Meta重磅:让智能体摆脱人类知识的瓶颈,通往自主AI的SSR级研究
众所周知,「超级智能」是 Meta 持续不变的宏大愿景。
为了尽早达到构建超级智能的目标,扎克伯格在这一年里可谓是大刀阔斧,搞得 Meta 研究部门鸡飞狗跳。
前 Meta FAIR 领军人物 Yann LeCun 锐评:「通往超级智能… 在我看来完全是胡扯,这条路根本行不通。」
不过,Meta 决定构建「超级智能」,一个真正能够超越人类专家水平的自主 AI 智能体,是人工智能研究中最具雄心的前沿目标。
AI 智能体执行任务最具代表性的落地领域就是编程了。目前,基于 LLM 的编程智能体已经展现出令人瞩目的自动化能力,但它们在本质上仍然受到一个根本性限制:高度依赖人类的训练数据:
学习自 GitHub 等真实编程数据;
需要手工撰写的 Bug 报告、Issue 描述;
用已有的测试用例来反馈。
这种依赖关系形成了一道关键瓶颈,使得这些系统只能不断打磨和复现既有人类知识,而难以真正走向自主发现新问题、探索新解法的道路。
为此,来自 Meta FAIR 和 Meta TBD 实验室的一项全新研究工作,打破了这一关键瓶颈,提出了 SSR(自对弈 SWE-RL),旨在通过使软件代理能够自主生成学习经验,从而摆脱人类数据的限制。
SSR 借鉴了 AlphaGo 等自对弈系统的成功经验,提出了一条通往「超智能软件智能体」的途径,这些智能体可以在无需现有问题描述、测试或人工监督的情况下,通过与真实代码库的交互来学习和改进。

论文标题:Toward Training Superintelligent Software Agents through Self-Play SWE-RL
论文链接:https://arxiv.org/pdf/2512.18552
在本文中,研究团队提出了 Self-play SWE-RL(SSR),作为迈向超级智能软件智能体训练范式的第一步。该方法几乎不依赖人工数据,仅假设能够访问带有源代码与依赖环境的沙盒化代码仓库,而不需要任何人工标注的 issue 或测试用例。
基于这些真实世界代码库,通过一种自博弈(self-play)的强化学习框架训练单一 LLM 智能体,使其能够不断自主注入并修复复杂度逐步提升的软件缺陷。在该过程中,每个缺陷均通过测试补丁(test patch)进行形式化描述,而非使用自然语言的 issue 描述。
SSR 的博弈方法
SSR 的核心思想,是让大模型智能体通过一个持续循环的过程来自我进化。
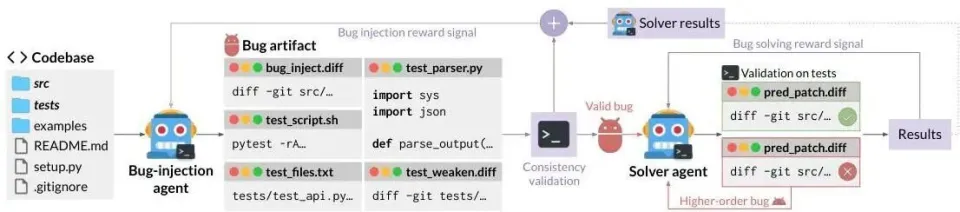
自对弈 SWE-RL(SSR)框架概览。
如图所示,同一个 LLM 策略被拆分成两个角色:Bug 注入智能体(bug-injection agent) 和 Bug 修复智能体(bug-solving agent)。这两个角色共享同一个容器化运行环境和同一套工具,但它们接收到的任务说明和目标约束不同。
具体来说:
Bug 注入智能体首先获得一个隔离的原始代码库环境,它的任务是通过生成一个包含必要文件的 “工件(artifact)” 来人为引入一个 Bug。随后系统会通过实际执行来验证该工件的一致性 —— 确保该 Bug 真实存在、可被复现。通过一致性验证的 Bug 工件会被视为有效样本,并提交给 Bug 修复智能体。

SSR 采用的两种主要 bug 注入策略:面向移除的方法(左)移除大量代码块,而历史感知方法(右)有选择地恢复 git 日志中的历史更改以引入真实的 bug 模式。
Bug 修复智能体则针对该 Bug 生成最终补丁,补丁是否成功由该 Bug 所定义的测试结果来验证。若修复失败,该失败过程会被视为一种 “高阶 Bug(higher-order bug)”,促使智能体在新的上下文中再次尝试。

智能体 bug 修复过程
最终,Bug 注入阶段的奖励信号 由一致性验证结果与修复结果共同构成,用于激励更高质量的 Bug 提案;Bug 修复阶段的奖励信号 则主要依赖测试结果。底层的同一个 LLM 策略模型会在这两种奖励信号的共同作用下进行联合更新。
评估与测试
研究团队在 SWE-bench Verified 与 SWE-Bench Pro 两个基准测试上,对基础模型(Base Model)、传统强化学习方法(Baseline RL),以及 SSR 方法进行了系统对比。
Baseline RL 与 CWM 中的标准智能体强化学习类似,可以访问自然语言问题描述、通过测试与失败测试信息,以及评测脚本,强化学习过程本质上只是检查生成的解决方案是否通过这些给定测试。
相比之下,SSR 仅接触最原始的环境镜像,模型必须在完全没有任何问题描述和测试用例的情况下,通过自我对弈来自主发现问题、构造解决方案并进行验证。
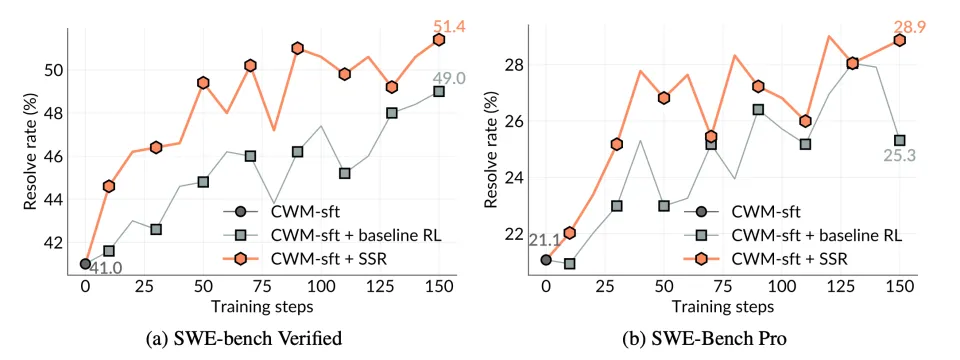
如图所示,实验结果呈现出两个关键现象:
首先,即便在完全没有任务相关训练数据的情况下,SSR 在整个训练过程中仍然表现出稳定而持续的自我提升能力。这表明,大型语言模型可以仅凭与原始代码库的交互,就逐步增强自身的软件工程能力(例如问题定位与修复能力)。
其次,在整个训练轨迹中,SSR 在两个基准测试上始终优于传统 Baseline RL。这意味着,由模型自主生成的学习任务,比人工构造的数据提供了更丰富、更有效的学习信号。
在 SWE-bench Verified 与 SWE-Bench Pro 基准测试上,SSR 展现出显著的自我提升能力(分别提升 +10.4 与 +7.8 个百分点),并在整个训练过程中持续超越依赖人工数据的基线方法 —— 尽管模型的评测对象仍然是自然语言描述的问题,而这些描述在自博弈训练阶段完全未出现过。
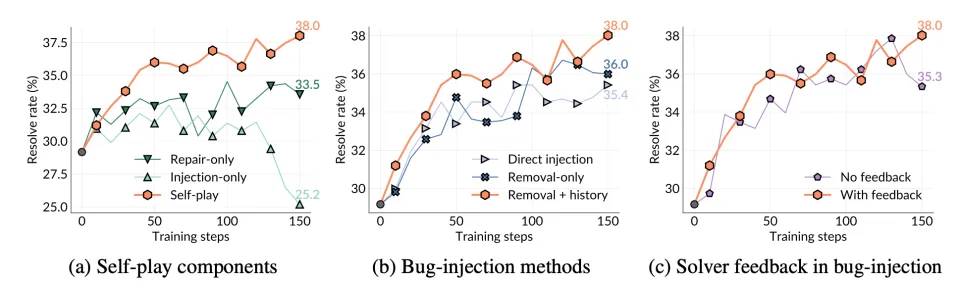
Self-play SWE-RL 的消融实验结果。
消融实验结果表明,仅注入训练会降低整体性能,因为模型无法从任何 Bug 修复尝试中学习;仅修复训练同样表现较差,因为它缺乏由自我对弈持续生成的动态任务分布。
相比之下,自我对弈要求智能体不仅要修复 Bug,还要不断提出具有挑战性的 Bug,而这个过程本身就蕴含着丰富的学习内容:
识别哪些测试可以通过;
以有意义的方式破坏系统功能;
甚至刻意削弱测试以隐藏 Bug。
这些行为不断扩展训练信号,并让模型持续暴露在新的失败模式之下。结果表明:一个持续进化、在线生成 Bug 并解决 Bug 的训练过程,是模型实现长期自我提升的关键。
结语
SSR 代表着在开发能够无需直接人工监督进行学习和改进的真正自主人工智能系统方面迈出了重要一步。
通过证明大型语言模型可以从真实世界的软件仓库中生成有意义的学习经验,这项工作为将人工智能训练扩展到人类策划数据集之外开辟了新的可能性。
该方法解决了当前人工智能开发中根本性的可扩展性限制。人工标注的训练数据昂贵、有限且可能存在偏差,为开发更强大的系统制造了瓶颈。SSR 的自生成课程有可能使训练在比目前通过传统数据收集方法更可行的问题上,数量级地更多样化和更具挑战性。
随着 AI 系统能力日益增强,从真实世界环境中自主学习的能力对于开发能够在复杂问题解决场景中真正提供帮助甚至主导的智能体变得至关重要。SSR 的演示表明这种自主学习在软件领域是可行的,这为在其他技术领域实现类似能力指明了有前景的方向,尤其是在那些正式验证和迭代改进可行的领域。
尽管仍属早期成果,这些结果表明:未来的软件智能体或将能够在真实代码仓库中自主获取海量学习经验,最终发展为在系统理解、复杂问题求解乃至从零构建全新软件方面超越人类能力的超级智能系统。
更多信息,请参阅原论文。