让两个大模型「在线吵架」,他们跑通了全网95%科研代码|深势发布Deploy-Master

机器之心发布
科学计算领域已经积累了数量空前的开源软件工具。从生物信息学、化学模拟,到材料计算、物理仿真与工程设计,几乎每一个学科方向,都形成了自己的生态。在 GitHub 等平台上,成千上万个代码仓库声称可以被用于科研实践。
但一个长期存在、却始终没有被系统性解决的事实是:绝大多数科学软件,停留在 “被发布过”,而不是 “可以直接运行” 的状态。
在科研实践中,我们往往需要花费数天甚至数周时间反复解决编译失败、依赖冲突、系统不兼容等问题,才能在本地 “勉强跑通” 一个工具。这样的运行环境高度依赖个人经验,往往是临时的、不可移植的,也很难被他人复现或复用。每个研究者、每个实验室,都在手工维护自己的运行环境,而不是在一个共享、可复现的执行基础设施之上开展工作。
这种模式带来的问题,并不只是效率低下。更关键的是,它在结构上限制了科学软件的三件事情:可复现性、大规模评估,以及系统性集成。即便容器化、云计算和 HPC 平台已经显著降低了算力门槛,这一 “部署瓶颈” 依然真实存在,并且长期制约着科学软件的可用性。
随着 AI for Science(AI4S) 的兴起,这一问题被进一步放大。在新的科研范式中,AI 系统不再只是输出预测结果,而是需要与真实的科学工具发生紧密交互:调用求解器、执行模拟程序、运行分析管线、处理真实数据。在这样的背景下,一个工具是否 “真的能跑”,不再是工程细节,而是第一性问题。
这一问题在 Agentic Science 场景中表现得更加尖锐。如果工具依赖隐含环境、执行高度脆弱,那么智能体的规划将无法真正落地,执行失败也无法被结构化分析,更不可能转化为可学习的执行轨迹。
从这个角度看,工具是否部署就绪,已经成为制约 AI4S 与 Agentic Science 规模化发展的结构性瓶颈。
基于这些观察,我们逐渐形成了一个判断:科学软件的问题,并不在于工具不够多,而在于缺乏一个能够将工具系统性转化为可执行事实的共享基础设施。Deploy-Master,正是在这一背景下被提出的。
在真实世界中,部署并不是一个孤立步骤,而是一条连续链路:工具能否被发现、是否被正确理解、能否构建环境,以及是否真的可以被执行。Deploy-Master 正是围绕这条链路,被设计为一个以执行为中心的一站式自动化工作流。
Search Agent
搜索科研锚点
在大规模场景下,部署的第一个难题并不在构建,而在于发现。如果候选工具集合本身存在系统性偏差,后续所有自动化都会被放大为偏差。
为此,我们从 91 个科学与工程领域出发,构建了一个覆盖 AI4S 实际应用场景的学科空间,并使用语言模型扩展搜索关键词,在 GitHub 与公共网络中进行大规模检索。初始召回得到的仓库,会作为 “锚点”,通过依赖关系、引用关系、共享贡献者和文档链接等信号进行迭代扩展,从而避免仅依赖关键词搜索带来的盲区。
随后,我们通过结构启发式规则剔除明显不可执行的仓库,并由 Agent 进行语义判断,确认其是否构成一个可执行科学工具。通过这一多阶段漏斗流程,我们将最初约 50 万个仓库,收敛为 52550 个进入自动部署流程的科学工具候选。这一步的意义,不仅在于筛选工具,更在于第一次以结构化方式刻画了真实科学工具世界的规模与边界。
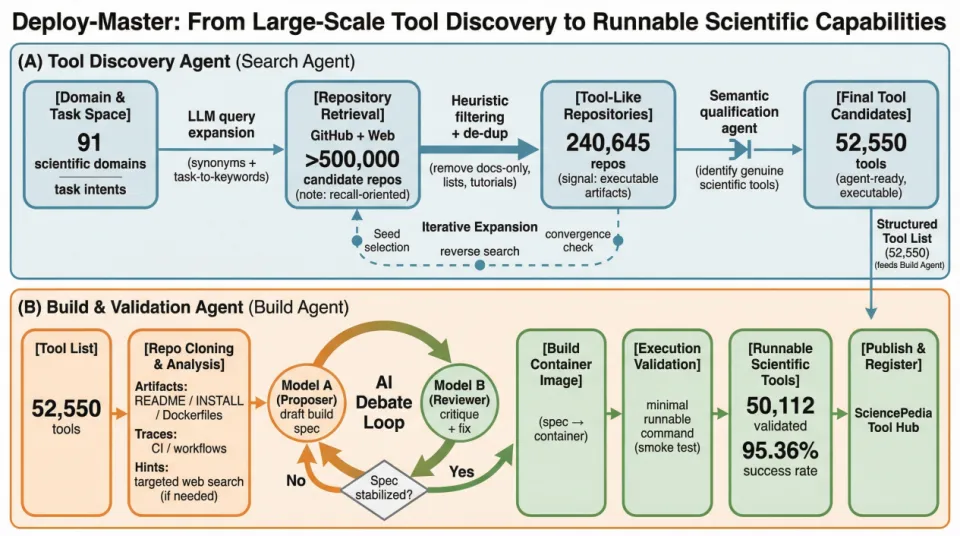
双模型博弈
实现 95% 成功率
在构建阶段,我们面对的并不是一个 “有明确说明书” 的世界。大量科学软件仓库的构建信息是零散的、不完整的,甚至相互矛盾的。README 文件可能早已过期,已有 Dockerfile 也未必反映当前代码状态,而关键依赖往往只存在于作者本地环境中。
Build Agent 会系统性地遍历仓库中的构建线索,并在必要时进行补充信息检索,生成初始构建方案。早期实验表明,仅依赖单一模型生成构建规格,成功率只有 50%–60%,失败主要源于构建信息中大量隐含、未被显式表达的假设。
为此,Deploy-Master 引入了双模型评审与辩论(debate)机制:一个模型提出构建规格,另一个模型独立审查并主动寻找潜在不一致、缺失依赖或环境假设,提出修正建议。两者通过多轮交互,不断修正方案,直到形成稳定、可执行的构建规格。这一机制将整体成功率提升到了 95% 以上。
每一个工具最终都会通过一个最小可执行命令进行验证。只有通过执行验证的工具,才会被视为成功部署,并被进一步结构化、注册和发布到玻尔与 SciencePedia 上,使其可以被直接使用,或被其他 Agent(例如 SciMaster)调用。

从构建时间的分布来看,大规模部署并不是一个 “均匀” 的过程。尽管大多数工具可以在 7 分钟左右完成构建,但整体分布呈现出明显的长尾特征。一部分工具仅包含轻量级脚本或解释型代码,构建过程相对简单;而另一部分工具则涉及复杂的编译流程、深层依赖以及系统级库配置,其构建时间显著更长。
这种差异并不会阻止整体流程的推进,但它决定了部署在规模化条件下的成本结构。
在成功部署的 50112 个工具中,我们观察到一个高度异构的语言分布。工具覆盖了 170 多种编程语言,其中 Python 占据了最大比例,其次是 C/C++、Notebook 形式的工具、R、Java 等。绝大部分语言部署成功率都稳定维持在较高水平。少数成功率相对较低的语言,主要集中在依赖复杂编译链或系统级库的场景,例如 C/C++、Fortran 以及部分 R 工具。
这并不意味着这些语言 “天生更难部署”,而是反映了其工具链对底层环境的耦合程度更高,从而放大了构建规格中的不确定性。从部署的角度看,语言本身并不是决定性因素,环境耦合强度才是。在 2438 次失败的构建尝试中,我们对失败原因进行了系统性统计。结果显示,失败并非均匀分布,而是高度集中在少数几类问题上。最主要的失败来源是构建流程错误,包括构建步骤与仓库当前状态不一致、关键依赖缺失、编译器或系统库不匹配等。这类失败远远多于资源不足、网络异常或权限问题。与此同时,资源相关错误在高并发阶段也确实出现过,并直接推动了我们对调度策略和隔离机制的后续改进。
这进一步说明,在规模化部署中,失败不应被视为异常,而应被视为系统暴露问题、进而自我修正的信号。
通过统一的执行基础设施,我们得以系统性地观察科学软件在真实环境中的部署行为:哪些环节最容易失败,哪些隐含假设最常被触发,哪些工具链最容易放大不确定性。这种可观测性本身,正是 Deploy-Master 希望建立的基础之一。它让 “科学软件难以部署” 从一种经验判断,转化为可以被量化、被分析、被持续改进的工程对象。
为 Agentic Science 构建行动基座
Deploy-Master 的直接产出,是一个由数万条执行验证工具构成的集合。但更重要的是,它为社区 Agent 与各类 Master Agent 提供了一个长期缺失的基础前提。
对 Agent 而言,工具调用并不是抽象动作,而是必须在现实环境中成功落地的执行过程。只有当工具被统一构建、验证并注册为可执行能力,Agent 才真正拥有稳定的 action space,规划、执行与学习之间的闭环才得以成立。这也使得不同来源的社区 Agent,可以共享同一批经过执行验证的工具能力,而不再各自维护脆弱、不可复现的运行环境。
这一方法论的意义,并不局限于科学计算。科学工具往往被视为自动化部署中最困难的一类:依赖复杂、系统耦合强、文档不完整、对环境高度敏感。如果在这样一个 “最难场景” 中,仍然可以通过以执行为中心的设计,在万级规模下稳定地产生可运行工具,那么结论已经非常清晰 —— 问题不在工具类型,而在于是否建立了以执行为核心的基础设施。
这一判断同样适用于更广泛的软件工具生态:工程工具、数据处理系统、专业软件乃至各类 Agent Tooling。只要工具最终需要被执行,其部署问题就无法绕开 “不完美信息” 这一现实前提。
Deploy-Master 并未解决所有问题。异构硬件、分布式计算、语义级 I/O 接口以及与物理实验系统的闭环集成,仍然是未来需要面对的挑战。但有一件事情已经足够清楚:在 Agentic Science 时代,执行不是推理之后的附属步骤,而是所有能力得以成立的前提。
当 “工具能不能跑” 不再是一个默认假设,而成为一个被系统性验证的事实,科学智能体才真正开始拥有与现实世界交互的基础。而 Deploy-Master,正是迈向这一执行现实的一次尝试。