北航提出代码大模型的 Scaling Laws:编程语言差异与多语言最优配比策略

北航、人大和九坤投资共同撰写的论文 《Scaling Laws for Code: Every Programming Language Matters》 整理而成。
在代码大模型(Code LLMs)的预训练中,行业内长期存在一种惯性思维,即把所有编程语言的代码都视为同质化的文本数据,主要关注数据总量的堆叠。然而,现代软件开发本质上是多语言混合的,不同语言的语法特性、语料规模和应用场景差异巨大。如果忽略这些差异,笼统地应用通用的 Scaling Laws,往往会导致性能预测偏差和算力浪费。
为了打破这一黑盒,研究团队耗费了相当于 33.6 万个 H800 GPU 时,进行了超过 1000 次实验。研究覆盖了从 0.2B 到 14B 的模型参数规模,以及高达 1T 的训练数据量,系统性地对 Python、Java、JavaScript、TypeScript、C#、Go、Rust 这七种主流语言进行了解构。这项工作的核心贡献在于建立了区分语言特性的 Scaling Laws,并据此提出了一套数学可解的最优数据配比方案。

论文:《Scaling Laws for Code: Every Programming Language Matters》
论文链接:https://arxiv.org/abs/2512.13472
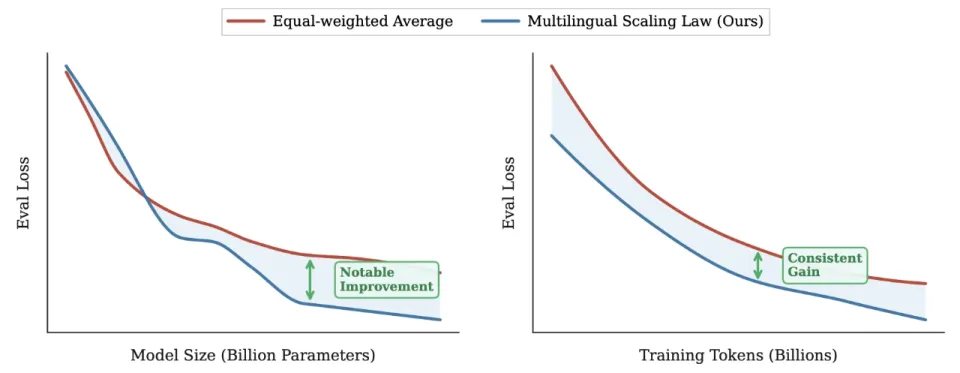
图 1:论文提出的多语言 Scaling Law 与传统均匀分布基线的 Loss 对比。蓝色曲线显示,基于本文方法优化的模型在相同算力下能持续获得更低的 Loss)
语言特异性:Python 潜力巨大,Rust 快速收敛
研究首先挑战了 “所有语言生而平等” 的假设。通过为每种语言单独拟合 Chinchilla 风格的 Scaling Law 公式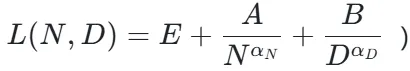 ,作者发现不同语言的训练动力学存在显著差异。
,作者发现不同语言的训练动力学存在显著差异。
具体而言,以 Python 为代表的动态解释型语言表现出更高的 Scaling 指数( ),这意味着随着模型参数量的增加和训练数据的扩充,Python 的性能提升幅度最大,尚未触及天花板,属于 “吃算力、吃数据” 的类型。相反,以 Rust 为代表的强类型编译型语言,由于其严格的语法约束和内存安全规则,模型能更快地掌握其模式,在较小的规模下即可达到较低的 Loss,但也意味着它更容易进入性能饱和期,边际收益递减较快。
),这意味着随着模型参数量的增加和训练数据的扩充,Python 的性能提升幅度最大,尚未触及天花板,属于 “吃算力、吃数据” 的类型。相反,以 Rust 为代表的强类型编译型语言,由于其严格的语法约束和内存安全规则,模型能更快地掌握其模式,在较小的规模下即可达到较低的 Loss,但也意味着它更容易进入性能饱和期,边际收益递减较快。
此外,论文还引入了 “不可约 Loss”(  )来量化语言的内在复杂度。结果显示各语言的内在可预测性排序为:C# < Java ≈ Rust < Go < TypeScript < JavaScript < Python。C# 因其高度标准化的语法和生态,是 “最容易预测” 的语言;而 Python 由于其极高的灵活性和多样的表达方式,内在熵值最高,对模型来说最难完全 “学透”。
)来量化语言的内在复杂度。结果显示各语言的内在可预测性排序为:C# < Java ≈ Rust < Go < TypeScript < JavaScript < Python。C# 因其高度标准化的语法和生态,是 “最容易预测” 的语言;而 Python 由于其极高的灵活性和多样的表达方式,内在熵值最高,对模型来说最难完全 “学透”。

图 2:七种编程语言各自独立的 Scaling Law 曲线。可以看到 Python(左上)的曲线斜率更陡峭,而 Rust(右下)则更早趋于平缓)
协同效应矩阵:语言间的 “近亲繁殖” 与 “非对称互助”
在实际预训练中,我们很少只训练单语言模型。那么,混合多种语言训练是否存在 “协同效应”(Synergy)?研究团队构建了一个详尽的协同增益矩阵,量化了引入辅助语言对目标语言性能的影响。
实验发现,绝大多数语言都能从多语言混合训练中获益,且收益大小与语法相似度高度相关。例如,Java 与 C#、JavaScript 与 TypeScript 这类语法结构高度相似的语言对,在混合训练时表现出极强的正向迁移效果。
更有趣的是,这种迁移往往是非对称的。Java 是多语言训练的最大受益者,几乎与任何语言混合都能大幅降低其 Loss,这可能是因为 Java 作为成熟的面向对象语言,能从其他语言的范式中汲取通用逻辑。而 Python 虽然是代码领域的通用 “供体”(帮助其他语言提升),但其自身从其他语言获得的收益却相对有限,甚至在某些混合比例下会出现轻微的负迁移。这一发现提示我们,在构建语料库时需要精细设计混合策略,而非盲目地 “大杂烩”。

表 1:协同增益矩阵。红色越深代表辅助语言(列)对目标语言(行)的提升越大。Java 所在的行显示出它能从所有辅助语言中获得显著收益)
跨语言对齐策略:并行配对激发 Zero-Shot 能力
除了单语言生成,跨语言翻译(如 Java 转 Python)也是代码模型的重要能力。论文对比了两种数据组织策略:传统的 “随机打乱”(Random Shuffling)和 “并行配对”(Parallel Pairing)—— 即将一段代码与其翻译版本拼接在同一个 Context 中输入模型。
实验结果表明,并行配对策略在所有模型规模上均显著优于基线。这种策略实际上利用了模型的长上下文窗口,构建了隐式的文档级对齐信号。更关键的是,这种策略激发了模型在 Zero-Shot(零样本)方向上的泛化能力。例如,模型仅训练了 Python↔Java 和 Python↔Go 的配对数据,但在测试从未见过的 Java↔Go 翻译任务时,基于并行配对训练的模型表现出了惊人的组合泛化能力。这证明了通过构建以 Python 为枢纽的平行语料,可以有效拉齐不同编程语言的向量空间。
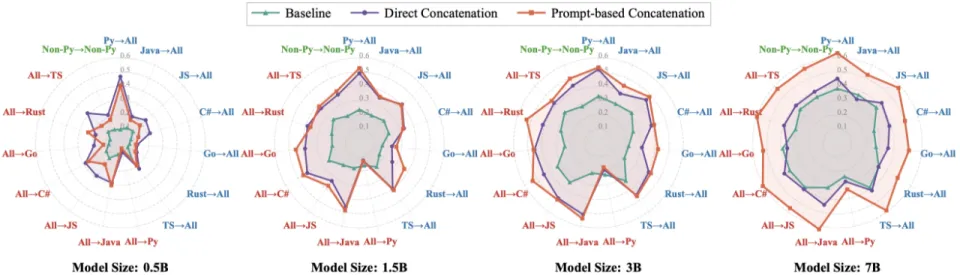
图 4:三种策略在跨语言翻译任务上的表现对比。绿色线条代表的并行配对策略(Prompt-based Concatenation)在各方向上均取得最低 Loss)
最优 Token 分配指南:基于边际效用的经济学
基于上述发现,论文提出了 “科学配比的多语言 Scaling Law”(Proportion-dependent Multilingual Scaling Law)。这不仅是一个理论公式,更是一套指导算力投资的行动指南。
在总算力固定的约束下,传统的均匀分配并非最优解。最优策略应遵循边际效用最大化原则:
重仓高潜力语言:大幅增加 Python 的 Token 占比,因为它的 Scaling 指数高,投入更多数据能带来持续的性能爬坡。
平衡高协同组合:利用 JavaScript 和 TypeScript 的互补性,保持两者适度的比例以最大化协同增益。
削减早熟语言投入:适当减少 Rust 和 Go 的数据占比。因为它们收敛快,过多的数据投入只会带来边际收益的快速衰减,不如将这部分算力转移给更难学的语言。
实验验证显示,采用这种 “引导式分配” 策略训练出的 1.5B 模型,在多语言代码生成(MultiPL-E)和翻译任务上,均稳定优于均匀分配的基线模型,且没有任何一种语言因数据减少而出现显著的性能退化。
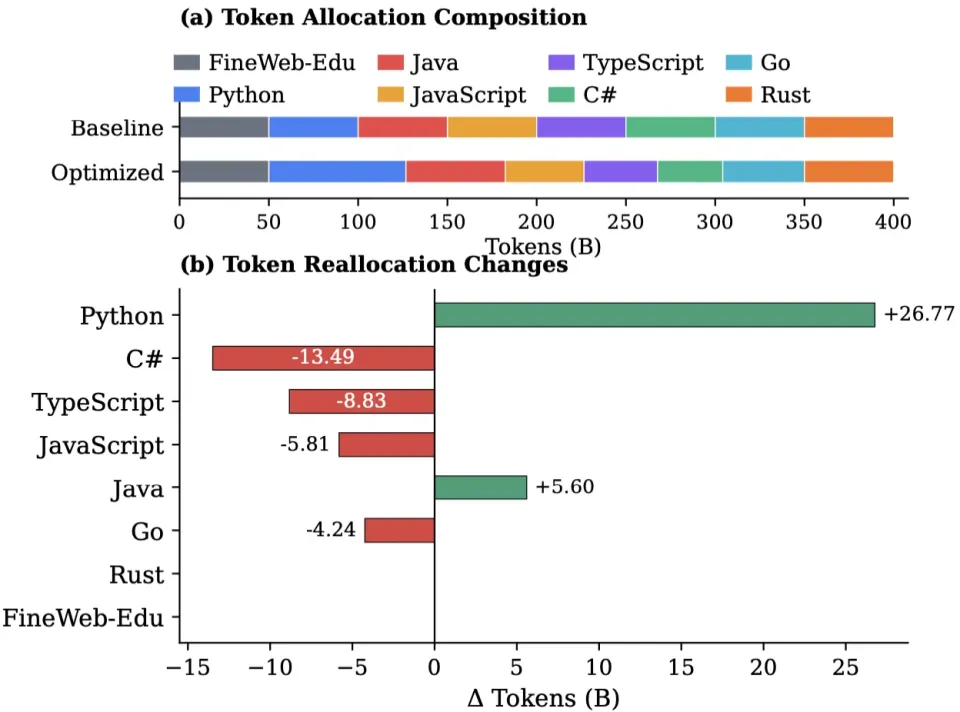
图 5:基线策略 vs 优化后的 Token 分配方案。基于 Scaling Law 的建议大幅增加了 Python(蓝色)的占比,同时削减了 Rust(橙色)和 Go(青色)的占比)
总结与启示
这项工作是代码大模型领域一次重要的 “去魅” 过程。它用详实的数据证明,编程语言在模型训练的视角下绝非同质。
对于致力于训练 Code LLM 的团队而言,这意味着数据工程的重点应从单纯的 “清洗与去重” 转向更宏观的 “成分配比”。理解不同语言的 Scaling 特性(是像 Python 一样潜力巨大,还是像 Rust 一样迅速饱和)以及它们之间的协同关系,能够帮助我们在有限的算力预算下,训练出综合代码能力更强的基座模型。这不仅是算法的优化,更是资源配置效率的提升。