视频生成Prompt何须仅是文字!字节&港中文发布Video-As-Prompt
本工作由第一作者在字节跳动智创北美团队实习期间完成。第一作者卞宇轩目前为香港中文大学计算机科学与工程系博士二年级学生,研究方向为可控视频生成,师从徐强教授,并曾在字节跳动、腾讯等公司实习。个人主页:https://yxbian23.github.io/
视频创作中,你是否曾希望复刻变成 Labubu 的特效,重现吉卜力风格化,跳出短视频平台爆火的同款舞蹈,或模仿复杂有趣的希区柯克运镜?
在现在的 AI 视频生成中,这些依赖抽象语义控制的创作,因缺乏统一的条件表征,实现起来往往异常困难。
最基础和直接的想法是针对每一种抽象语义单独训练 LoRA 或针对某一类语义条件设计专门的模型架构完成针对性的特征提取和可控生成。
然而,语义条件可能无穷无尽,一个条件训练一个模型会导致实际使用非常复杂,计算消耗非常庞大,且面对未曾训练的其他语义条件,模型没有任何泛化性能;针对某一类语义设计模型架构一定程度上在单独子集解决了这个问题(例如:相机控制,风格迁移),但面对着不同语义类别,仍需要不断切换模型,其任务专一的设计也无法完成不同语义类别的统一建模,阻碍了统一模型和模型规模化的进展。
为了解决这一痛点,香港中文大学与字节跳动团队联合提出了一种全新的语义可控的视频生成框架 Video-As-Prompt。它引入了一种「视频参考」的新范式,用户只需提供一段参考视频和对应的语义描述共同作为 prompt,模型就能直接「克隆」指定语义并应用于新内容,从根本上实现了抽象语义下可控视频生成范式的统一。
该工作的训练、推理代码和目前最大的高质量多语义数据集均已开源。该工作所提出的数据集规模宏大,包含超过 100K 视频,覆盖超过 100 个不同的高质量语义条件。

论文标题:Video-As-Prompt: Unified Semantic Control for Video Generation
项目主页:
论文:
Demo:
模型:
数据集:
代码:
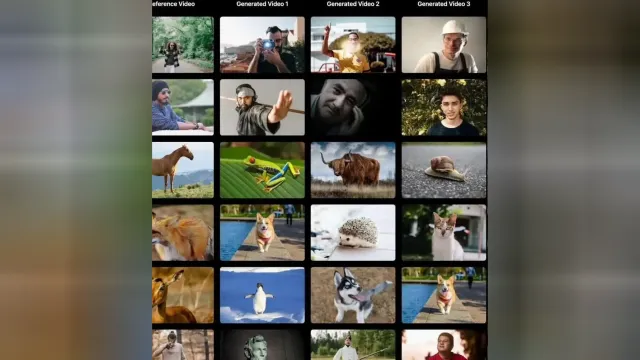
Video-As-Prompt 能力展示
Video-As-Prompt 支持四大类复杂语义的克隆和迁移:复杂概念、艺术风格、指定动作和相机运镜,基于其强大的克隆能力,Video-As-Prompt 衍生出诸多应用:
用包含不同语义的不同参考视频驱动同一张图片:

用包含相同语义的不同参考视频驱动同一张图片:
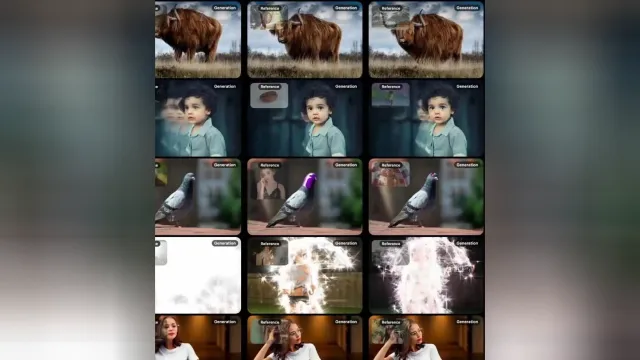
用同一个参考视频驱动不同图片:
结合文本实现语义编辑:

更多的 demo 效果请参考项目主页。
Video-As-Prompt 算法解读
实现一个统一的语义可控视频生成模型的关键就在于:
如何构建统一的语义条件表征
如何在语义条件表征和生成视频之间建立有效的语义信息映射
如何找到可扩展的架构以实现高效训练
Video-As-Prompt 通过让具有指定语义的参考视频充当生成上下文 prompt,实现了抽象语义条件下的统一可控视频生成。
语义条件表征
提出使用参考视频作为统一的抽象语义条件表征,无需针对不同语义进行分类和设计针对编码模型,大大提升了模型架构的通用性、可拓展性,同时降低了用户使用的难度。
语义信息映射
将参考视频当作「视频 prompt」,从 in-context generation 的角度完成统一的语义映射。
可扩展的架构
直接训练视频生成基模通常会导致在数据有限的情况下发生灾难性遗忘。为了稳定训练,研究者采用 Mixture-of-Transformers(MoTs):一个冻结的视频扩散 Transformer(DiT)加上一个从主干初始化的可 trainable 并行专家 Transformer 联合建模。
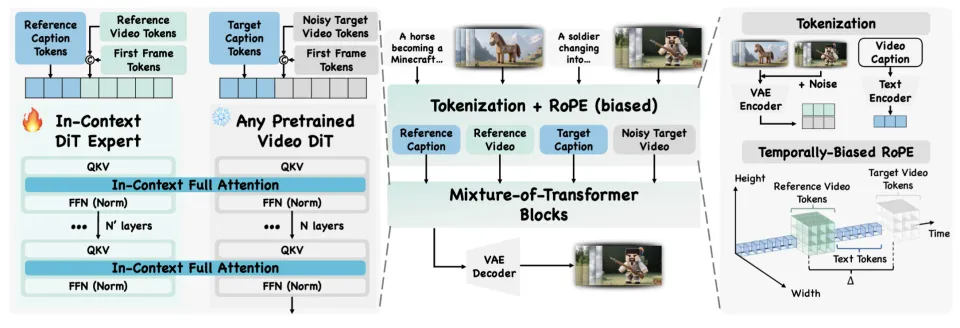
具体来说,专家处理参考视频代表的语义条件 tokens,而冻结的 DiT 处理待生成的视频 tokens。每个 DiT 都保留各自的 Q、K、V 投影、前馈层和归一化层;在每一层连接两部分的 Q/K/V,并运行全注意力机制,以实现双向信息融合和上下文控制。
Video-As-Prompt 实验结果
为了支持统一的语义控制视频生成,研究者构建并发布了 VAP-Data 用于促进相关研究大规模训练,和对应的 Benchmark 用于公平评测,这是目前开源用于语义可控视频生成的最大数据集,其中包含超过 100 个语义条件下的 100K 个精选配对视频样本。

研究人员主要和两类方法进行了比较:
统一的结构化控制视频生成:VACE 的三个变体(分别采取原始参考视频,参考视频的深度、光流作为控制条件)
离散的语义控制视频生成:原始的视频 DiT 基座,视频 DiT 基座 + 针对每种语义单独训练 LoRA,Kling/Vidu 等商业 API
总体而言,Video-As-Prompt 的性能在整体视频质量、文本一致性、语义一致性(Gemini-2.5-Pro 判别)和人工偏好上都与闭源模型 Kling/Vidu 相当并优于其他开源基线,并且是首个针对所有语义条件统一控制且可扩展和推广的模型。
并且,通过将所有语义条件视为统一的视频提示,Video-As-Prompt 支持多种语义控制的生成任务。此外,当给定一个不属于训练数据的语义参考时,从参考视频建模范式中学习到的上下文生成能力使 Video-As-Prompt 能够执行由新语义参考引导的零样本生成,这超越了之前所有的方法,并为未来的统一可控生成提供了新的可能。

左边为训练时完全不曾见过的相关语义参考视频,右边为 zero-shot 推理结果
总结
Video-As-Prompt 是一个统一的、语义控制的视频生成框架,它提出参考视频克隆生成的生成范式,将参考视频视为 video prompt,并通过 Mixture-of-Transformers 实现即插即用的上下文控制,提供了可扩展的语义控制和零样本泛化能力。其统一的参考视频建模(「Video-As-Prompt」)框架,验证了基于参考视频的可控生成这一思路的巨大潜力。
同时,开源的大规模视频参考生成数据集也将为社区的相关研究提供强有力的数据支持,有望推动 AIGC 视频创作进入一个生成更可控、语义更丰富的新阶段。