注意力机制大变革?Bengio团队找到了一种超越Transformer的硬件对齐方案
Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。
然而,现有的线性递归或状态空间模型虽然在理论上具有线性复杂度,但在高性能 GPU 上的实际表现往往并不如人意,会受限于内存带宽和全局同步带来的高昂通信成本。
近日,Radical Numerics 与蒙特利尔大学 Yoshua Bengio 团队找到了一个新思路,为 LLM 的效率进化提供了一个极具启发性的工程视角。该团队通过将线性递归重新定义为硬件对齐的矩阵运算,提出了一套能够相当完美契合 GPU 内存层级的算法框架。

论文标题:Sliding Window Recurrences for Sequence Models
论文地址:https://arxiv.org/abs/2512.13921
该研究有三位共同作者:Dragos Secrieru、Garyk Brixi 和 Stefano Massaroli。他们都是 Radical Numerics 的成员,这家旨在打造科学超级智能的创业公司已经取得了一些亮眼的突破性进展,包括首批使用百万级上下文窗口训练的模型以及 Evo 和 Evo 2 这两个生成式基因组学模型。
核心挑战:打破线性递归的「内存墙」
该团队首先指出,尽管并行扫描(Parallel Scan)算法在逻辑上能以 O(log n)的深度并行化处理递归,但它们在现代分级内存硬件上表现得并不理想。
传统的并行扫描算法,如 Kogge-Stone,具有极低的算法深度,但其数据访问模式往往跨越全局地址空间,导致频繁的全局内存同步和洗牌操作。

在 GPU 这种具有多级缓存(寄存器、共享内存、显存)的架构中,这种「扁平化」的算法策略不仅无法有效利用数据局部性,更无法发挥 Tensor Core 等专用矩阵乘法硬件的计算峰值。
这种由于数据移动而非计算本身导致的瓶颈,正是长文本大模型训练和推理中亟待解决的「内存墙」问题。
为了从数学层面拆解这一问题,论文引入了转移算子(Transfer Operator)的矩阵理论。
线性递归系统 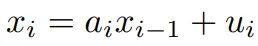 可以被视为一个单位下三角线性系统
可以被视为一个单位下三角线性系统  。通过对该系统进行分块处理,该团队揭示了转移矩阵 𝑳 背后深层的层级分解结构:
。通过对该系统进行分块处理,该团队揭示了转移矩阵 𝑳 背后深层的层级分解结构: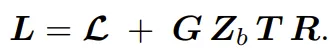
在这个公式中,𝓛 代表各数据块内部的独立计算,而 则描述了跨块之间的「载体(Carrier)」信息传递。
这一分解揭示了一个关键点:跨块通信的本质是秩 - 1(Rank-one)的低秩更新。这为消除全局同步提供了理论上的切入点。
解决方案:滑动窗口循环与 B2P 算法
该论文最核心的贡献是提出了滑动窗口循环(SWR),这是一种通过策略性截断计算视界来换取极高吞吐量的原语。
作者观察到,在实际训练的稳定系统中,系数 a_i 往往满足 ,这意味着输入对状态的影响会随距离呈指数级衰减。因此,强制维护长程依赖在数值上往往是冗余且昂贵的。SWR 采用了独特的锯齿状窗口(Jagged Window)结构,而非传统的均匀窗口,这种结构能自然地对齐硬件的工作负载。
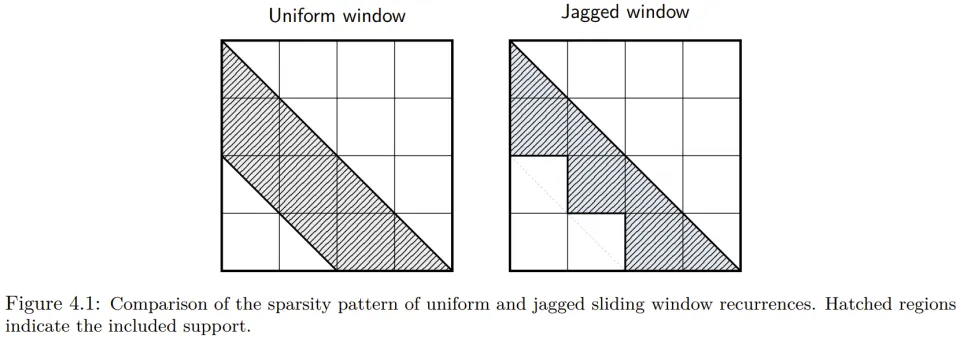
为了将这一理论落地,作者开发了块两步(Block Two-Pass, B2P)算法及其对应的 CUDA 内核。
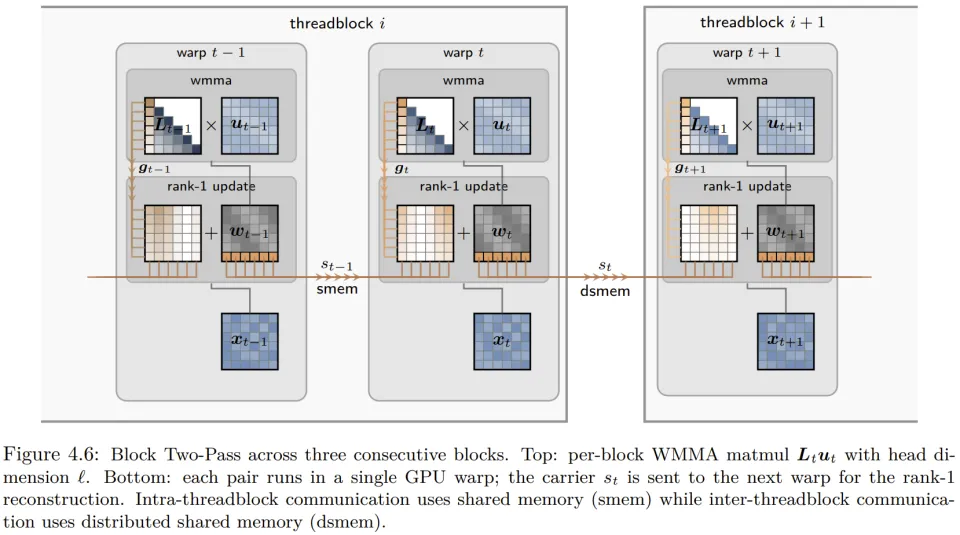
该算法将计算过程分为两个阶段:
在第一阶段,每个线程束(Warp)并行处理一个大小为 16 的本地块(与 Warp 大小对齐),利用 Tensor Core 通过 GEMM 方式完成高效的本地递归求解。
在第二阶段,算法通过 GPU 片上的共享内存(SMEM)或分布式共享内存(DSMEM)在相邻块之间传递状态载体,并进行即时的秩-1 补偿。
这种设计确保了输入数据只需从显存读取一次,所有中间通信均发生在芯片内部,实现了接近恒定的 O (1) 算法深度和极佳的硬件利用率。

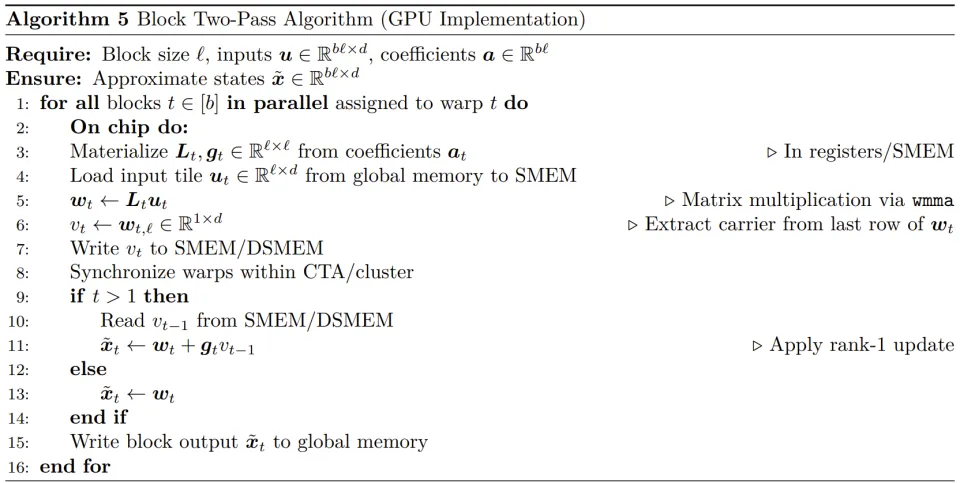
Phalanx 层设计与层级架构集成
基于 B2P 算法,作者设计了名为 Phalanx 的新型计算层,它可以作为滑动窗口注意力或线性递归层的无缝替代品。在层参数化方面,Phalanx 遵循极简原则,通过 Sigmoid 激活函数将递归系数 a_i 限制在 (0, 1) 的稳定区间内,从而保证了长序列处理时的数值稳定性。

同时,该层采用了基于头(Head)的参数共享模式,每个头共享一套递归系数,这与 Tensor Core 处理 16×16 矩阵瓦片的计算模型完美契合。
Phalanx 被定位为混合架构中的「局部专家」,专门负责高效捕获短程令牌互动,而将长程路由任务交给全局注意力层。这种职能分工使得模型能够在不损失精度的前提下,大幅减少跨内存层级的数据移动。
更多细节请访问原论文。
实验结果:速度与质量的双重突破
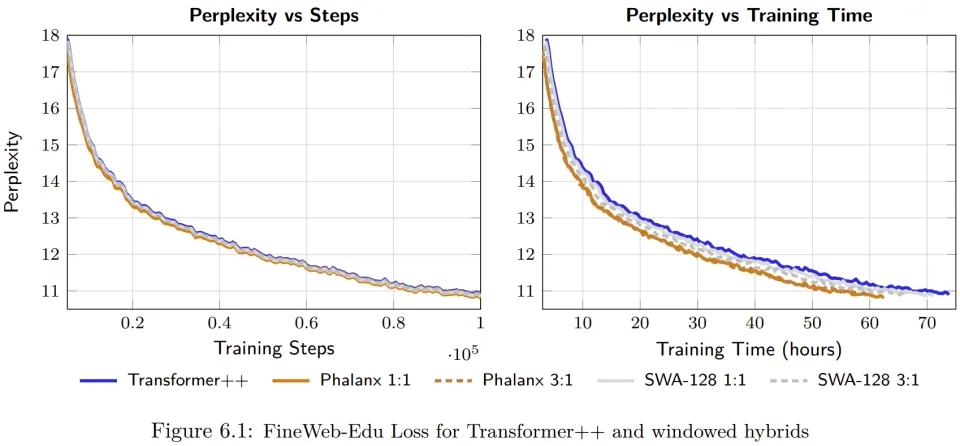
在针对 1.3B 参数规模模型的系统性测试中,Phalanx 展现出了显著的性能优势。在 FineWeb-Edu 数据集上,Phalanx+Attention 混合模型在多个维度上超越了优化的 Transformer 和滑动窗口注意力(SWA)基准。
在训练吞吐量方面,当上下文长度在 4K 到 32K 之间时,Phalanx 混合模型实现了 10% 到 40% 的端到端提速。
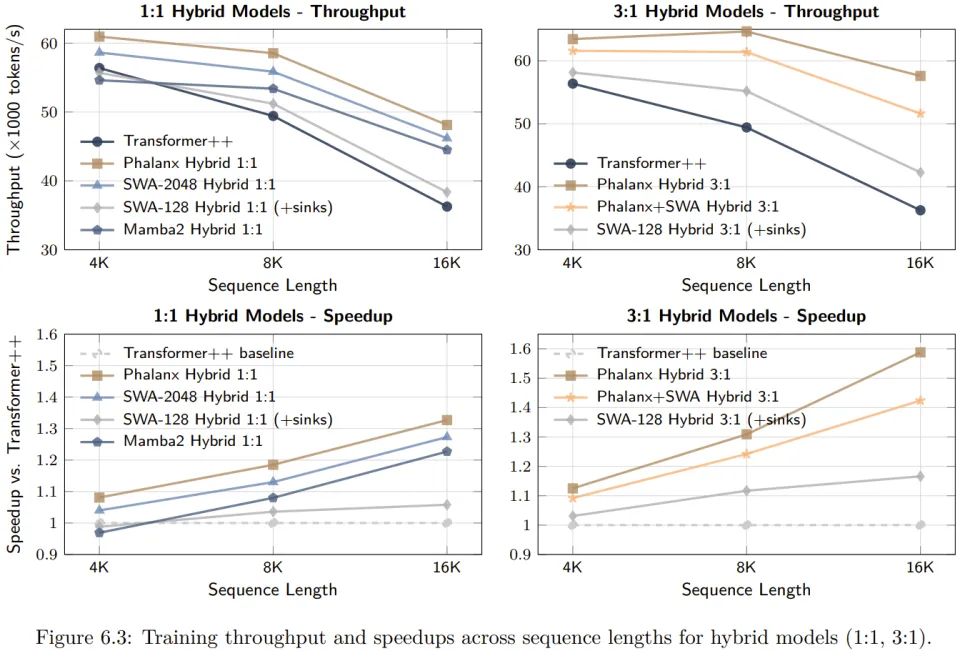
在 8K 上下文的训练任务中,Phalanx 混合模型的训练速度比传统的 SWA/Attention 混合架构快 28%,甚至在短序列长度下也表现卓越,在 Hopper GPU 上比纯注意力模型提升了 10% 的训练吞吐量。
在模型精度方面,实验数据显示 Phalanx 在匹配 Transformer++ 基准性能的同时,甚至在特定比例下取得了更低的困惑度。
例如,在 1:1 的混合比下,Phalanx 达到了 10.85 的困惑度,优于 Transformer++ 的 10.95。
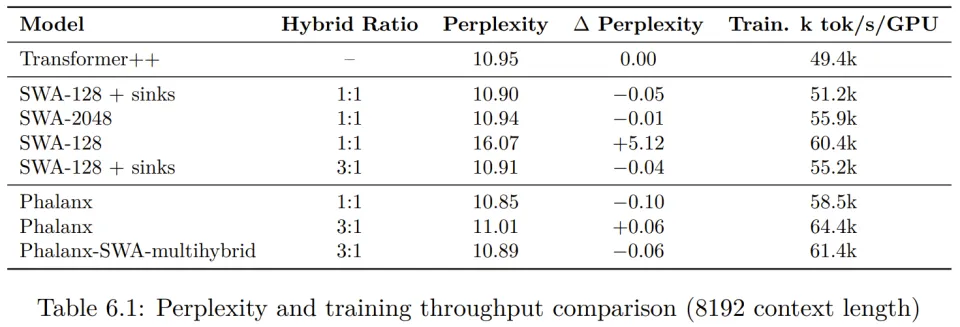
此外,通过对衰减系数和门控机制的消融实验,作者证明了其精心设计的参数化方案对于维持模型表现的关键作用。更多详情请参阅原论文。
总结与行业意义
《Sliding Window Recurrences for Sequence Models》为下一代长文本模型架构指明了一个方向:真正的效率并非仅仅来自算法复杂度的降低,更来自于对底层计算硬件物理特性的深刻理解与对齐。
通过将数学上的线性递归转化为硬件友好的块级矩阵运算,Phalanx 层成功在训练速度与模型质量之间找到了一个更优的平衡点。
随着 2025 年之后 LLM 继续向超大规模上下文和实时具身智能演进,这种硬件感知的算子设计将成为构建更绿色、更强大 AI 系统的核心基石。