韩松等提出FlashMoBA,比MoBA快7.4倍,序列扩到512K也不会溢出
机器之心编辑部
今年 2 月,月之暗面提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。
据介绍,MoBA 是「一种将混合专家(MoE)原理应用于注意力机制的创新方法。」该方法遵循「更少结构」原则,并不会引入预定义的偏见,而是让模型自主决定关注哪些位置。
MoBA 在处理长上下文时表现出极强的潜力,它允许 Query 只稀疏地关注少量 Key-Value 块,从而大幅降低计算成本。
然而,目前业界对 MoBA 性能背后的设计原则仍缺乏深入理解,同时也缺少高效的 GPU 实现,这限制了其实际应用。
在这篇论文中,来自 MIT、NVIDIA 机构的研究者首先建立了一个统计模型,用于分析 MoBA 的内部机制。模型显示,其性能关键取决于路由器是否能够基于 Query-Key 的相似度,准确区分相关块与无关块。研究者进一步推导出一个信噪比,将架构参数与检索准确率建立起形式化联系。
基于这一分析,本文识别出两条主要的改进路径:一是采用更小的块大小,二是在 Key 上应用短卷积,使语义相关信号在块内聚集,从而提升路由准确性。
然而,尽管小块尺寸在理论上更优,但在现有的 GPU 实现中,小块会导致严重的内存访问碎片化和低并行度,速度甚至慢于稠密注意力。
为解决这一矛盾,研究者进一步提出了 FlashMoBA,一种硬件友好的 CUDA kernel,可在小块配置下仍然高效地执行 MoBA。
结果显示优化后的 MoBA 在性能上可与密集注意力基线相匹敌。对于小块场景,FlashMoBA 相比 FlashAttention-2 可实现最高 14.7 倍加速。

论文地址:https://arxiv.org/pdf/2511.11571
项目地址:https://github.com/mit-han-lab/flash-moba
论文标题:OPTIMIZING MIXTURE OF BLOCK ATTENTION
FLASHMOBA:一种面向小块 MoBA 的优化内核
理论模型表明,较小的块尺寸能带来显著的质量提升,但朴素的 GPU 实现效率低下。由月之暗面发布的原始 MoBA 实现,在配置小块尺寸时会遭遇性能瓶颈,这些瓶颈抵消了稀疏性带来的计算节省,导致执行速度比稠密注意力更慢。
研究者推出了 FlashMoBA,这是一种硬件感知的 CUDA 内核,旨在使小块 MoBA 变得实用且高效。
小块带来的性能挑战
小块尺寸引入了几个关键的性能挑战,要在实际部署中应用必须解决这些问题。
首先,在为每个查询收集稀疏、不连续的键值块时,会出现低效的内存访问,导致从 HBM 读取数据时出现非合并内存读取。
其次,随着较小的块尺寸 导致路由器必须评分的块数量(
)增加,Top-k 选择和门控的开销变得棘手。原始实现显式生成了一个巨大的
分数矩阵,产生了巨大的内存开销。
最后,由于每个块的工作量减少以及启动大量独立内核的开销,导致 GPU 占用率低,进而造成并行度差和硬件利用率低。
FLASHMOBA 内核设计
为了克服这些挑战,FlashMoBA 采用了三个融合内核,以最大限度地减少 HBM 往返次数,并使计算与 GPU 架构相对齐,如图 1 所示。
分块 Top-K 选择
Top-k 选择过程是原始 MoBA 实现中的主要瓶颈,该实现显式生成了完整的分数矩阵并串行处理批次序列。研究者将其替换为 Flash TopK(图 1 中的步骤 1),这是一个由融合内核组成的高度优化的三阶段流水线。
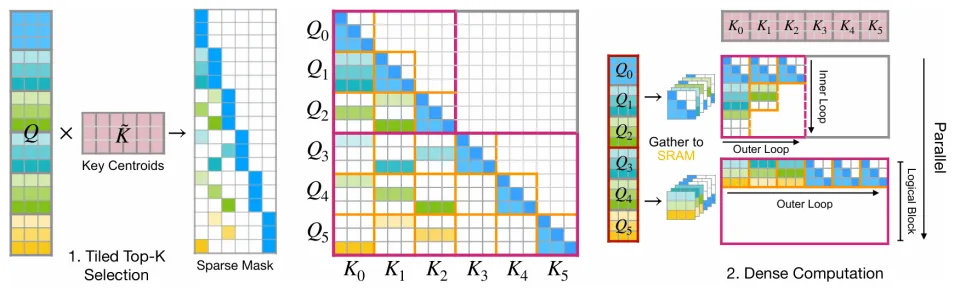
首先,一个 Triton 内核计算键块的质心,生成一个更小的矩阵 。
其次,受 FlashAttention-2 启发的分块内核通过计算和
之间的分数来为每个查询找到 Top-k 个键块,且无需将完整的分数矩阵显式写入 HBM,如算法 3 所述。

最后,一个高效的后处理步骤将以查询为中心的索引重新格式化为以键块为中心的变长布局,以便进行主注意力传递。整个流水线在批次和注意力头之间完全并行化,消除了原始的性能瓶颈。
采用「收集并致密化」策略的前向传播
为了处理 MoBA 的不规则稀疏性,前向内核使用了一种基于两级分块机制的「收集并致密化」策略,详见算法 1。

要区分两种类型的块:
逻辑块:内核在其外层循环中迭代的大型连续查询块和键块
。一个逻辑键块对应一个 MoBA 键块。
物理块:加载到 SRAM 中用于矩阵乘法的较小图块(Tiles,例如或
。它们的最佳尺寸取决于 GPU 架构和注意力头的维度。
内核将一个逻辑查询块分配给每个线程块,并遍历所有逻辑键块
。对于每一对块,它使用变长索引来查找相关的查询。该子集被分批处理成稠密的物理块:从 HBM 收集物理查询块并放入稠密 SRAM 缓冲区进行计算。
这种两级方法是关键所在,因为在 SRAM 中缓存查询允许在逻辑键块的所有物理图块之间复用数据,从而通过高效的稠密 GEMM(通用矩阵乘法)分摊昂贵的不规则内存访问成本。
带重计算的反向传播
反向传播利用了 FlashAttention-2 的内存高效设计,并实现为三个内核的序列(算法 5)。

主内核在键维度上并行化计算,每个线程块处理一个键块。为了处理稀疏性,它镜像了前向传播的「收集并致密化」策略,使用变长索引收集查询子集并将梯度输出到片上图块中。
遵循 FlashAttention-2 的方法,研究者在反向传播期间重计算注意力分数,以避免将完整的注意力矩阵存储在内存中。虽然键和值的梯度直接写入 HBM,但部分查询梯度需要跨多个键块进行累加,这是通过对高精度全局缓冲区使用原子加法来高效且安全地处理的。
这种设计确保了反向传播在序列长度上保持线性复杂度,这是相对于标准注意力的二次复杂度的一个关键改进。由于反向传播通常构成优化注意力实现的主要性能瓶颈(通常比前向传播慢 2-3 倍),因此我们需要反向内核的高效率对于实现长序列的实际训练至关重要。
实验及结果
本文从零开始预训练模型,并进行可控实验来验证 MoBA 的设计原则。实验共训练了两个模型,所有实验均在 8× H100 80GB GPU 上完成:
340M 参数模型(hidden size 1024,16 heads,中间层规模 2816);
1B 参数模型(hidden size 2048,32 heads,中间层规模 8192)。
质量评估结果
本文在语言建模、长上下文检索以及真实任务上对 MoBA 的表现进行了评估。实验结果表明,改进后的模型在多种基准测试中提高了性能。
首先是块大小的影响。图 2 展示了块大小对 340M 模型在 WikiText 困惑度(perplexity)和 RULER 准确率上的影响。正如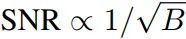 的理论预测,将块大小从 512 缩小到 128,使困惑度从 20.9 降至 19.7,RULER 准确率从 38.8% 提升到 56.0%。更小的块能够帮助路由器更精准地识别相关内容。
的理论预测,将块大小从 512 缩小到 128,使困惑度从 20.9 降至 19.7,RULER 准确率从 38.8% 提升到 56.0%。更小的块能够帮助路由器更精准地识别相关内容。
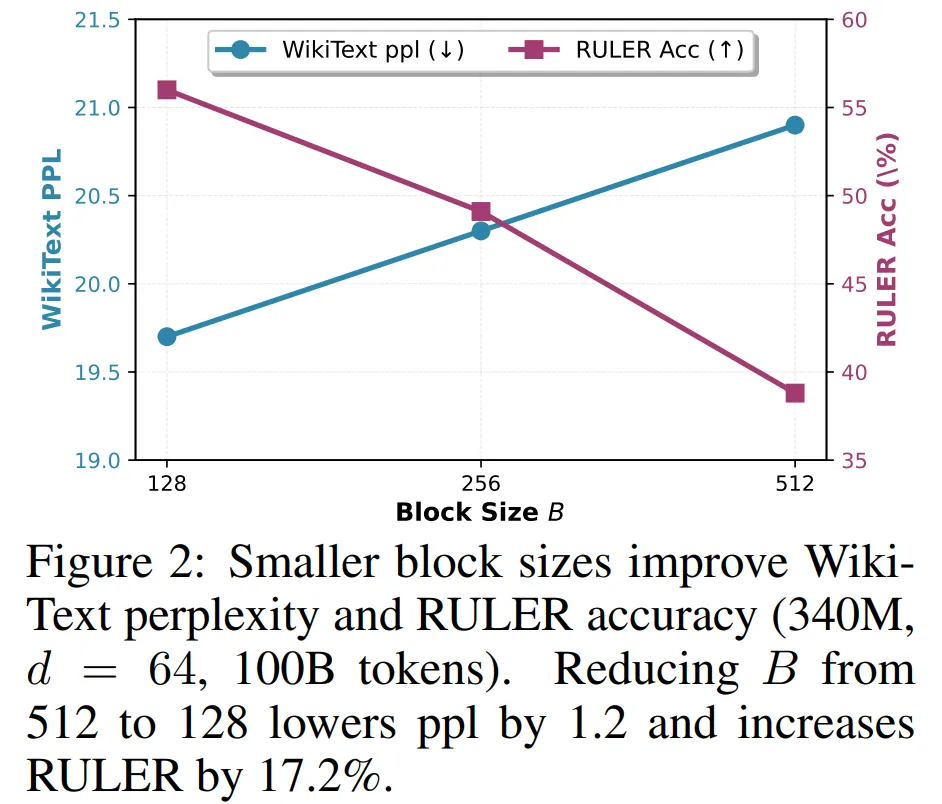
这一趋势在所有基准和不同模型规模上都保持一致。对 340M 模型来说,将块大小从 512 缩小到原来的 1/4 到 128,可带来如下提升:
语言建模准确率从 44.6% 提升到 45.6%(表 1);
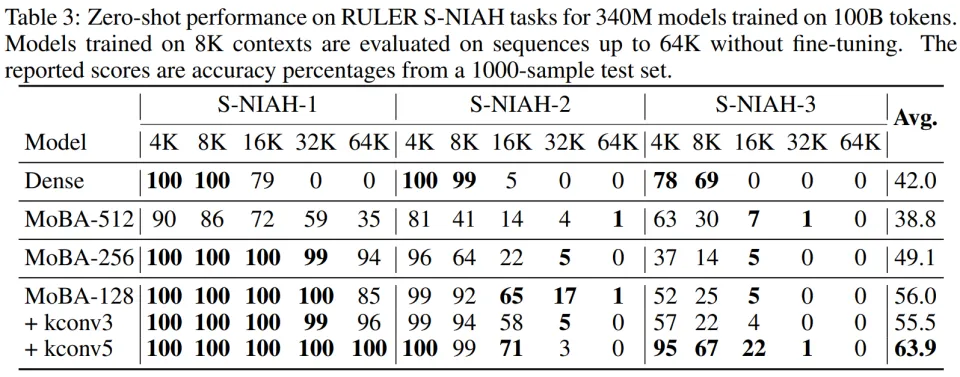
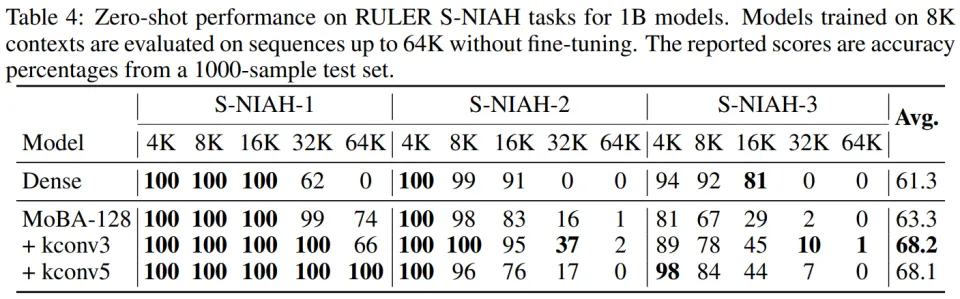
RULER 准确率从 38.8% 提升到 63.9%(表 3);
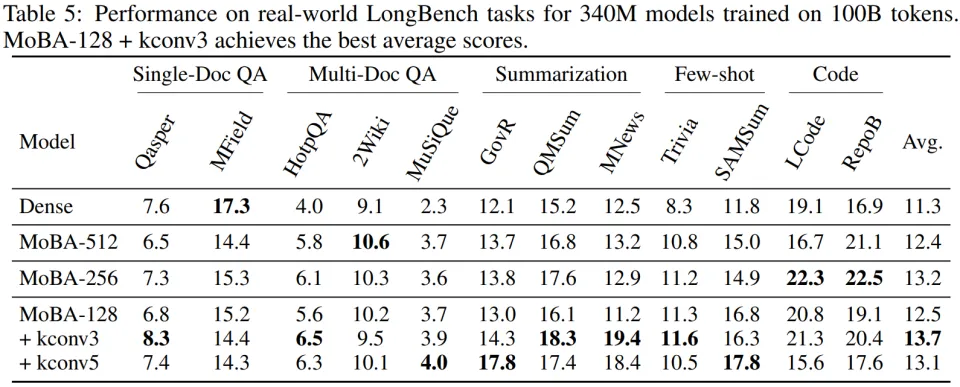
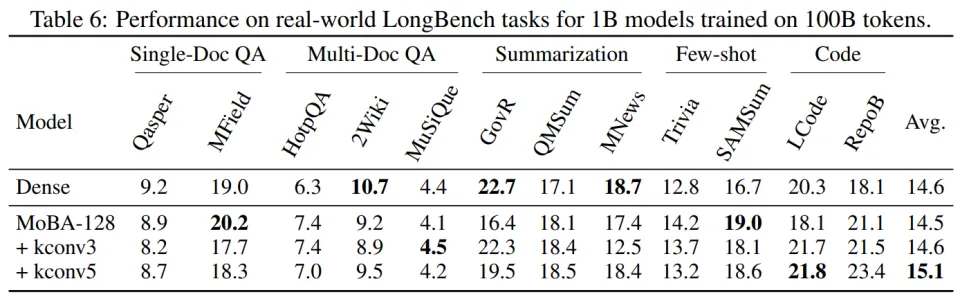
LongBench 综合得分从 13.2 提升到 15.3(表 5)。
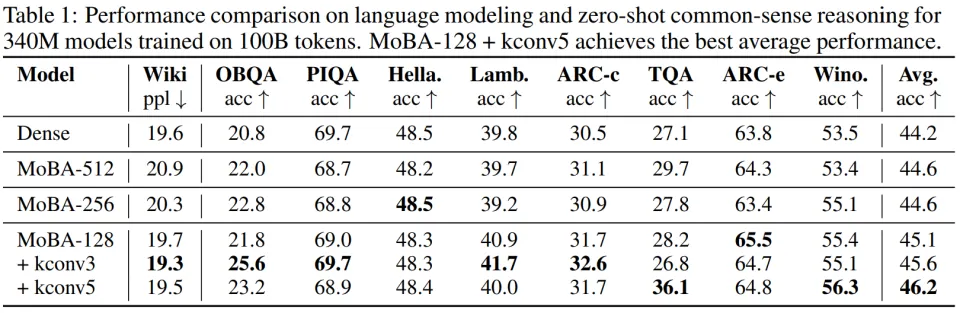
总体来看,小块尺寸对于 MoBA 达到与密集注意力相当的性能是必要的。
Key Convolution 。Key Convolution 在不同任务中都能带来性能提升,而且具有任务偏好特性。对于 340M 模型:
kconv3 将语言建模准确率从 45.1% 提升到 45.6%(表 1);
kconv5 在 64K 长度检索任务中达到 100% 的检索率(表 3);
在 LongBench 上,kconv3 得分达到 15.3%(表 5)。
对于 1B 模型:
kconv3 将语言建模准确率提升到 52.7%(表 2);
将 RULER 准确率提升到 68.2%(表 4)。
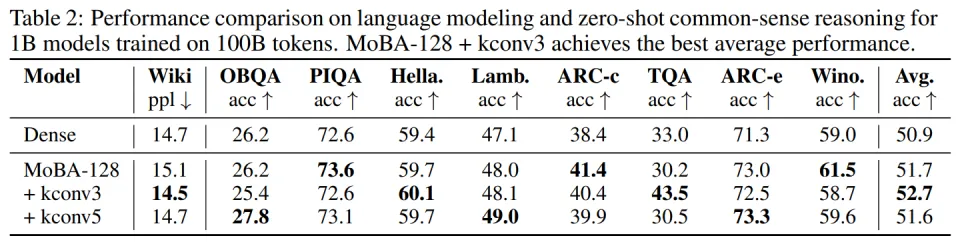
这些结果表明,卷积通过使相关 token 在块内聚集,提升了有效均值差异 ,从而显著提高路由准确性。
注:卷积核宽度 W∈{3,5},分别记作 kconv3 和 kconv5。
稀疏匹配密集注意力机制。在多个基准测试和规模下,MoBA 的表现与密集注意力机制相当甚至更胜一筹。
效率结果
虽然理论上小块尺寸能够带来更高的模型质量,但此前由于 GPU 利用率低下,小块一直难以在实际中使用。FlashMoBA 的出现让这些配置真正变得可行。
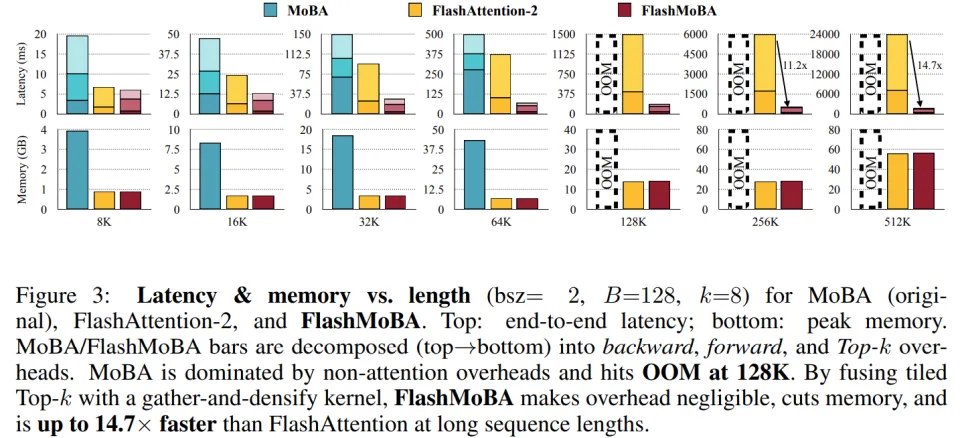
端到端性能。图 3 对比了不同序列长度(8K 至 512K token)下的延迟和内存占用。FlashMoBA 在两项指标上都显著优于原始实现。
在 N=64K 且 B=128 的配置下:FlashMoBA 比原始 MoBA 快 7.4 倍,内存占用减少 6.1 倍,原始 MoBA 在 128K 序列就会 OOM(内存溢出),而 FlashMoBA 能扩展到 512K。
随着序列越长、块越小,优势更明显,因为 FlashMoBA 消除了全局 reindex 的开销,在长序列条件下可实现最高 14.7× 快于 FlashAttention-2 的速度。
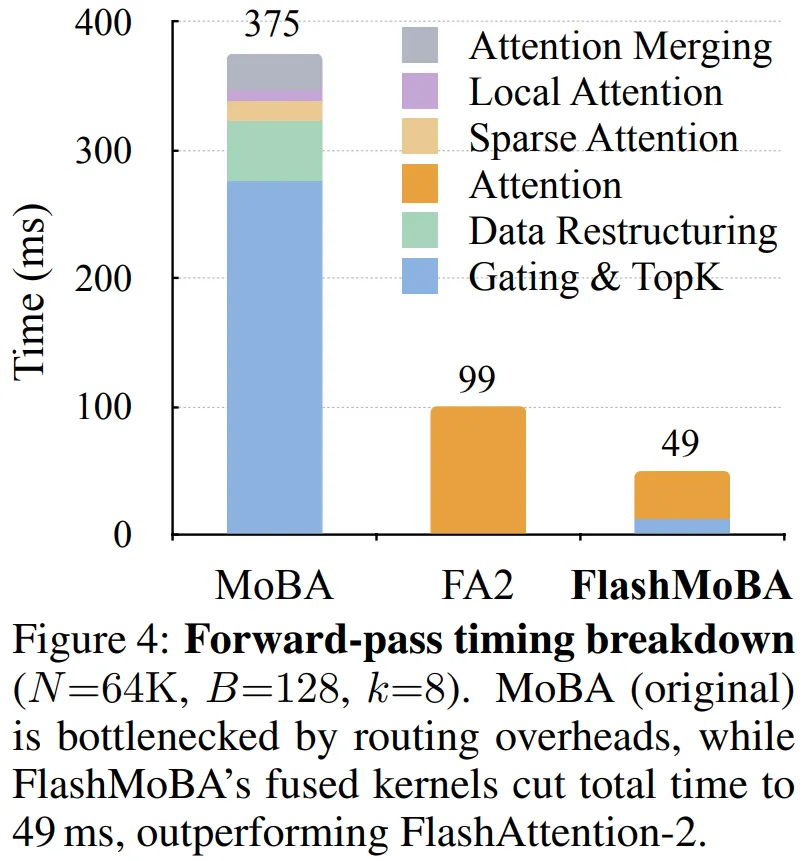
为了理解 FlashMoBA 的提速来源,图 4 展示了在 N=64K 下前向传播的耗时分布。
原始 MoBA 包含 5 个阶段:(1)计算质心并执行 top-k、(2)全局 reindex、(3)在路由后的索引上执行注意力、(4)局部因果注意力以及(5)合并结果。
其中步骤 (1)、(2)、(5) 占据了超过 70% 的执行时间。
FlashMoBA 则使用两个融合 kernel,这种融合设计将 64K 序列下的前向传播时间降至 49 ms,而 FlashAttention-2 在相同设置下为 99 ms。