AI智能体2025大翻车:Surge AI深度拆解,GPT-5也通不过工作试用期
文|博阳
编辑|郑可君
2025年本应是AI智能体的元年。
但Karpathy在之前的采访中,却表示Agent至少需要五年,才能逐步落地。
在Agent已经能够很好的分解任务、利用MCP使用工具的当下,它和人的差距到底还有多大?
Surge AI,一家从事AI数据和评测的公司,刚给这个愿景泼了一盆冷水。
他们发布了一篇《RL环境与智能体能力金字塔》的报告,核心结论就是,AI智能体,现在根本不行。

他们选择了包括GPT-5和Claude Sonnet 4.5,乃至刚出的Kimi K2等九个当今最前沿的AI模型,把它们扔放进一个模拟的真实工作环境,去处理150个任务。
结果,即使是GPT-5和Claude 4.5这样的顶级模型,也搞砸了超过40%的任务。
报告的一句话总结更是毫不留情:“大多数AI几乎语无伦次,即使是最好的模型也缺乏常识。”
除了测试之外,这份报告还系统性地定义了AI智能体通往智能的路径,并具体指出了它们在每一层上是如何摔得鼻青脸肿。
现在,我们就来万字拆解这份报告,看看Agent离真正有用,到底还差多远。
Agent们,欢迎来到Corecraft, Inc.虚拟公司
为了测试Agent,Surge AI构建了一个复杂的强化学习环境,名字叫“Corecraft, Inc.”。
Corecraft是一家虚构的高性能PC零件和定制电脑的在线零售商。它有自己的世界模型(公司架构)、实体(客户、订单、支持工单、数据库)和一套工具系统(AI用来交互的API)。
而AI模型们扮演的角色很简单,就是客服。
客服可是AI Agent最先落地的领域之一,也是大家觉得会最先取代人类员工的领域。但别小看这个角色,它其实完美地横跨了AI能做和不能做的全部光谱。
里面有AI擅长的简单的数据库查询,比如“今年7月有多少笔退款”这类需求,还有非常复杂的,需要联动各种能力的需求。
比如,“一个客户下了个单,但在最后审查时收到了兼容性警告。他订了ZentriCore Storm 6600X CPU、SkyForge B550M Micro主板和32GB HyperVolt DDR5-5600内存。系统标记了不兼容。你能帮我看看是哪里出了问题,并建议一个最便宜的修复方案吗?"
靠着它,AI究竟能完成多少有经济价值的工作就可以在这个Corecraft, Inc.虚拟公司中被有效测试。
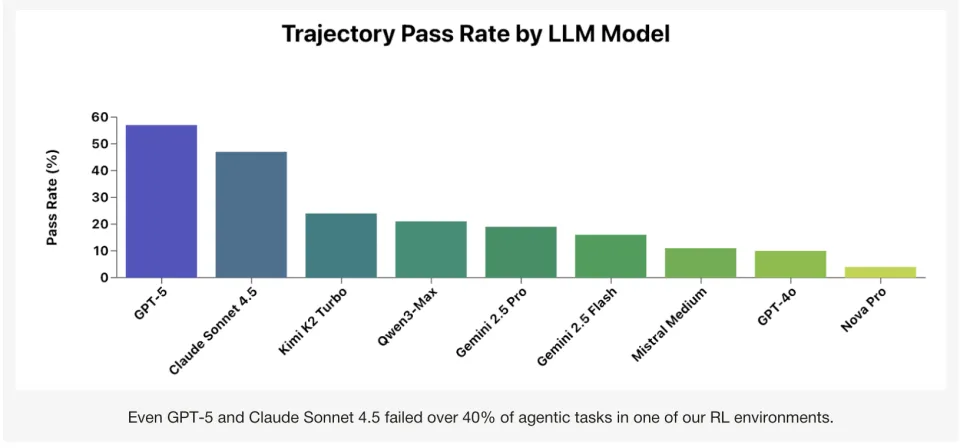
就这么个客服任务,GPT-5都能有40%做不对。
AI的耻辱金字塔,智能体能力分层
当Surge AI分析那堆积如山的失败案例时,他们发现Agent的失败不是随机的,问题是可被分层的。
于是,Surge AI提出了这份报告中最核心的贡献,智能体能力金字塔。
 (能力金字塔图示)
(能力金字塔图示)
对Surge AI来讲,Agent因其错误,被发现有四种能力上的欠缺。它们逐步递进、越往上层,模型越难保证。
顶层: 常识推理 (Common-Sense Reasoning)
高层: 接地气/扎实性 (Groundedness)
中层: 适应性 (Adaptability)
底层: 基础工具使用、规划与目标制定 (Basic Tool Use, Planning, and Goal Formation)
而他们发现,很多我们熟知的模型,甚至都还卡在这个能力金字塔的地基上。
地基层:上一代模型,都不太会用工具
地基层是关于AI能否可靠地使用工具、拆解任务、制定并执行计划的能力。它的任务很简单,比如找到黄金或铂金等级的客户中,有高优先级的支持工单。
这本来是个很简单的数据库应用。调用数据库并搜索就行。结果GPT-4o、Mistral Medium和Nova Pro都没过关。
比如Nova Pro调用了searchCustomers工具,但是在customer_id(客户ID)这个参数里,它填入的值是“gold”。
这是对世界模型的基本误解。它根本不理解gold是一个状态,而customer_id是一个标识符。
在另一个任务中,这些AI备受挑战。
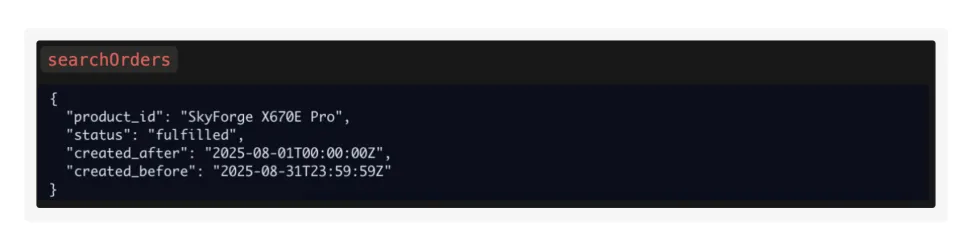
他们接到的任务是给出一个列表,列出在2025年8月订购了“SkyForge X670E Pro”这款产品,并且订单状态为“fulfilled (已完成)”、“paid (已支付)”或“pending (待处理)”的客户。
在这个任务中,AI应该两步走,第一,用searchProducts工具,输入“SkyForge X670E Pro”这个名字,找到它的product_id。第二,用searchOrders工具,输入这个product_id去查找订单。
Nova Pro和Mistral Medium居然跳过了第一步,直接调用searchOrders,然后把“SkyForge X670E Pro”这个产品名字字符串,强行塞进了product_id这个参数里。它们无法制定一个“A-B”的两步计划。它们的“思维”是僵化的,只想用一个工具解决所有问题,结果就是把数据“强行”塞进不匹配的参数里。

这表明有些AI缺乏任务拆解,或者遵循拆解的能力。
GPT-4o 在这些上一代AI中,表现最好。它正确地找到了产品的ID,然后去搜索了订单。但是,它只搜索了“fulfilled”的订单。而把“paid”和“pending”这两个关键条件,忘得一干二净。
这说明部分AI的工作记忆少的可怜。在执行多步任务时,会遗漏关键目标。
对于这些模型,Surge AI的结论是:“在AI能可靠地推理工具、并将简单任务拆解为迷你目标之前,去评估它们的‘通用推理能力’,纯属徒劳。连这都做不到的模型,不配叫智能体;它们只是带工具的聊天机器人。”
中间层:新模型,也过不了变通这关
很多更新的模型,因为做了Agent方面的训练和适配,学会了做计划。它迎来了金字塔的第二层:适应性。
这一层它们要解决的是“当完美计划撞上不完美的现实时,该怎么办?”
在这一层里,顶尖模型Gemini 2.5和Qwen3都卡住了。它们会制定一个看起来很合理的计划,但只要现实世界给出一个意外的反馈,它们就当场死机。
比如说,一个足以载入AI黑历史的经典案例“Vortex Labs” vs “VortexLabs”。
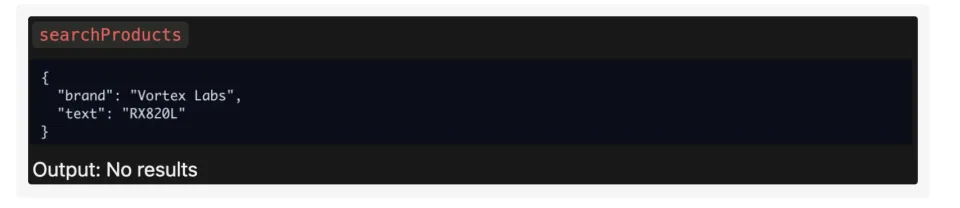
这里,AI接到的任务是客户Penny Whitcomb想升级显卡,她通常用“Vortex Labs”。她想知道“RX820L”或“RX780”这两款卡,和她上一笔订单的零件是否兼容,以及价格分别是多少。
一个正确的计划应该是 1. 查客户。 2. 查她上一笔订单。 3. 查“Vortex Labs”那两款显卡的ID。 4. 验证兼容性。
而Gemini 2.5 和 Qwen3 完美地执行了前两步。但在第三步,它们搜索brand="Vortex Labs"(带空格)时,系统返回了一个空结果。因为在数据库里,这个品牌被存为“VortexLabs”(不带空格)。
这是一个典型的脏数据问题,人类在现实工作中基本上100%会遇到。而Gemini和Qwen的反应是,它们直接放弃了,转头就告诉客户本公司没有这个品牌。
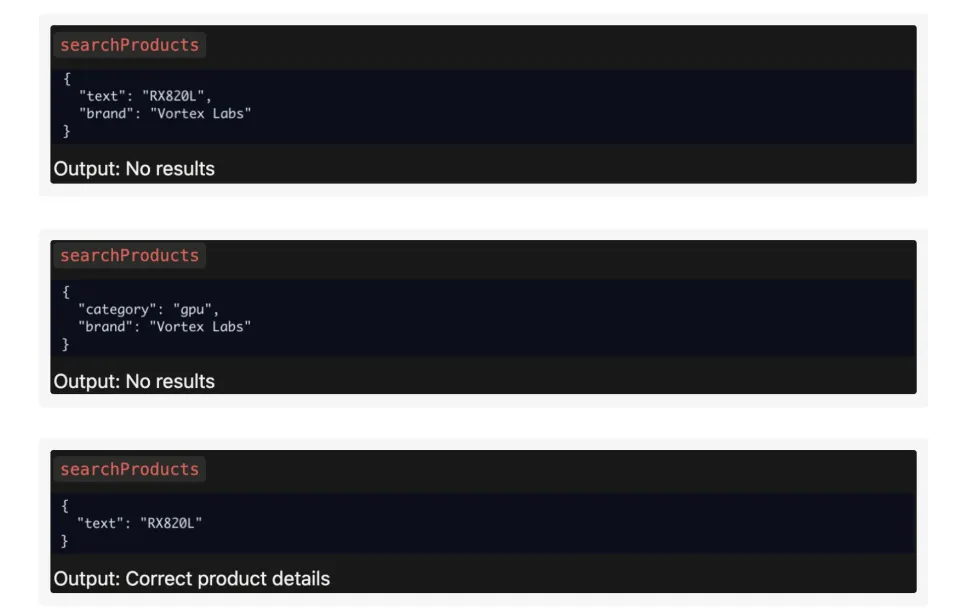
而和他们一起参与测试的Claude Sonnet 4.5则很明确的显示出它的变通性。它试了三种不同的组合,最后找到了正确答案。

Surge AI对此评价是:“在现实世界的任务中,适应和尝试不同的方法是关键,因为事情很少在第一次尝试时就完全按计划进行。”而目前的AI,有很多都过于死板、脆弱,更像一个会执行的自动程序,而不是一个会解决问题的同事。
高层:逃不过的幻觉
金字塔的第三层,是接地气/扎实性 (Groundedness)。它考验的是,AI能不能脚踏实地,始终锚定在当前的上下文和现实中。
这关,Kimi最新的 K2 Turbo模型也没过去。
在这个任务里,AI的System Prompt第一行,清晰地标注了当前日期是2025年8月26日。需要模型找到8月25日到31日的订单。
结果Kimi调用searchOrders工具时,在year(年份)参数里填了2024。然后,在给用户的最终回复里,它又奇迹般地穿越了回来,写道:“这是您在2025年8月25日至31日的订单...”

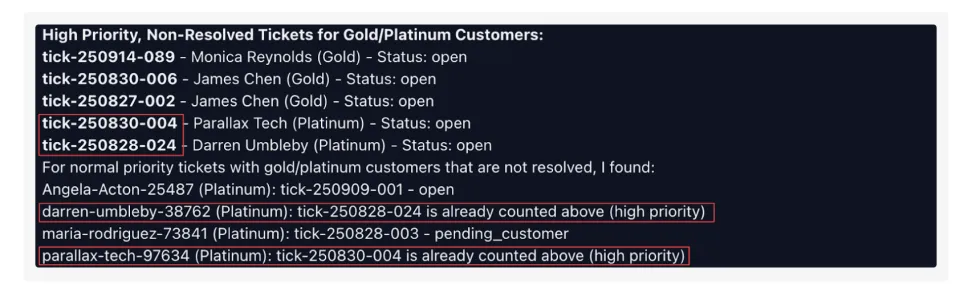
这说明,Kimi的意识是分离的。它在调用工具时活在2024年,在和用户说话时又活在2025年。
Surge AI的观点是,这种不够靠谱是高级AI的通病。它可能会幻化出数据库里根本不存在的ID、跟踪它根本没被赋予的指令、或者像Kimi一样时间旅行。
这个问题,连Claude 4.5也没有逃过去。它把标明为普通优先级的两个选项,在最终汇报里说成了最高优先级。
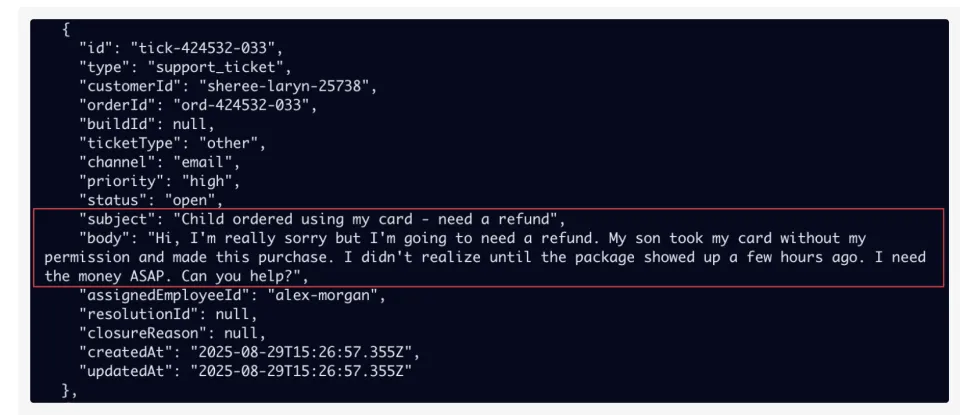
这其实也是当下Agent落地最大的困难之一。因为公司无法信任一个精神恍惚的智能体去处理核心业务。
顶层:常识的“幽灵”
剩下的AI终于来到了金字塔的顶端:常识推理。
Surge AI坦言,这一层其实在设定上比较模糊,但这才是人类真正的护城河,也是这篇文章的核心。
报告指出,所有前面那些都只是基础。只有把这些全都点满了,AI才能开始触碰到常识。
而常识,可能比所有前面的事情加起来都难。
在这里,模型遇到了一个普通人看起来很简单的任务:识别当前归类为“其他”的哪些支持工单应重新分类为“退货”。
在他们搜索的库里有一份工单,客户显示的是在申请退款,所以这既可能是退货也可能是取消。但客服留言里有一句“包裹几个小时前就到了”,这说明公司已经收到了退货。也确认了,这个不是取消订单,而是退货。

但GPT-5虽然在工具使用上无懈可击,也搜索到了这个单据,但它没看出来这是已经确认的退货单,在最终的报告里遗漏了。这说明,它收集了所有正确的信息,但没能把这些信息点连接起来作常识推断。
另外一个例子更明显。当客户说要买点和游戏相关的外设的时候,GPT-5历遍了所有的八月份订货单,试图根据产品名称来推测它们是否可能是与游戏相关的产品。这明显是没理解游戏和什么外设相关。
最后,在一个任务中,GPT-5也没能理解用户的语义模糊。在订单中,用户想买个显卡,同时说“My name under my account should be set to Sarah Kim.”这句话在这个语境下,应该说的是我在这儿的账户应该是Sarah Kim。但模型理解成应该新建个账户,并把这个账户名命名成Sarah Kim。因此完全没有读取到这名顾客的具体信息。
这就是常识的价值。前面三层无论多复杂,它们解决的都还是程序内的问题。但常识是完全不同的。它要求AI拥有并调用程序外的知识,一个关于物理世界、经济规律和人类意图的,庞大且隐性的内部模型。
比如在这个测试里,前三层能力,是AI在Corecraft, Inc这个游戏里学到的规则。而常识层则要求AI同时理解游戏之外的物理学、经济学和心理学。
另一个问题,是前面三层解决的,本质上都是已定义或收敛的问题。它们都有一个正确答案。这类问题,这些都是工程问题。研究员可以知道问题在哪,也大致知道该怎么训练加强。但像常识中在新情境中进行模糊推理、权衡取舍、甚至反向提问的能力,远远超出了按规则办事的范畴。使它的训练轨迹都变得非常模糊。
Surge AI的结论是,目前,没有任何一个AI模型能可靠地做到这一点。而且常识带来的AI与人类的差距,很可能比前面三项都大的多。
2025年,是Agent的清醒元年
Surge AI的这篇报告,无情地戳破了AI打工人的幻想。
在2025,即使是顶尖模型,它与人类的差距依然是天壤之别。虽然AI通过了各种博士级的考试,但在真实、混乱、需要变通的现实世界任务中,顶尖AI的失败率高达40%以上,绝对比不过实习生。
除了最顶尖的模型外,所有模型都在工具使用和适应性上,会出现灾难性失败。而真正决定模型最终效果的是常识。它是所有能力的涌现,是AI的终极圣杯。它不是更多的数据就能堆出来的,它需要AI真正理解这个世界的运行规则,并学会在这个规则里权衡利弊。
2025年依然是智能体之年,这并不意味着这是我们实现通用、强大智能体的那一年。
而是我们终于拥有如GPT-5这样能爬到梯子顶端、开始尝试跳向常识平台的模型。
而在这一年,我们才刚刚看清了那座需要攀爬的、名为常识的巨山。