让模型自己找关键帧、视觉线索,小红书Video-Thinker破解视频推理困局
随着多模态大语言模型(MLLM)的飞速发展,“Thinking with Images” 范式已在图像理解和推理任务上取得了革命性突破 —— 模型不再是被动接收视觉信息,而是学会了主动定位与思考。
然而,当面对包含复杂时序依赖与动态叙事的视频推理任务时,这一能力尚未得到有效延伸。现有的视频推理方法往往受限于对外部工具的依赖或预设的提示词策略,难以让模型内生出对时间序列的自主导航与深度理解能力,导致模型在处理长视频或复杂逻辑时显得捉襟见肘。
为攻克这一难题,来自小红书的研究团队提出了 Video-Thinker:一种全新的 “Thinking with Videos” 范式,旨在通过强化学习激发 MLLM 在视频推理中的内生智能。
与传统方法不同,Video-Thinker 不依赖构建和调用外部工具,而是将 “时序定位(Grounding)” 与 “视觉描述(Captioning)” 这两种核心能力内化在模型的思维链(CoT)中,使其能在推理过程中自主寻找关键帧并提取视觉线索。
团队精心构建了包含 10K 高质量样本的 Video-Thinker-10K 数据集,并采用 “监督微调 + 强化学习” 的两阶段训练策略。这一方法成功让模型在无外部辅助的情况下,实现了对视频内容的自主探索与自我修正。
实验结果显示,Video-Thinker-7B 凭借极高的数据效率,在 Video-Holmes 等多个高难度视频推理榜单上显著超越了现有基线,确立了 7B 量级 MLLM 的 SOTA(State-of-the-Art)性能,为视频大模型的动态推理开辟了新路径。

论文地址:https://www.arxiv.org/abs/2510.23473
模型地址:https://huggingface.co/ShijianW01/Video-Thinker-7B
代码地址:https://github.com/DeepExperience/Video-Thinker
一、背景:视频推理的 “工具依赖困局” 与破局需求
在多模态大语言模型(MLLM)进化的浪潮中,“Thinking with Images” 范式已经让模型在静态图像的理解与推理上取得了令人瞩目的突破。当模型学会了在像素间主动定位与思考,静态画面不再是信息的黑盒。
然而,当我们试图将这种范式延伸至视频领域时,情况却变得复杂得多。视频不仅仅是图像的简单堆叠,更包含了复杂的时序依赖、动态的叙事逻辑以及稍纵即逝的视觉细节。面对这种高维度的信息流,现有的视频推理方法正面临着难以突破的瓶颈。
当前主流的视频大模型在处理复杂推理任务时,往往陷入了一种对 “外部辅助” 的过度依赖。为了弥补模型对长视频处理能力的不足,研究者们通常采用挂载外部视觉工具(如检测器、追踪器)或设计繁复的预设提示词策略来辅助模型。这种做法虽然在一定程度上缓解了信息获取的难题,却在本质上造成了推理过程的 “割裂”:模型并非真正 “看见” 并 “理解” 了视频的时间脉络,而是被动地接收外部工具提取的碎片化特征,或是机械地遵循预设步骤进行填空。
这种缺乏内生主动性的架构,导致模型在面对长视频或需要深度逻辑推演的任务时显得捉襟见肘。由于缺乏对时间序列的自主导航能力,模型无法像人类一样根据当前的思考线索去主动 “快进”、“倒带” 或聚焦于某个关键帧。它无法自主决定何时通过 “Grounding(时序定位)” 来锁定证据,也无法灵活地利用 “Captioning(视觉描述)” 来提炼线索。这种感知与推理的脱节,使得模型难以在动态变化的视频内容中构建起连贯的思维链,最终限制了视频大模型向更高阶智能的跃升。
如何让模型摆脱对外挂拐杖的依赖,内生出在时间流中自由探索与自我修正的能力,成为了视频推理领域亟待攻克的难题。
二、方法:内生能力导向的 “数据 - 训练” 全链路设计
Video-Thinker 的核心愿景在于实现 “能力内化”:打破传统视频大模型对外部视觉工具的依赖,将 “时序定位(Grounding)” 与 “视觉描述(Captioning)” 这两大核心能力直接植入模型的思维链(CoT)中。为达成这一目标,团队设计了一套精密的 “数据 - 训练” 协同机制:首先构建 Video-Thinker-10K 高质量结构化数据,随后通过 “监督微调(SFT)+ 组相对策略优化(GRPO)” 的两阶段训练范式,成功让模型学会了在动态视频流中自主导航、主动思考。

数据炼金:Hindsight-Curation 驱动的思维链构建

要让模型真正掌握视频场景下的复杂推理能力,构建高质量的训练数据是必经之路。然而,现有的开源视频数据集普遍存在 “二元割裂” 的结构性缺陷:一类是以 ActivityNet、YouCook2 为代表的描述型数据,虽然拥有精确的时间段标注和画面描述,但缺乏需要深度思考的逻辑问答;另一类是以 STAR、LVBench 为代表的问答型数据,虽然问题极具挑战性,却往往缺失了支撑答案的关键帧定位与视觉细节。为了弥补这一鸿沟,团队整合了六大主流数据集,构建了 Video-Thinker-10K。该数据集并未止步于简单的拼接,而是引入了一套 “后见之明(Hindsight-Curation)” 的自动化流水线,通过 “补全 - 合成 - 验证” 的严密闭环,生产出兼具精准时序定位(Grounding)与详尽视觉描述(Captioning)的结构化推理数据,确保模型在学习过程中能够建立起从视觉证据到逻辑结论的完整映射。
Step 1: 双向信息补全
面对不同源数据特性的差异,团队将 ActivityNet、TutorialVQA,、YouCook2、STAR、ScaleLong 和 LVBench 六大主流数据集划分为互补的两类,并实施了 “缺什么补什么” 的数据增强策略:
针对 “有描述无推理” 的数据(如 ActivityNet、TutorialVQA、YouCook2):这类数据具备精确的时间段标注和详尽的动作描述,但缺乏深度的逻辑问答。团队利用 DeepSeek-R1 强大的逻辑推理能力,以原有的细粒度片段描述为上下文,合成出需要跨越多个时间片段进行综合分析的复杂多跳问题,将单纯的感知任务升级为逻辑推理任务。
针对 “有问答无细节” 的数据(如 STAR、ScaleLong、LVBench):这类数据虽然包含极具挑战性的推理问答,却往往缺失了支撑答案的具体视觉描述。团队借助 Gemini-2.5-Flash-Lite 的长窗口视觉理解能力,以标准答案为锚点进行反向推导,为关键时间窗口生成了与答案强相关的精细化视觉描述(Answer-Conditioned Captions),填补了推理过程中视觉证据的空白。
Step 2: 结构化思维链合成
在完成了基础信息的双向补全后,系统调用 DeepSeek-V3 执行 “反向推理合成(Reverse-Curation Generation)”。模型接收标准答案、时序标注以及生成的视觉描述作为输入,被要求倒推并生成一条逻辑严密、逐步展开的推理轨迹。这条轨迹并非自由发散,而是必须严格遵循预定义的结构化格式,显式地将推理过程拆解为三个关键动作:
<time>:执行时序定位任务,精确划定包含关键信息的视频时间窗口,明确模型 “关注哪里”;
<caption>:执行视觉证据提取任务,对该时间窗口内的核心视觉线索进行总结与描述,阐述模型 “看到了什么”;
<think>:执行深度分析任务,基于提取的时空线索进行逻辑推演与综合判断,连接视觉证据与最终答案,解释 “意味着什么”。
Step 3: 后见之明验证机制(Hindsight Curation)
这是保障数据质量的关键防线。为了确保合成的推理轨迹真实有效而非 “自说自话”,团队引入了创新的 “后见之明” 验证流程,替代了昂贵的人工抽检。具体而言,系统使用 Qwen2.5-VL-7B-Instruct 充当 “独立验证官”,在屏蔽原始视频输入的情况下,仅将上一步生成的 <time> 时序标签和 <caption> 视觉描述作为上下文输入给模型。系统随后检测验证官能否仅凭这些提取出的线索推导出正确的标准答案。如果验证失败,意味着生成的视觉线索不足以支撑推理结论,系统将自动触发再生流程,进行最多三次的迭代修正。
这种 “以结果验证过程” 的闭环机制,有效剔除了无效或低质量的样本,确保了最终保留在 Video-Thinker-10K 中的每一条数据,其视觉证据与逻辑结论之间都具备严密且可复现的因果关系。
监督微调建立结构化思维范式
监督微调(SFT)阶段旨在完成模型的 “冷启动” 初始化。由于预训练的多模态大模型本身并不具备输出特定标签(如 <time> 或 <caption>)的习惯,SFT 阶段的主要任务是通过强制教学,让模型习得 Video-Thinker 独有的结构化思考范式。
对于每一个样本 (V, Q, T, Y),其中 V 是视频,Q 是问题, T 是包含 <time>,<caption> 和 <think> 的思维链, Y 是最终答案。SFT 的优化目标是最小化思维链与答案的负对数似然:
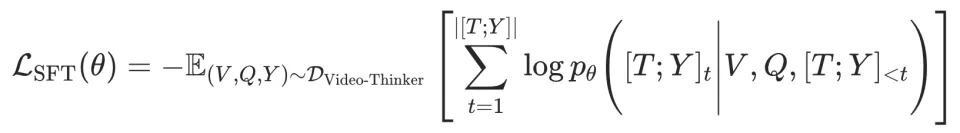
通过这一阶段的训练,模型不再将视频视为一个模糊的整体进行黑盒猜测,而是建立起了一套严谨的 “定位 - 感知 - 推理” 标准动作序列:即先通过 <time> 标签主动定位关键片段,再利用 <caption> 标签提取视觉细节,最后通过 <think> 标签进行逻辑整合。这种显式的思维约束,不仅教会了模型如何使用内部工具,更有效抑制了其在缺乏证据时直接生成答案的幻觉倾向,为后续的强化学习奠定了坚实的策略基础。
强化学习激发内生智能与 “顿悟” 时刻
虽然 SFT 赋予了模型结构化的表达形式,但仅凭监督微调,模型往往只能 “模仿” 训练数据的表面模式,难以应对分布外的复杂场景。真正的智能源于在探索中自我优化,因此训练进入第二阶段:采用组相对策略优化(Group Relative Policy Optimization, GRPO)激发模型的内生潜能。
不同于传统 PPO 算法依赖庞大的价值网络来评估状态价值,GRPO 采用了一种更为高效的策略:它通过对同一输入并行采样多组不同的推理轨迹,利用组内输出的相对优势来指导梯度更新。这种 “摒弃 Critic 模型” 的设计不仅大幅降低了显存占用和计算成本,更关键的是,它允许模型在反复的试错与自我博弈中,自主探索出如何更高效地调用 <time> 和 <caption> 锚点来解决新问题,从而将机械的格式遵循升华为灵活的视频思维能力,真正实现对视频内容的自主导航。
采样与双重奖励设计
对于每个输入 (V, Q),模型采样生成 G 组不同的推理轨迹 。为了兼顾推理的准确性与格式的规范性,团队设计了复合奖励函数:
。为了兼顾推理的准确性与格式的规范性,团队设计了复合奖励函数: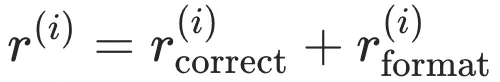
:结果导向,奖励最终答案是否命中真值 Y。
:过程约束,惩罚未遵循 <time> 和 <caption> 结构的行为,确保模型不偏离思考轨道。
策略优化目标
最终的优化目标通过最大化裁剪后的代理目标函数来更新参数 ,并引入 KL 散度约束防止策略突变:
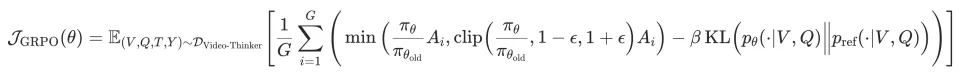
其中代表新旧策略的概率比。
涌现的 “Aha Moment”
经过 GRPO 的强化训练后,Video-Thinker 开始涌现出类似人类的高阶认知行为 —— 我们称之为 “顿悟时刻(Aha Moment)”。与传统模型线性的、单向的生成过程不同,Video-Thinker 在面对复杂推理时,不再是一条路走到黑。我们观察到,模型开始在思维链中自发展现出元认知(Metacognition)特征:它会对其初步生成的时序定位或视觉描述进行 “回头看”,主动发起自我质疑与修正。
这种动态的内部反馈机制,使得模型不再是被动的信息接收者,而是主动的探寻者。正是这种内生的反思能力,让 Video-Thinker 能够在仅有 7B 参数量且仅使用 10K 训练数据的情况下,打破了参数规模的限制,在 Video-Holmes 等高难度视频推理基准上,大幅超越了依赖海量数据训练的现有基线模型。
三、评测:全面验证,7B 模型刷新视频推理 SOTA
实验设置
为了全方位验证 Video-Thinker 的视频推理能力,研究团队构建了包含域内(In-Domain)与域外(Out-of-Domain)的双重评估体系。
训练配置: 研究选用 Qwen2.5-VL-7B-Instruct 作为基础模型。训练过程严格遵循 “两阶段” 范式:首先在 Video-Thinker-10K 数据集上进行 1 个 epoch 的监督微调(SFT),让模型习得结构化的思考格式;随后引入 GRPO 算法进行强化学习训练,以激发模型自主视频推理的潜能。
评测数据集:
域内评测:基于 ActivityNet、Star、ScaleLong、YouCook2、LVBench 等五个训练数据集构建了测试集(Held-out test sets),用于评估模型在熟悉领域内的表现。
域外评测:精选了 Video-Holmes、CG-Bench-Reasoning、VRBench、SciVideoBench、VideoTT、VideoMME 等六个具有挑战性的高难度复杂视频推理基准,重点考察模型在未知场景下的泛化能力。
基线模型: 对比阵容强大,涵盖了 InternVL、Qwen2.5-VL 等 5 个主流开源多模态基础模型,以及 Video-R1、VideoChat-R1、Temporal-R1 等 12 个开源视频推理模型,确保了比较的公平性与广泛性。
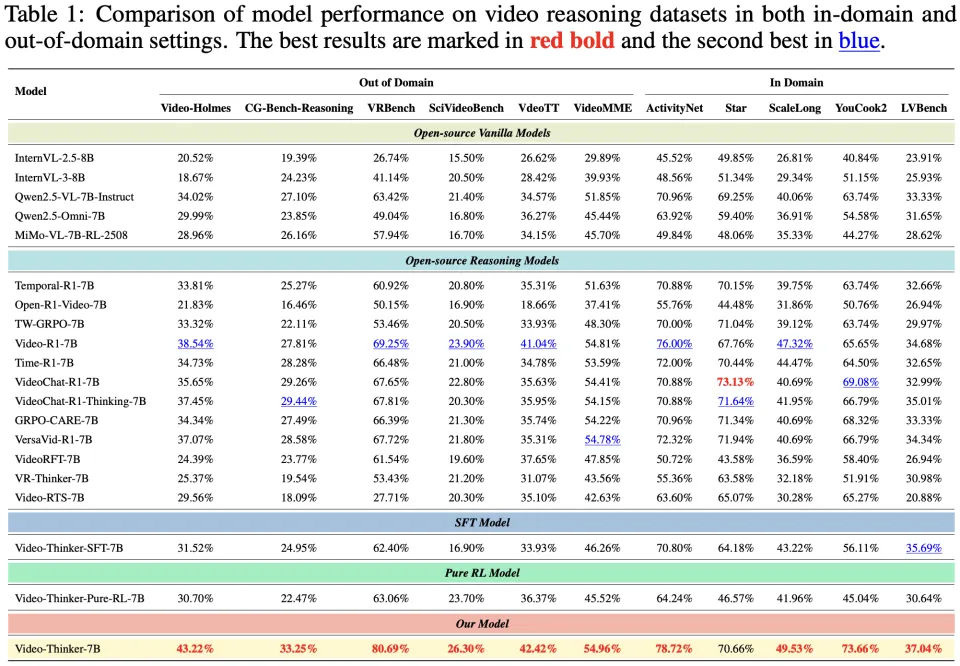
总体性能对比
实验结果表明,Video-Thinker-7B 在各项视频推理基准上均展现出显著优势,成功确立了 7B 参数量级模型的新 SOTA(State-of-the-Art)。
核心发现与数据解读:
域外泛化能力的质变: Video-Thinker 在处理未见过的复杂任务时表现尤为惊艳。在侦探推理类的 Video-Holmes 榜单上,模型取得了 43.22% 的准确率,超越了次优基线模型 4.68 个百分点;在综合性基准 VRBench 上,准确率高达 80.69%,大幅领先最佳基线 11.44%。这充分证明了 Video-Thinker 并非仅仅 “记住” 了训练数据,而是真正习得了通过 “定位” 和 “描述” 来解决通用视频问题的能力。
SFT 与 RL 的协同效应: 消融实验揭示了一个关键结论:仅靠 SFT 无法实现强泛化。Video-Thinker-SFT-7B 版本在多个基准上的表现甚至低于基础模型,这说明 SFT 的主要作用在于 “规范格式”。而随后的 GRPO 强化学习阶段才是性能飞跃的关键,它使模型在 Video-Holmes 上的性能提升了 11.70%,在 VRBench 上提升了 18.29%。这种 “先通过 SFT 立规矩,再通过 GRPO 练内功” 的组合,被证明是提升大模型复杂推理能力的必由之路。
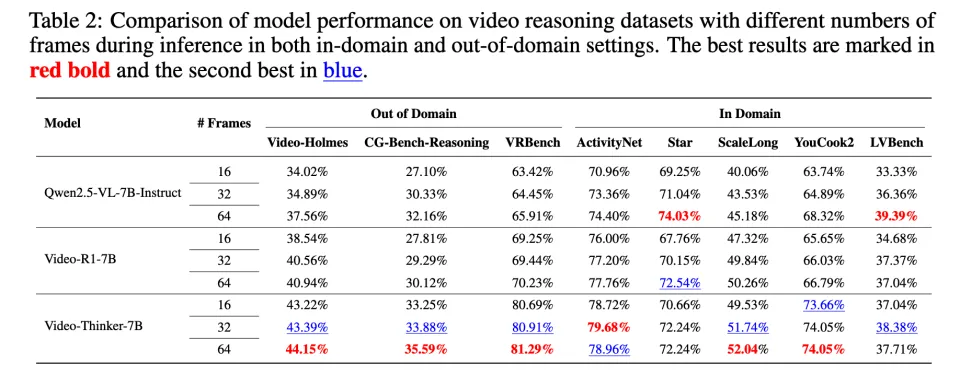
推理帧数鲁棒性分析:更高效的时序信息整合
视频理解往往受限于输入帧数。为了探究 Video-Thinker 是否依赖高帧率输入,团队对比了模型在 16 帧、32 帧和 64 帧设置下的表现。实验数据表明:
正向的 Scaling Law: 随着输入帧数从 16 增加到 64,绝大多数模型的性能均呈上升趋势,说明更丰富的时序信息确实有助于推理。
全方位的性能压制: 值得注意的是,Video-Thinker-7B 在所有帧数档位上均持续优于对比基线(Qwen2.5-VL 和 Video-R1)。即使在仅输入 16 帧的受限条件下,Video-Thinker 依然能保持高水准的推理精度。这意味着该模型具备更高效的时序信息整合机制,无论是在计算资源受限的低帧率场景,还是信息丰富的高帧率场景,都能稳定发挥。
深度归因分析:定位与描述能力的显著增强
Video-Thinker 的核心假设是:强大的视频推理源于对视频内容的精准 “定位(Grounding)” 和细致 “描述(Captioning)”。为了验证这一假设,研究团队不仅评测最终答案的准确率,还专门针对这两项中间过程能力进行了定量评测。评测结果表明:
时序定位(Grounding):在要求模型输出关键时间片段的任务中,Video-Thinker-7B 的平均交并比(mIoU)达到了 48.22%,相比基础模型(27.47%)提升了 75.5%。在 Recall@0.3 指标上,Video-Thinker 更是达到了 79.29%,几乎是基础模型的两倍。这表明模型在回答问题前,确实精准锁定了视频中的关键线索,而非盲目猜测。
内容描述(Captioning):在视频片段描述任务中,Video-Thinker 在 BLEU、METEOR 和 ROUGE-L 三大指标上全面领先。与基础模型相比,其整体描述质量提升了 31.2%;与 Video-R1 相比,提升幅度更是达到了 61.0%。生成更准确、更相关的中间描述,为模型进行后续的逻辑推理提供了坚实的信息基础。

消融实验:内生能力 vs 外部工具
既然 “定位” 和 “描述” 如此重要,是否可以直接给基础模型外挂现成的专用工具(如专门的 Grounding 模型或 Captioning 模型)来达到同样的效果?研究团队进行了一组反直觉但极具价值的对比实验。
1. 简单外挂工具的 “负优化” 陷阱:实验结果首先打破了 “工具越强效果越好” 的迷思。当团队尝试 “基础模型 + 即插即用工具(Plug-and-play Tools)” 的组合时,模型性能不升反降。例如,使用 Temporal-R1-7B 配合 SkyCaptioner-V1-8B 时,准确率跌至 30.58%;即便调用参数量大十倍的 Qwen2.5-VL-72B-Instruct 作为专家工具,其 33.96% 的得分依然未能超过仅使用 7B 基础模型的效果。这表明简单的工具堆叠会造成信息割裂,导致推理链路效率降低。
2. 现有工具调用方法的局限:为了进一步验证,团队对比了现有的代表性工具使用方法 —— VideoMind-7B。虽然 VideoMind-7B 通过更复杂的工具调用策略,将 Video-Holmes 的得分提升到了 38.98%,成功超越了基础模型和简单的外挂方案,但相比于 Video-Thinker 它依然存在明显差距(落后约 4.2%)。这说明即便是成熟的外部工具调用方式,在信息传递的连贯性和推理深度上仍存在天花板。
3. Video-Thinker 内生思维链的压倒性优势:最终,通过训练获得内生能力的 Video-Thinker-7B 展现了统治级的表现。它在 Video-Holmes 上取得了 43.22% 的全场最高分(红色加粗),不仅远超外挂工具方案,也显著优于 VideoMind-7B;同时在 VRBench 上更是达到了 80.69% 的高分。实验有力地证明,在视频推理任务中,将 “感知 - 定位 - 描述 - 推理” 无缝融合的内生思维链(Endogenous CoT),比简单的工具堆叠甚至 VideoMind 这种外部调用方法都更为高效可靠。

四、结语:内生智能引领视频推理新方向
Video-Thinker 的核心价值,在于打破了 “视频推理必须依赖外部工具” 的固有认知,通过 “高质量数据合成 + 精准强化训练” 的全链路设计,让 MLLM 真正实现内生 “时序定位” 与 “片段描述” 能力,实现了端到端的自主视频思考。其 7B 参数模型在多领域基准上刷新 SOTA 的表现,证明了视频推理能力并非依赖 “大参数 + 大数据” 的堆砌,而是在于对核心内生能力的精准培养。未来,随着技术迭代,Video-Thinker 有望进一步集成音频、字幕等多模态信息,拓展至小时级长视频推理场景,让 “用视频思考” 成为 MLLM 的基础能力。这种内生智能驱动的技术路径,不仅为视频推理领域提供了新范式,更将加速 AI 在安防监控、智能教育、工业运维等领域的落地应用,真正赋能千行百业的智能化升级。