拆解CANN:当华为决定打开算力的「黑盒」

大模型的竞争如火如荼,也有一群人正在研究如何降低门槛,让 AI 工具变得亲民。
最近,在 AI 基础算力上重磅频出的华为,又亮出了一张王牌:昇腾的底层基础软件,CANN 全面开源开放。
昇腾宣布将通过一系列新举措,持续支持开发者在 AI 模型、算子、内核、底层资源等多个层级进行自主优化与自定义开发。通过开放共建,一个新兴的 AI 算力生态正在快速崛起,改变计算架构领域本已固化的格局。
CANN 全称为「神经网络异构计算架构」(Compute Architecture for Neural Networks),其作为连接上层 AI 训练框架(如 PyTorch、TensorFlow、MindSpore 等)和底层 AI 芯片的桥梁,让开发者不用关心芯片细节就能调用底层算力。
最近一段时间,业内对于国产 AI 算力的需求大幅增长,让人们更加重视起硬件的计算架构。CANN 的开源开放引发了业界的广泛关注,当 CANN 这个在整个 AI 技术栈中「承上启下」的关键角色被开源了之后,开发者们获得了定义算力的权力。
以前在 AI 芯片上的算子开发门槛高到不敢用,现在昇腾 CANN 把这层窗户纸捅破了。
这一次,我们不谈宏大的生态格局,只谈对于坐在屏幕前的开发者来说,CANN 的开源开放到底带来了什么?
拒绝「黑盒」
三种路径实现「AI 算子开发自由」
在 AI 开发的深水区,算子开发效率与性能的平衡始终是个难题。但「AI 算子开发自由」首先建立在广泛的生态兼容之上。
CANN 目前已经支持与 PyTorch、TensorFlow、MindSpore、PaddlePaddle 等主流 AI 框架无缝对接,并开放了 GE 图开发接口,允许开发者自定义图结构,满足了多样化的开发需求。

大模型方面,CANN 覆盖了国内外目前的主流,支持包括 Llama、Mistral、Phi 等海外模型,以及 Qwen、DeepSeek、GLM 等国产大模型家族,共计超过 50 种。昇腾已经参与了超过 10 个大模型开源社区的上下游生态构建。
在此基础上,针对更深层的算子开发挑战,开源开放后的 CANN 为不同技术背景的开发者提供了三条路径。
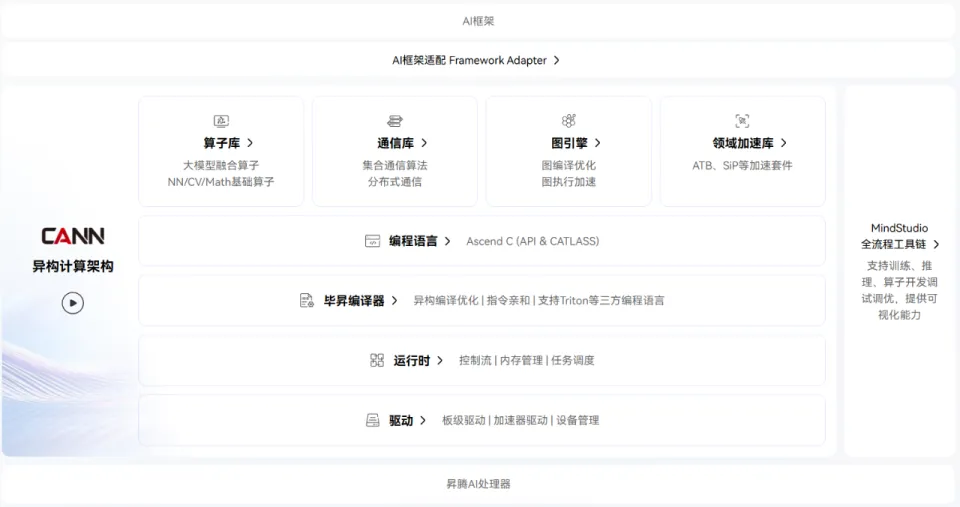
路径一:习惯 Python?Triton 生态无缝接入
对于习惯了 GPU 编程范式的开发者,最大的顾虑往往是迁移成本。CANN 对此给出的答案是:不用改变习惯。
CANN 实现了与业界主流开发范式 Triton 的深度对接。通过 Linalg IR 与 AscendNPU IR(中间表示)的转换,开发者可以直接使用熟悉的 Python 语法编写高性能算子,原有的 Triton 代码能够以极低的成本迁移到昇腾 NPU 上。
此外,CANN 还引入了 TileLang 这一新兴编程选择。它提供了比 Triton 更细粒度的性能控制能力,允许开发者显式管理数据分块和内存层级映射。通过 TileLang-Ascend 的深度适配,开发者可以利用类 Python 语法,精准操控 NPU 的 Cube 核与 Vector 核,有效解决现代 AI 芯片面临的「内存墙」挑战。
路径二:追求极致?Ascend C 让性能「狂飙」
对于追求 SOTA 性能的系统级程序员,Ascend C 是昇腾原生提供的终极武器。
这是一种采用 C/C++ 语法风格的编程语言,它开放了算子底层资源管理接口。这意味着开发者不再受限于封装好的 API,而是可以直接调用 NPU 的原子级能力,精确控制每一个时钟周期的行为和片上缓存管理。无论是 FlashAttention 还是复杂的 MoE 融合算子,Ascend C 都能让开发者榨干硬件的每一滴性能。
路径三:想要省力?搭积木式的模板库
并非所有场景都需要从零手写算子。针对深度学习中无处不在的矩阵运算(GEMM),CANN 推出了 CATLASS 算子模板库。

这是一个基于 Ascend C 构建的高性能算子模版库,它将复杂的矩阵乘法及其融合算子抽象为可配置的模板。开发者无需重新编写复杂的切分(Tiling)和流水线(Pipeline)逻辑,只需简单的参数配置,即可快速生成适配不同形状和精度的矩阵乘算子。
在当前主流的 MoE(混合专家)模型支持上,CANN 还推出了创新的 MLAPO 融合算子。这种设计将原本需要多个算子完成的 MoE 计算,融合为单个高效算子。测试数据显示,MLAPO 融合算子能够显著降低计算开销,相比传统实现方式,在相同硬件上获得明显的性能提升。

在大参数 DeepSeekV3 模型的量化场景下,MLAPO 算子的实现能将计算耗时从 109us 缩减为 45us,带来整网性能提升 20%。
这不是画饼,而是已经有开源代码、有仓库的实质性进展。
为了方便开发者快速上手,CANN 已在 AtomGit 上开放了包括 CATLASS(算子模板库)、ops-math(基础数学)、ops-nn(神经网络)、ops-transformer(transformer 类大模型)、ops-cv(图像处理、目标检测)、HCCL(通信库)在内的多个核心仓库,并发布了集成主流大模型环境的官方容器镜像,开发者可以通过容器指令直接获取开箱即用的开发环境。(https://gitcode.com/cann)
目前,CANN 已预置了超过 1400 个基础算子、100 多个融合算子以及 15 个通信算法,为大模型开发提供了「开箱即用」的能力。这些算子经过深度优化和实际生产过程的验证,能够充分发挥昇腾硬件的性能潜力,是吸引开发者和企业客户从「试一试」转向「深度用」的硬通货。
这种对底层细节的「可控性」,使 CANN 能够成为追求 SOTA 性能的系统程序员的有力武器。
架构变革:分层解耦
为什么现在的 CANN 能做到如此灵活?核心在于架构上的分层解耦。
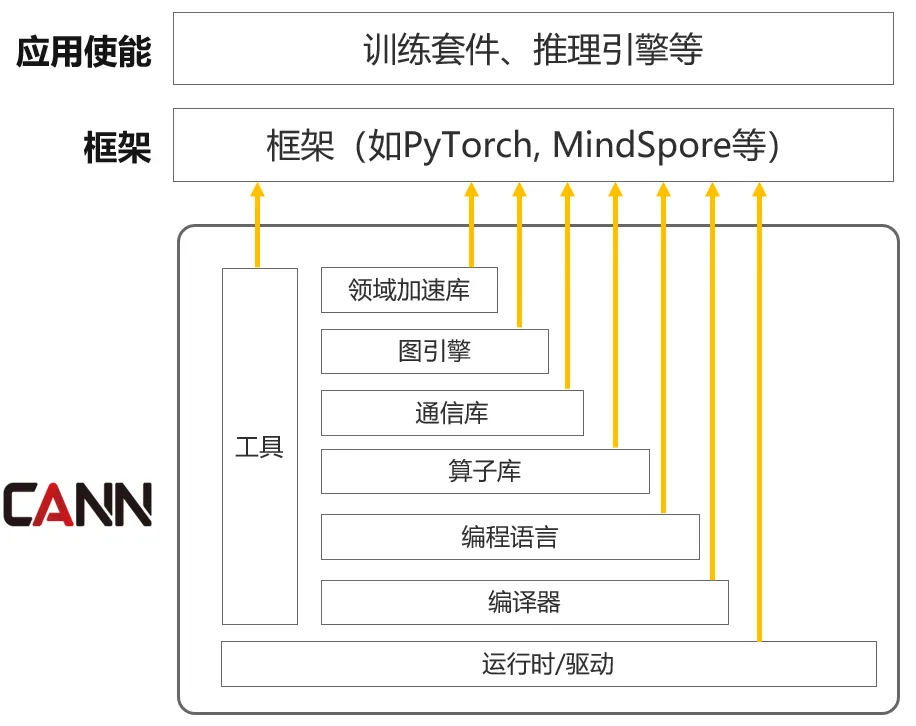
CANN 的多层架构示意图,其中不同的层级有不同的开源策略。
何为分层解耦?其实并不难理解。在过去的 AI 软件栈中,工具链、运行时、驱动、编程体系、加速库等往往被打造成一个整体。这种模式虽也有优势,但对于追求极致性能的头部模型厂商和底层系统工程师来说,却显得笨重。
而 CANN 却做到了在宏观架构上的功能解耦与组件独立演进。
具体来说,CANN 不再是一个巨大的单体软件,而是被拆解为多个功能正交的组件。分层解耦的思路贯穿了全栈:从底层的硬件驱动到中间的运行时,再到上层的编译器和加速库,每一层都实现了物理上的松耦合。
这意味着开发者无需像过去那样「牵一发而动全身」,而是可以根据业务需求,按需引入或升级特定的组件功能,大幅降低了系统集成和定制开发的门槛。
这种解耦可为 CANN 各个层级带来重要的变化:
加速库的「组件化」
CANN 改变了过去「全量算子一个包」的发布方式。算子库被精细拆分为 ops-math、ops-nn、ops-cv 和 ops-transformer 等独立组件。
通信库和图引擎(GE)也作为独立组件逐步开放。其中 HCCL 开放了通信算子和框架层,支持开发者自定义通信算法以适应大规模集群;GE 则开放了图编译和执行接口,支持自定义图融合策略。
运行时的「极简化」
Runtime 层剥离了冗余模块,实现了核心功能的最小化。更为关键的是,Runtime 开放了 aclGraph 接口,支持图模式下沉。
这一机制允许开发者将由多个算子组成的计算图一次性下沉到 Device 侧,极大地减少了 Host 与 Device 之间的交互开销。
在架构分层解耦之后,CANN 实现了组件功能的最小化,共有 20 余个安装包,支持各功能的独立演进和编译升级。
这样一来,开发者可以在模型、算子、内核、底层资源等多个层级分别进行优化与开发。可以说开源后的 CANN,在追求极致性能的同时,兼顾了开发的易用性。
全面开源开放
正在陆续进行中
对于开源世界来说,真正的技术价值会在自由流动中无限放大。CANN 的开源正是遵循同一逻辑:它不仅仅是为了「替代」,更是发出了一份共同构建「算力多元世界」的邀请函。开发者的每一次使用,问题的反馈和代码的提交,都会为这个新的生态做出贡献。
当 CANN 开源社区的代码仓库逐渐被开发者 fork 和 star,大学实验室的研究者们开始用 Ascend C 完成 AI 项目,当硅基流动、无问芯穹等创业公司基于 CANN 优化自己的模型训练流程,一个不同于 CUDA 路径的 AI 算力生态正在快速成长。
基于昇腾 CANN,无论你是想验证一个想法,还是迁移一个模型,现在都可以快速开始。
目前,CANN 的全面开源开放正在加速推进,其在 AtomGit 的代码库也非常活跃,几乎每天都有新的动态。

截至目前,CANN 项目下已有 27 个子项目,总 star 数已经超过 3700,总下载量更是已经突破 35 万。
更值得期待的是,开源的版图还在持续扩大。比如用于负责 AI 计算图的解析、优化和执行的 GE (Graph Engine,也是 CANN 的核心组件之一)以及一种旨在简化高性能算子的开发流程的新型编程范式 PyPTO(Python Parallel Tensor Operation)框架。

想体验最新的 CANN 开源开放能力?
主页地址:https://www.hiascend.com/cann
开源项目:https://gitcode.com/cann