告别「一条路走到黑」:通过自我纠错,打造更聪明的Search Agent
为了同时解决知识的实时性和推理的复杂性这两大挑战,搜索智能体(Search Agent)应运而生。它与 RAG 的核心区别在于,Search Agent 能够通过与实时搜索引擎进行多轮交互来分解并执行复杂任务。这种能力在人物画像构建,偏好搜索等任务中至关重要,因为它能模拟人类专家进行深度、实时的资料挖掘。
但 Search Agent 经常面临着一个棘手的瓶颈:缺乏过程中的自我纠错能力。现有的智能体一旦在推理早期因一个模糊的查询而走上错误的路径,就会基于这个错误结果继续执行,引发连锁式错误(Cascading Errors),最终导致整个任务失败。
为了攻克这一难题,腾讯内容算法中心联合清华大学,近期提出 ReSeek 框架,它不是对 RAG 的简单改进,而是对 Search Agent 核心逻辑的一次重塑。
ReSeek 的关键在于引入了动态自我修正机制,允许智能体在执行过程中主动评估每一步行动的有效性。一旦发现路径无效或信息错误,它就能及时回溯并探索新的可能性,从而避免「一条路走到黑」。

论文地址:https://arxiv.org/pdf/2510.00568
开源模型及数据集地址:https://huggingface.co/collections/TencentBAC/reseek
Github 地址:https://github.com/TencentBAC/ReSeek
连锁式错误:一步错,步步错
连锁式错误指的是,智能体在多步推理链的早期,哪怕只犯了一个微小的错误,也会像推倒第一块多米诺骨牌一样,导致后续所有步骤都建立在错误的基础之上,最终使整个任务走向完全失败。
这个过程可以分解为以下几个阶段:
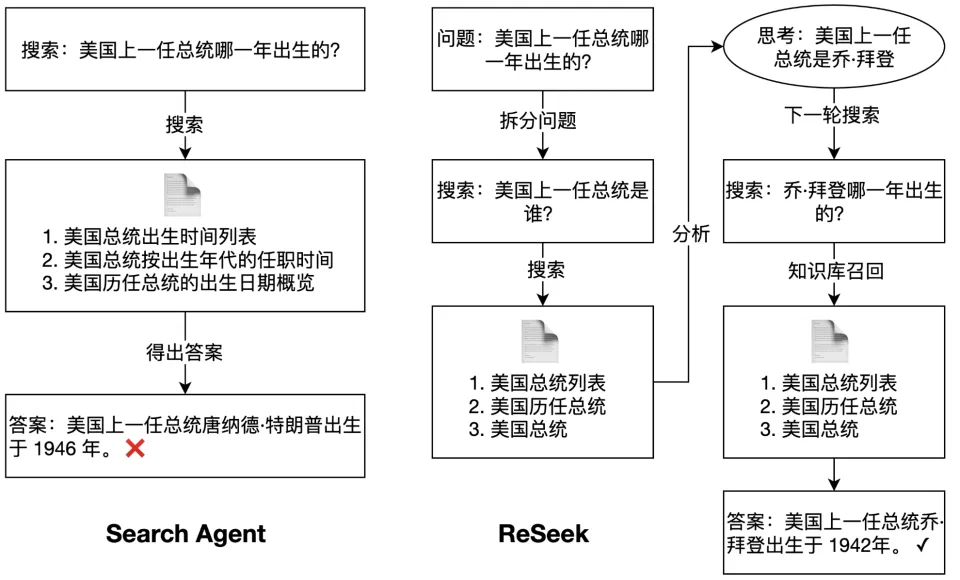
初始偏差:任务起点是「美国上一任总统哪一年出生的」?智能体没有先去识别 「上一任总统」是谁,而是直接将整个模糊问题扔给搜索引擎,这种跳过推理、依赖直接搜索的策略就是最初的偏差。
错误固化:搜索结果中可能同时出现了「特朗普」「总统」和「出生年份」等信息,智能体从中错误地提取并认定了「上一任总统就是特朗普」,它没有停下来验证这个信息的准确性,而是将这个未经证实的猜测固化为后续步骤不可动摇的事实依据。
无效执行:智能体基于「上一任总统是特朗普」这个前提,去执行搜索「特朗普的出生年份」的指令。接着智能体抓取了年份「1946」(这是特朗普的出生年份),这个执行步骤本质上是一次无效执行。
任务失败:最终,智能体给出了一个完全错误的答案:「美国上一任总统出生于 1946 年。」这个结果与事实(正确应为 1942 年)完全不符,它错误地将一个人的信息安在了另一个人身上,直接导致了任务的彻底失败。
根源何在?「执行者」而非「思考者」
为什么当前的搜索智能体会如此脆弱?根源在于它们在设计上更偏向一个「忠实的执行者」,而非一个「批判性的思考者」。
缺乏反思机制:智能体遵循一个线性的「思考 - 行动」循环(Think-Act Loop),但缺少一个关键的「反思 - 修正」环节(Reflect-Correct Loop)。它不会在得到中间结果后,与最初的目标和约束条件进行比对和审视,评估当前路径的合理性。
对中间结果的「盲信」:智能体将每一步的输出都视为不容置疑的「事实」,并将其直接作为下一步的输入。这种对中间结果的过度自信,使其无法从错误的路径中抽身。
因此,当前搜索智能体的脆弱性在于其推理链的刚性。它擅长沿着一条既定路线走到底,却不具备在发现路走不通时,掉头或另寻他路的能力。要让智能体真正变得鲁棒和可靠,未来的关键突破方向在于:赋予智能体自我反思和动态纠错的能力,让它从一个只会「一条路走到黑」的执行者,进化成一个懂得「三思而后行、及时止损」的思考者。
让 Agent 具备元认知能力
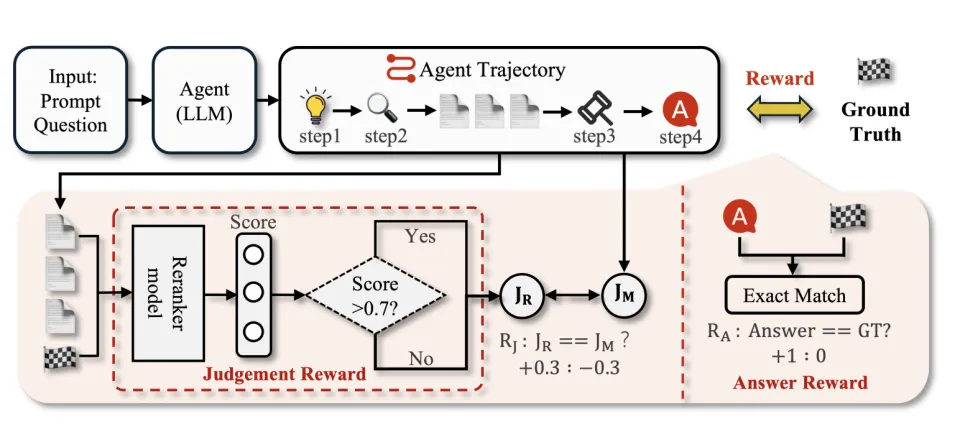
为了赋予智能体自我反思和动态纠错的能力,团队扩展了 Agent 动作空间,引入了一个核心的 JUDGE 动作。该动作在每次信息获取后被调用,用于评估新信息的有效性。
这个机制的关键在于对历史信息的选择性关注 (selective attention to history),而非复杂的状态回溯。在每个时间步 t,智能体首先执行一个动作(如 Search)并获得一个观察结果 。随后,它执行 JUDGE 动作,输出一个判断
 。这个判断将决定
。这个判断将决定是否被纳入后续决策的上下文中。
具体而言,智能体在生成下一步动作时所依赖的上下文
是动态构建的:
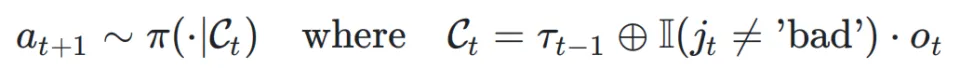
这里表示到上一步为止的有效轨迹历史,
是指示函数,
代表上下文的拼接操作。
当 JUDGE 的判断不为 'bad' 时,当前观察到的信息
会被追加到历史中,为后续决策提供证据。反之,若判断为 'bad',该信息将被忽略,智能体将仅基于之前的有效历史
进行下一步规划。这一机制使得智能体能够主动过滤掉无效或误导性的信息,并在一个已知的「好」状态上重新尝试,从而有效阻断错误链条。
自我纠错的奖励函数设计
为了让策略网络学会做出准确的判断,JUDGE 动作需要有效的学习信号。为此,团队设计了一个密集的中间奖励函数,专门用于训练智能体的自我评估能力。
其核心思想是:当智能体的判断与一个客观的「理想判断」
一致时,给予正奖励;反之则给予惩罚。
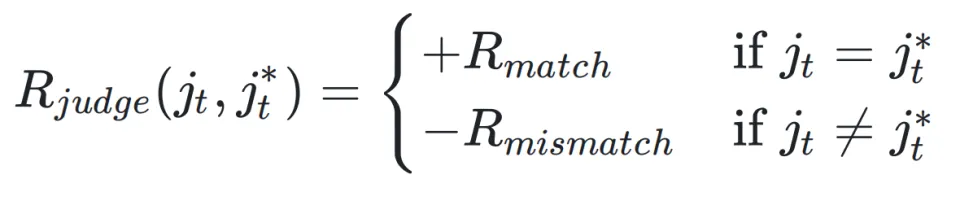
这里的挑战在于如何确定理想判断。团队通过一个外部的重排模型(Reranker)来近似生成该标准。具体来说,计算当前观察信息
与问题标准答案(Ground-Truth Answer)之间的语义相关性得分
 。该得分随后被映射到一个离散的标签('good' 或 'bad'),作为
。该得分随后被映射到一个离散的标签('good' 或 'bad'),作为的近似。
这种奖励塑造(Reward Shaping)策略为智能体提供了密集的、步进式的反馈,引导其逐步学会如何准确评估信息价值,从而使 JUDGE 动作真正有效。
FictionalHot 基准的构建
为了公正且严格地评估智能体的真实推理能力,团队构建了 FictionalHot 数据集。其核心目标是创建一个封闭世界(closed-world)的评测环境,以消除预训练模型因「记忆」了训练数据而带来的评估偏差(即「数据污染」问题)。
构建流程如下:
采样与改写:从现有的问答数据集中采样种子问题,并利用大模型对问题进行改写,将其中所有真实世界的实体(人名、地名、事件等)替换为虚构实体,同时保持原问题复杂的推理结构不变。
生成虚构知识:为每一个虚构实体生成对应的、维基百科风格的说明文档。这些文档是解决新问题的唯一事实来源。
构建封闭知识库:将这些生成的虚构文档注入到一个标准的维基百科语料库中,形成一个封闭且受控的知识环境。
通过这种设计,FictionalHot 迫使智能体必须依赖其程序化的搜索、整合与推理能力来解决问题,而不是依赖其参数中存储的先验知识。这样能够更干净、更准确地评估 ReSeek 框架在提升智能体核心能力方面的真实效果。
多数研究实验设置不一致
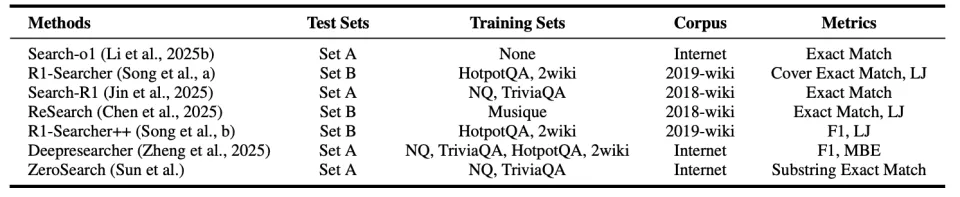
当前,对 Search Agent 的评估面临着实验设置的不一致的挑战。现有研究在多个关键方面存在差异:
知识库 (Corpus): 使用的知识源各不相同,从静态的维基百科快照(如 2018、2019 年版)到无法复现的实时互联网,差异巨大。
测试集 (Test Sets): 有的研究使用涵盖多种任务的广泛测试集(如 NQ, TriviaQA 等,集合 A),有的则专注于需要复杂推理的多跳问答任务(如 HotpotQA, Musique 等,集合 B)。
训练方式 (Training Regimes): 模型的训练策略也五花八门,从完全不训练,到在单个或多个不同数据集上进行训练。
评估指标 (Metrics): 评估标准同样不统一,涵盖了从精确匹配(Exact Match)和 F1 分数,到使用大模型作为评判者(LLM-as-a-judge, LJ)等多种方式。
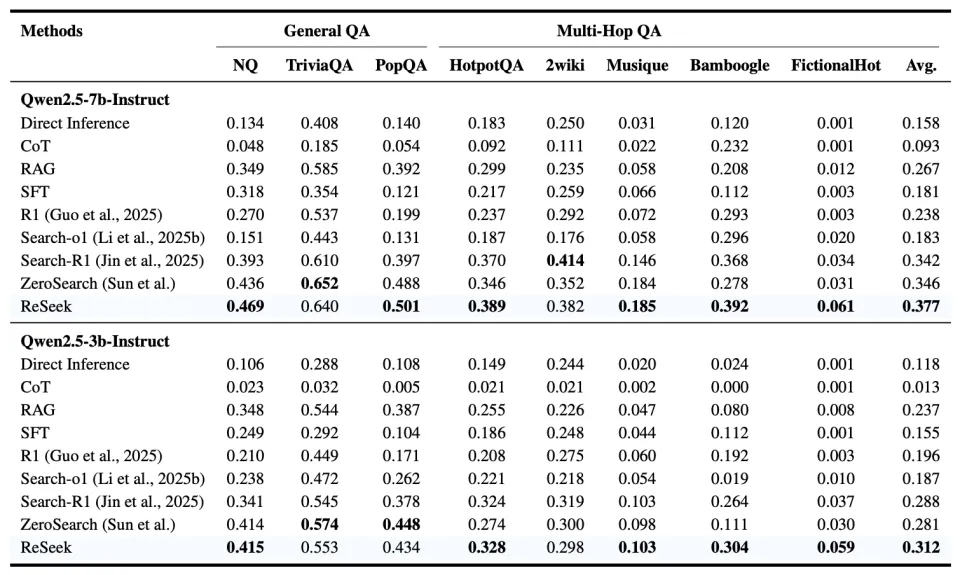
为了确保公平的比较,Reseek 采用了最普遍的训练方法,在 NQ 和 TriviaQA 的训练集上进行训练,并采用精确匹配(Exact Match, EM)作为主要评估指标。该模型在 7 个主流的公开问答数据集上进行了测试,涵盖了从简单事实查询到复杂多跳推理(如 HotpotQA)的各种任务。
此外,Reseek 还在自建的 FictionalHot 数据集上进行了测试。该数据集通过虚构内容,彻底杜绝了 “数据污染” 问题,能够更公平地评估模型的真实推理能力。
主要结果
实验结果表明,ReSeek 在 3B 和 7B 参数规模上均达到了业界领先的平均性能。该模型在 HotpotQA 和 Bamboogle 等需要复杂多跳推理的基准上优势尤为突出,这证明了其自我纠错范式在处理复杂问题上的高效性。
在 FictionalHot 基准上的测试揭示了一个关键现象:模型规模(7B vs. 3B)对性能的影响显著减小。这表明 FictionalHot 成功地消除了模型因规模增大而产生的记忆优势,从而能够更准确地衡量其程序化推理能力,凸显了该基准的评估价值。
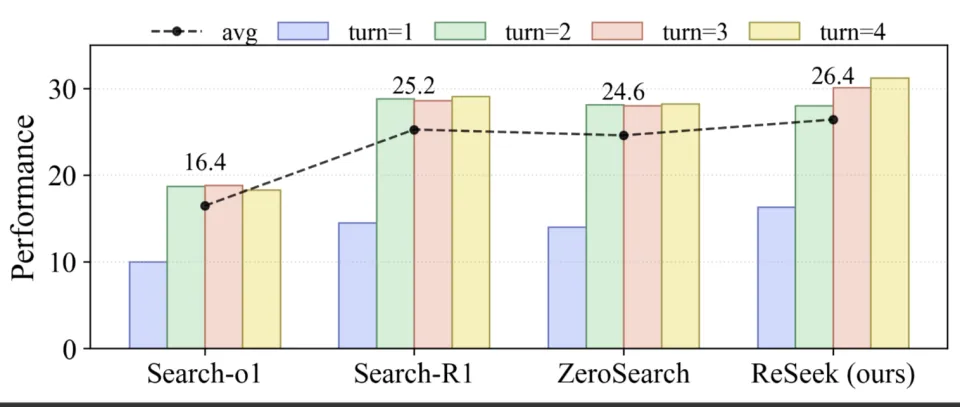
交互轮次越多,模型效果越好?
为了分离行动预算(action budget)的影响并检验模型的迭代式自我纠错能力,团队对最大交互轮数(turns)进行了消融实验。此处的「交互轮数」定义为模型为单个查询可执行的最大动作次数。该设置旨在验证额外的动作步骤能否帮助模型复核证据、修正假设,或者其性能是否在一次「搜索 - 回答」的最小循环后即已饱和。
如下图,基线模型(baselines)的性能从一轮增至两轮时有显著提升,但在三轮和四轮时几乎停滞,这与其典型的两步工作流(搜索后回答)相符。
相比之下,ReSeek 的性能从一轮到四轮单调递增,展现了更强的自我纠错能力:当交互轮数更充裕时,它会在不确定时重新查询证据、优化规划并修正答案。平均性能也印证了这一趋势,ReSeek 取得了最高的平均分,证明该方法能将更多的交互预算转化为真实的性能增益,而非冗余操作。
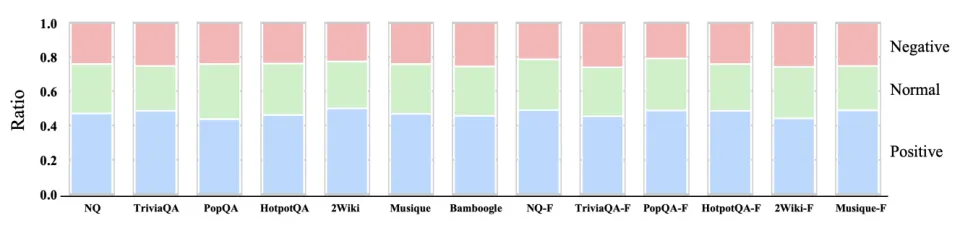
JUDGE 机制到底有没有用?
为了更深入地理解判断器(Judge)机制在具体案例中的作用,而不仅仅是看最终的宏观分数,团队对其行为进行了细致的逐例分析。根据判断器干预所产生的实际效果,将其分为三类(见下图):
积极影响 (蓝色): 这类情况代表判断器的干预带来了明确的好处。例如:(1) 当模型状态能够导向正确答案时,判断器正确地给出了「是」的信号;(2) 当检索到的信息不包含答案时,判断器正确地给出「否」的信号,成功阻止了模型被错误信息干扰。
负面影响 (红色): 这类情况代表了判断器的干预起到了反作用。具体来说,就是判断器发出了「是」的信号(认为当前信息足以回答问题),但模型最终还是给出了错误答案。
中性影响 (绿色): 其余所有情况归为此类,表示判断器的作用不明确或为中性。
分析结果非常清晰:在全部的测试上,「积极影响」 的比例都非常高,稳定在 40-50% 之间。相比之下,「负面影响」的比例最低,通常不到 25%。正面与负面影响之间的这种显著差距,充分证明了该设计的有效性。这一质性证据表明,判断器是整个框架中一个可靠且高效的关键组件。
展望
ReSeek 框架的核心价值在于为复杂的业务场景提供高可靠性的决策支持。在需要实时数据或热点理解等领域,简单的「检索 - 生成」已无法满足需求。这些任务不仅要求信息实时,更要求推理过程的严谨无误。ReSeek 的自我纠错机制,正是为了解决这一痛点,通过赋予 Agent「反思」和「修正」的能力,显著降低因单点错误导致全盘失败的风险,提升复杂任务的成功率。
当然,通往通用智能 Agent 的道路充满挑战。当前的训练数据还不充分,距离实际落地还有一定距离,还面临一些有待解决问题和算法挑战, 相信在未来,Search Agent 能够作为一种基本的 Agent 范式,服务于每一位用户。