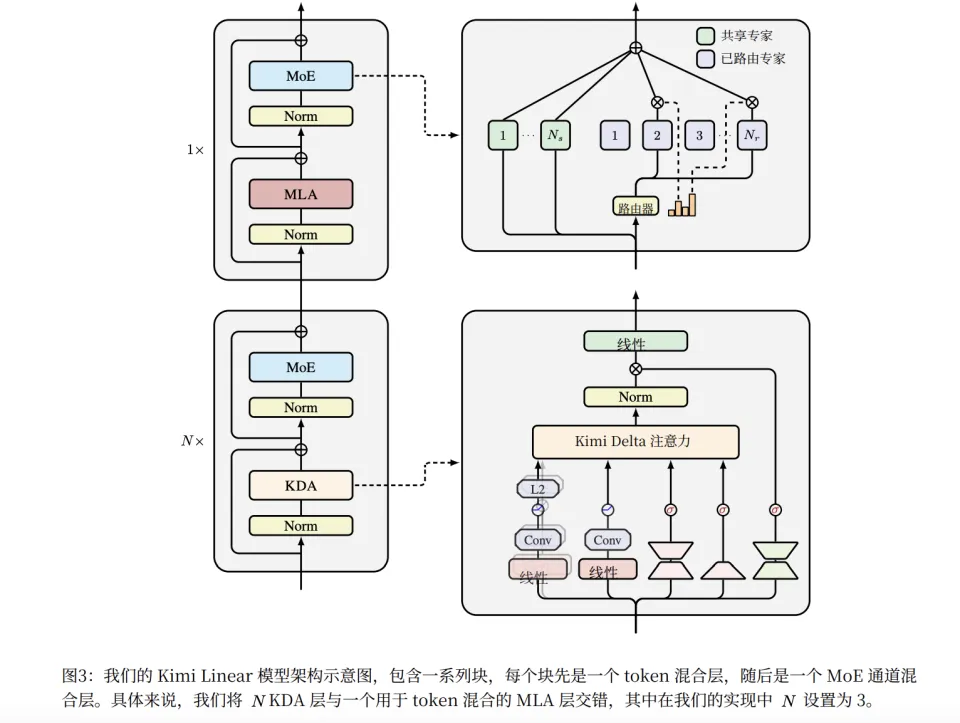
而传统的全局注意力MLA 则负责信息巡查员,捡回那些 KDA 压缩时可能丢失的、最精细的全局信息检索。
在这个架构中,KDA 和 MLA 不是主次关系,而是分工协作的平等伙伴。两者结合,才能在效率和性能上同时超越纯全注意力。
革了自家RoPE的命
同时,为了在更极限的压缩,Kimi甚至对自家研究员苏剑林开发出的影响深远的ROPE下了刀。这个混合架构采用了NoPE(No Position Encoding),也就是没有位置编码的形式。
传统的 Transformer 对序列顺序是无感的。你打乱输入顺序,输出依然结果不变。所以我们需要 RoPE(旋转位置编码)这样的机制,来告诉模型"第 100 个词在第 50 个词之后"。
而Kimi 团队发现,KDA 本身就可以作为位置编码使用。KDA用的门控三角法则和通道级遗忘,使其本身就成为了一种位置编码器。在处理信息时,它对序列的顺序和远近有着天生的敏感度,其通道级的多样性甚至比 RoPE 更灵活。
既然 KDA 已经把位置信息处理得明明白白,那穿插进来的 MLA 层干脆就不需要任何位置编码(RoPE)了。
而且这个NoPE设计不仅简化了模型,还解决了长上下文外推的问题。传统 RoPE 在处理比训练时更长的文本时,需要用到复杂的频率调整(如 YaRN),而 NoPE 则完全没有这个烦恼。
KDA 的位置编码因为Delta Rule是动态学习的,它可以自然地外推到更长的序列。只要继续按相同的规则更新状态即可。它证明了线性注意力可以内在地、自适应地学习位置信息。
首次全面超越全注意力,还不是特定场景,而是全维度碾压
论文摘要的第一句话就是:"线性注意力,第一次在公平比赛中性能超越了其他所有注意力机制"。
这个首次的含金量,在于它不是在某个特定场景下的超越,而是在严格公平对比下(相同参数量、相同训练数据 1.4T),在所有评估维度上的全面领先。
在传统的短上下文任务上,Kimi Linear 在 13/14 项任务中取得最佳成绩。
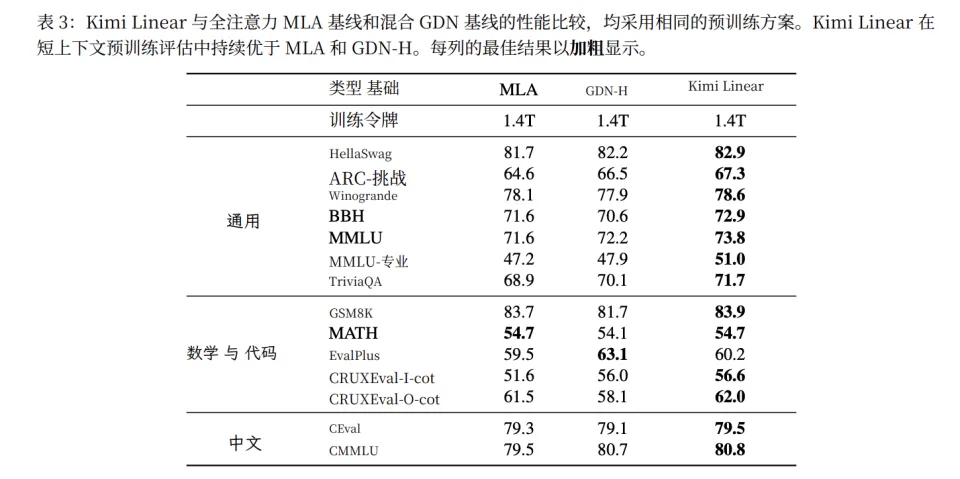
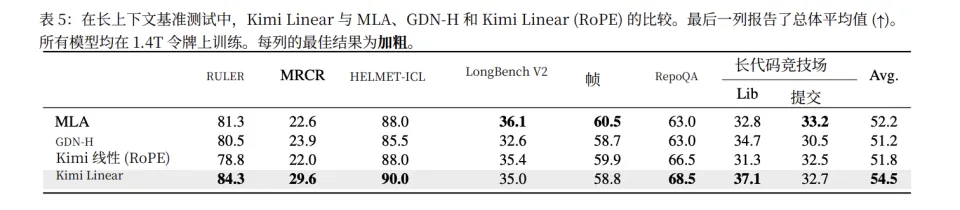
在长上下文中,特别是在 1M 上下文的 RULER 测试中,最终版的 Kimi Linear 达到了 94.8 分——这是一个在如此长上下文下极为罕见的高分。
最令人意外的,是 Kimi Linear 在 RL 训练阶段的表现。在相同的 RL 训练设置下,Kimi Linear 展现出了显著更快的收敛速度和更高的最终性能。
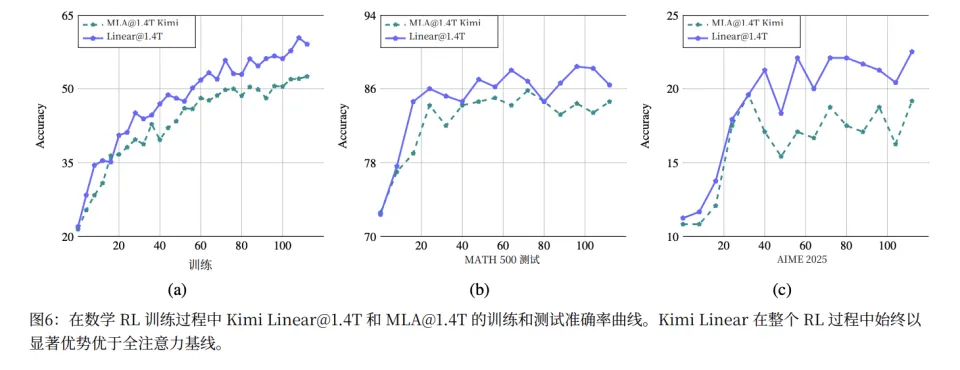
一个可能的解释是,KDA 的细粒度状态管理,天然适合增强学习中的 credit assignment问题。
而且在效率上,它更是实现了碾压。计算复杂度降低 75%,内存占用减少 75%,在 1M 长下文解码时,Kimi Linear 的吞吐量(速度)是全注意力的 6.3 倍。
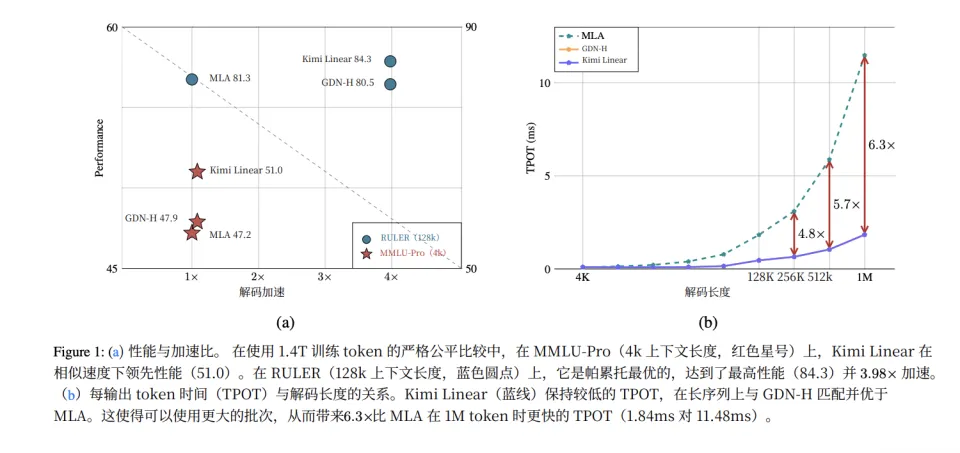
Kimi 团队还进行了 Scaling Law 实验,训练了 5 个不同规模的模型(653M 到 1.7B 激活参数)。
结果显示,Kimi Linear 的 Scaling Law 曲线比 MLA 更陡,在相同的 FLOPs 预算下能达到更低的损失。计算效率提升约 1.16 倍。
Kimi Linear 用这份报告证明,线性注意力不再是“妥协”。它在 KDA 细粒度门控的加持下,配合精妙的混合架构设计,已经成为一个在性能和效率上双重超越全注意力的新范式。
范式革新,也有代价
既然 Kimi Linear 这么强,后面所有大厂是否都可以立即做全线切换了?
然而,考虑到KDA地狱级的工程难度。即使切换,也得扒层皮。
因为KD最大的理论优势(通道级门控),在工程上给它带来了最大的噩梦:数值稳定性。
KDA 的数学公式,涉及到了大量的累积乘法和(隐式的)除法运算。当你在 GPU 上使用半精度浮点数(FP16/BF16)追求极致速度时,这些运算会变得极不稳定。因为一个数字除以一个接近零的数,计算结果就会是 NaN,这会使整个训练过程瞬间崩溃。
之前的研究(如 GLA)为了绕开这个地雷,被迫在对数域里进行计算,并且使用更慢的全精度(FP32)。但这又导致它们无法充分利用现代 GPU 专为半精度设计的张量核心(Tensor Cores),速度大打折扣。
因此Kimi Linear 的论文花了不少篇幅解释 KDA 的 DPLR(对角加低秩)变体。简单来说,Kimi 团队通过将两个关键变量都绑定到k值上,在数学层面将除法转化为乘法,让稳定性的问题被解决。
但这种全新的算法,意味着你无法用 PyTorch 或 TensorFlow 的标准库 pip install 来实现它。所以用 KDA,必须要手写定制化GPU核心,不能用标准库。
这还不是全部。KDA 这种“RNN-Transformer 混合体”,在训练过程和推理过程还得切换模式。训练时在“分块并行”(Chunkwise-Parallel)模式下,这样它才能像 Transformer 一样,利用 GPU 的并行性,一次性处理海量数据。而在推理时,它必须切换到“循环”(Recurrent)模式。这样它才能实现 KDA带来的恒定内存占用,享受 RNN 的极致推理效率。
要构建一个系统(比如在 vLLM 这样的框架中集成),让这两种截然不同的计算 Kernel 天衣无缝地协同工作,其工程复杂度同样相当高。
同时,KDA引入的许多新的超参数,其之间有复杂的相互作用,需要大量实验才能找到最优配置。论文中提到,他们的 Scaling Law 还有优化空间。这意味着即使是 Kimi 团队自己,也还没有完全"榨干" KDA 的潜力。
范式革命虽好,但代价也不菲。
不过,在 GPU 被“卡脖子”的时代,购买顶级硬件是一个无解的、不确定的问题。而 Kimi Linear 所代表的新范式,它的成本是有限的。它需要的是顶尖的工程人才、是时间、是深厚的算法功底。这些东西虽然稀缺,但它们是可以被解决的。
更重要的是,Kimi 团队已经开源了 KDA 的 Kernel 实现和 vLLM 集成,降低了后来者的门槛。
这不仅仅是对线性注意力的“救赎”。在 2025 年这个特殊的节点,这可能是 Kimi 为整个 AI 行业指出的一条,用“软件的确定性”去对抗“硬件的不确定性”的、真正可行的道路。
比起买不到的卡,用代码“造”出 6.3 倍的效率,这笔账,谁都算得过来。
线性注意力的妥协时代已经结束。超越的时代,正式开始。
论文地址:
https://github.com/MoonshotAI/Kimi‑Linear