多模态推理新范式!DiffThinker:用扩散模型「画」出推理和答案

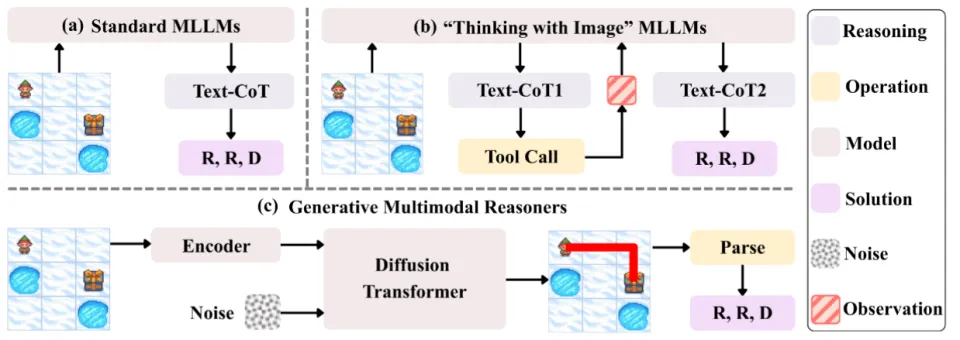
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
尽管近期的「Thinking with Image」范式可以通过工具等对图像进行操作,但它们难以扩展到更复杂的长程任务,且在多轮交互中本身开销巨大。
近日,来自上海人工智能实验室、南京大学、香港中文大学和上海交通大学的研究团队提出了一种全新的生成式多模态推理(Generative Multimodal Reasoning)范式,并发布了模型 DiffThinker。
DiffThinker 彻底打破了「多模态输入 -> 文本输出」的传统定式,将推理过程重构为图像到图像(Image-to-Image)的生成任务。通过扩散模型(Diffusion Models),DiffThinker 能够在视觉空间中直接生成推理路径。
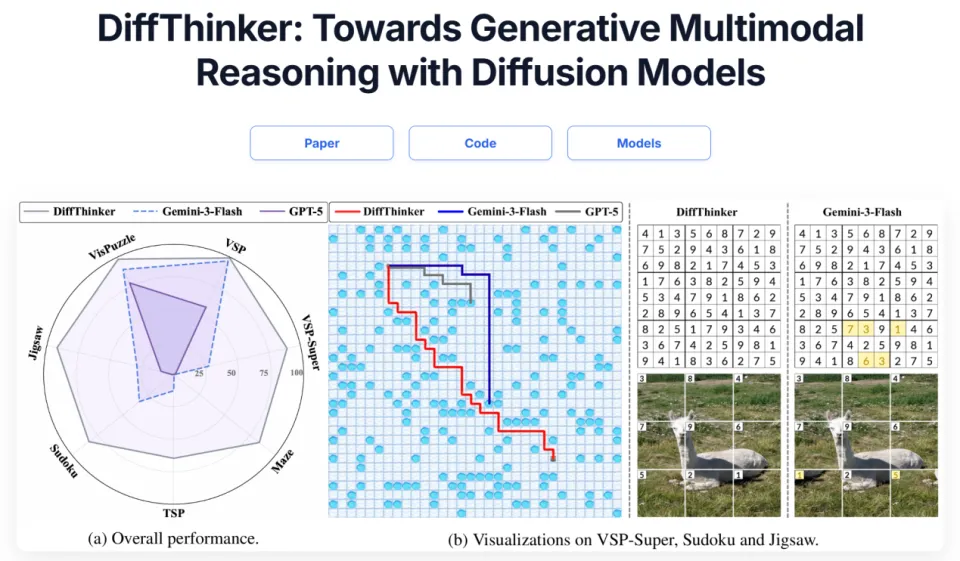
实验结果令人惊讶:在包含长程规划、组合优化、约束满足、空间推理等 7 项视觉中心的复杂任务中,DiffThinker 的表现显著优于包括 GPT-5 (+314.2%) 和 Gemini-3-Flash (+111.6%) 在内的顶尖闭源模型,以及经过相同数据微调的 Qwen3-VL-32B 基线 (+39.0%)。
论文标题:DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
论文地址:https://arxiv.org/abs/2512.24165
项目主页:https://diffthinker-project.github.io
代码仓库:https://github.com/lcqysl/DiffThinker

01 从「以文思考」到「以图思考」
现有的多模态大模型在处理视觉推理任务时,难以追踪视觉信息的变化。比如在空间导航任务(VSP、Maze 等)中,模型仅靠语言分析路径,但输入图像不变,路径一长就很容易「看走眼」,不知道自己已经走到了哪。又比如拼图任务,模型如果不能直接对拼图操作,很难凭空想象出答案。即便是最新的「Thinking with Image」范式,也往往依赖于多轮对话和工具调用,导致推理链路极长,难以扩展到复杂场景。
研究团队还在项目主页提供了几个小游戏,以直观理解人与 MLLM 的思维范式差异。
那么,为什么不能让模型直接「看」着问题,把答案「画」出来?
DiffThinker 提出的核心理念正是如此。研究团队认为,多模态推理不应局限于符号空间,而应回归视觉空间,利用扩散模型直接生成答案。具体来说,DiffThinker 基于 Qwen-Image-Edit,配合 Flow Matching 训练直接用图像生产答案。
02 DiffThinker 的四大核心特性
作为全新的生成式推理范式,DiffThinker 展现出了传统 MLLM 难以企及的四大特性:
高效推理(Efficient Reasoning)相比于 MLLM 动辄生成数千个 Token 的长思维链,DiffThinker 在训练和推理效率上均表现出色,且准确率更高。
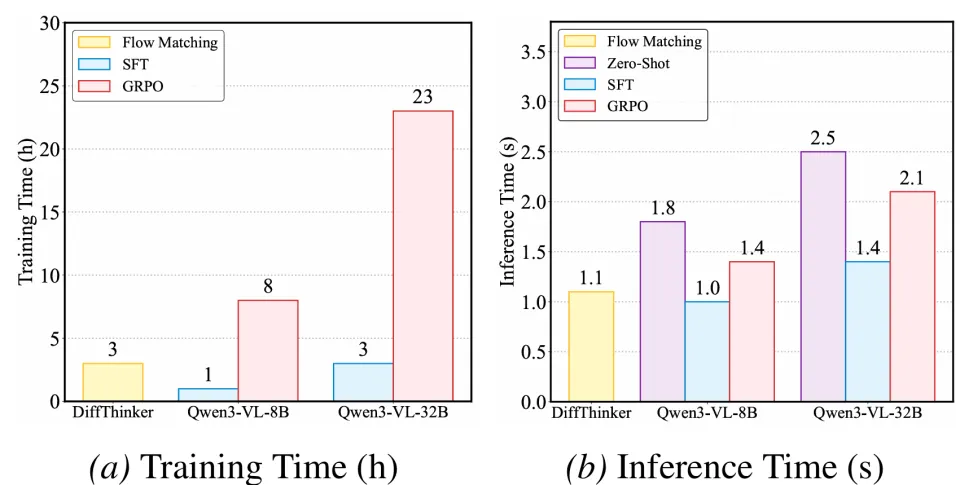
可控推理(Controllable Reasoning)MLLM 的输出长度不可预测,常出现过长思维链甚至输出崩溃导致死循环。而 DiffThinker 通过固定步数的欧拉求解器,能够以确定的计算预算完成推理,不受任务逻辑复杂度的干扰。
原生并行推理(Native Parallel Reasoning)这是扩散模型独有的优势。在推理时,DiffThinker 能够在视觉空间中同时探索多条潜在路径,并随着去噪过程逐步收敛到最优解。这使得模型可以「边画边推理」,更直观。

协同推理(Collaborative Reasoning)DiffThinker 还可以与 MLLM 合作。它生成多个候选视觉解,再由 MLLM 进行逻辑验证。实验显示,这种「DiffThinker 生成 + MLLM 验证」的组合,性能实现「1+1>2」,超越了任何单一模型。

03 实验结果:碾压级的性能
研究团队在四个领域的七大任务上进行了系统评测,包括:
序列规划:VSP,VSP-Super,Maze(迷宫)
组合优化:TSP(旅行商问题)
约束满足:Sudoku(数独)
空间配置:Jigsaw(拼图),VisPuzzle
主要结果如下:
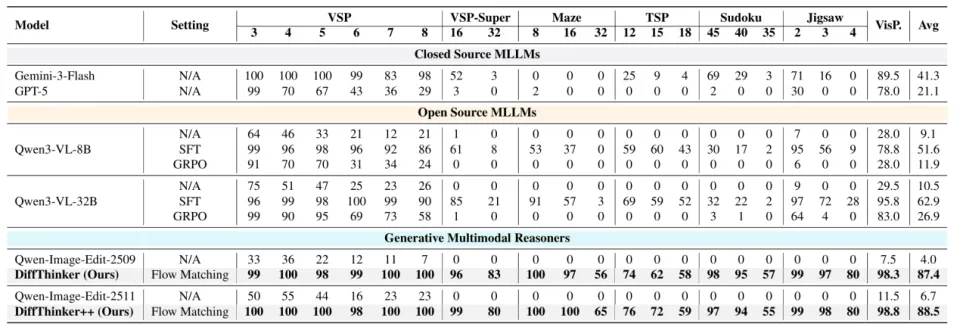
DiffThinker 在所有任务上的平均得分高达 87.4,而 GPT-5 仅为 21.1,Gemini-3-Flash 为 41.3。同数据训练的 Qwen3-VL-32B 也只有 62.9。
04 视频生成 vs 图像生成
既然是视觉推理,用视频模型(Video Generation)会不会更好?
团队基于 Wan2.2-TI2V-5B 开发了 DiffThinker-Video 版本。结果发现,虽然视频能展示动态过程,但在推理准确率上反而不如图像生成模型,且推理时间增加了近一倍(1.1s vs 2.0s)。这表明,在当前的算力与模型架构下,「以图思考」仍是比「以视频思考」更高效的路径。
05 结语
DiffThinker 的出现,标志着 生成式多模态推理(Generative Multimodal Reasoning) 时代的开启。它证明了扩散模型不仅能画画,还能进行严密的逻辑推理。
对于长程、视觉中心的复杂任务,将推理过程从「文本流」转变为「视觉流」,或许正是通往下一代通用人工智能的关键一步。