联邦学习不再安全?港大TPAMI新作:深挖梯度反转攻击的内幕
本文第一作者郭鹏鑫,香港大学博士生,研究方向是联邦学习、大模型微调等。本文共同第一作者王润熙,香港大学硕士生,研究方法是联邦学习、隐私保护等。本文通讯作者屈靓琼,香港大学助理教授,研究方向包含 AI for Healthcare、AI for Science、联邦学习等 (个人主页:https://liangqiong.github.io/)。
联邦学习(Federated Learning, FL)本是隐私保护的「救星」,却可能因梯度反转攻击(Gradient Inversion Attacks, GIA)而导致防线失守。
近日,香港大学、香港科技大学(广州)、南方科技大学、斯坦福大学、加州大学圣塔克鲁兹分校的研究团队合作,在人工智能顶级期刊 IEEE TPAMI 上发表重磅工作,对 GIA 进行了全方位的分类、理论分析与实验评测,并提出了切实可行的防御指南。

论文标题: Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
论文地址: https://ieeexplore.ieee.org/document/11311346
项目主页: https://pengxin-guo.github.io/FLPrivacy/
01 背景:联邦学习真的安全吗?
联邦学习(FL)作为一种隐私保护的协同训练范式,允许客户端在不共享原始数据的情况下共同训练模型。然而,近年来的研究表明,「不共享数据」并不等于 「绝对安全」。
攻击者可以通过梯度反转攻击(GIA),仅凭共享的梯度信息就能重建出客户端的私有训练数据(如人脸图像、医疗记录等)。尽管学术界提出了许多 GIA 方法,但一直缺乏对这些方法的系统性分类、深入的理论分析以及在大规模基准上的公平评测。
为了填补这一空白,本研究对 GIA 进行了抽丝剥茧般的深度剖析。
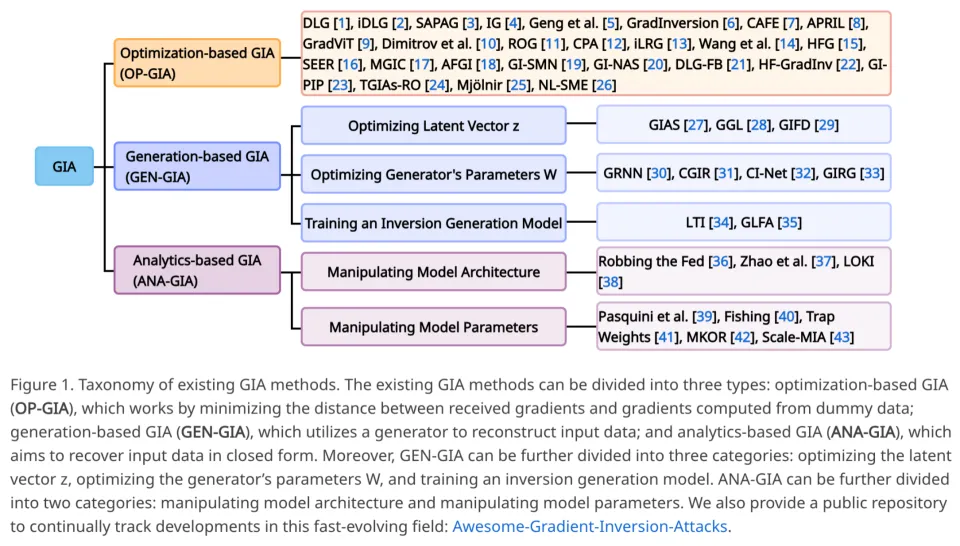
02 方法分类:GIA 的三大门派
研究团队首先对现有的 GIA 方法进行了系统性梳理,将其归纳为三大类:
1. 基于优化的攻击 (OP-GIA):
原理:通过迭代优化虚拟数据,使其产生的梯度与真实梯度之间的距离最小化。
代表作:DLG、Inverting Gradients、GradInversion 等。
2. 基于生成的攻击 (GEN-GIA):
原理:利用预训练的生成模型(GAN 或 Diffusion Model)作为先验,来生成近似的输入数据。
细分:优化隐向量 z、优化生成器参数 W、或训练逆向生成模型。
3. 基于分析的攻击 (ANA-GIA):
原理:利用全连接层或卷积层的线性特性,通过解析解(Closed-form)直接恢复输入数据。
特点:通常需要恶意的服务器修改模型架构或参数。
03 理论突破:误差边界与梯度相似性
不同于以往的经验性研究,本文在理论层面做出了重要贡献:
Theorem 1(误差边界分析):首次从理论上证明了 OP-GIA 的重建误差与 Batch Size(批量大小)和图像分辨率的平方根呈线性关系。这意味着,Batch Size 越大、分辨率越高,攻击难度越大。

Proposition 1(梯度相似性命题):揭示了模型训练状态对攻击的影响。如果不同数据的梯度越相似(例如在模型训练后期),攻击恢复数据的难度就越大。

04 实验发现:谁是真正的威胁?
研究团队在 CIFAR-10/100、ImageNet、CelebA 等数据集上,针对不同攻击类型进行了广泛的实验(涵盖 ResNet、ViT 以及 LoRA 微调场景)。
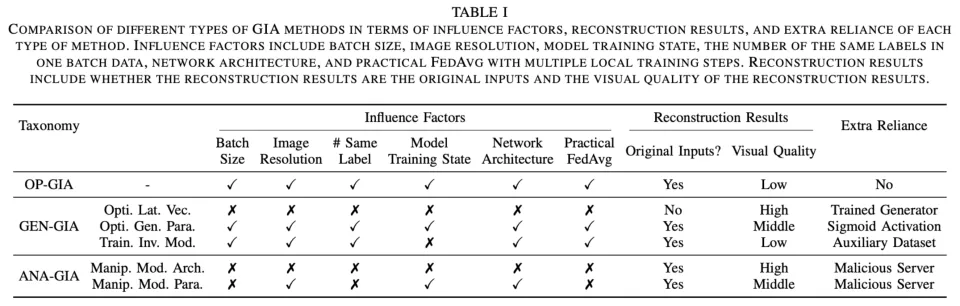
关键结论(Takeaways):
OP-GIA 最实用,但受限多:它是最实用的攻击设置(无额外依赖),但效果受限于 Batch Size 和分辨率。且在 Practical FedAvg(多步本地训练)场景下,其威胁被大幅削弱。
GEN-GIA 依赖重,威胁小:虽然能生成高质量图像,但严重依赖预训练生成器、辅助数据集或特定的激活函数(如 Sigmoid)。如果目标模型不用 Sigmoid,很多 GEN-GIA 方法会直接失效 。
ANA-GIA 效果好,易暴露:通过修改模型架构或参数,ANA-GIA 可以实现精准的数据恢复。但这种「做手脚」的行为非常容易被客户端检测到,因此在实际中难以得逞 。
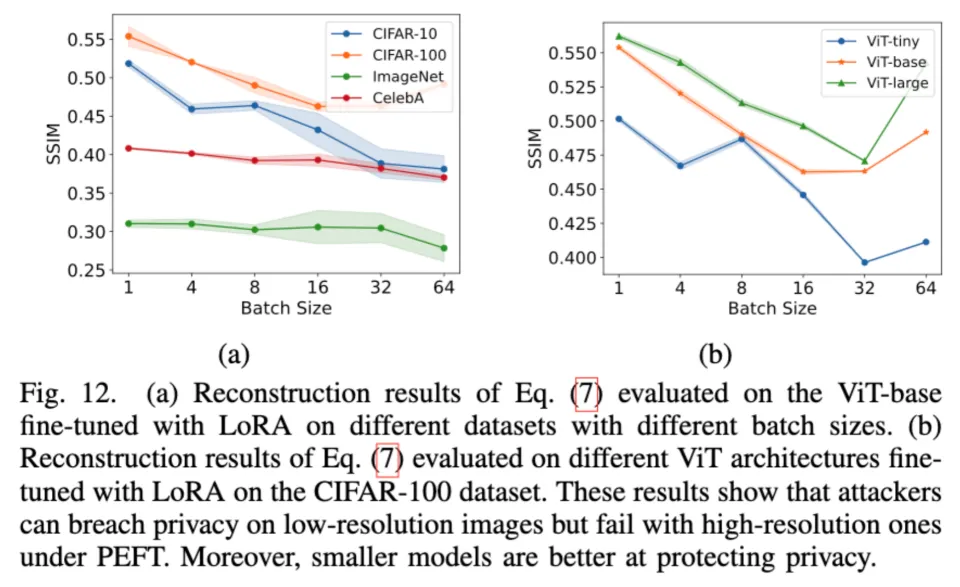
PEFT (LoRA) 场景下的新发现:在利用 LoRA 微调大模型时,攻击者可以恢复低分辨率图像,但在高分辨率图像上往往失败。且预训练模型越小,隐私泄露风险越低 。
05 防御指南:三步走策略
基于上述深入分析,作者为联邦学习系统的设计者提出了一套「三阶段防御流水线」,无需引入复杂的加密手段即可有效提升安全性 :
1. 网络设计阶段:
拒绝 Sigmoid:避免使用 Sigmoid 激活函数(易被 GEN-GIA 利用)。
增加复杂度:采用更复杂的网络架构,增加优化难度。
2. 训练协议阶段:
增大 Batch Size:根据理论分析,大 Batch 能有效混淆梯度。
多步本地训练:采用 Practical FedAvg,增加本地训练轮数,破坏梯度的直接对应关系。
3. 客户端校验阶段:
模型检查:客户端在接收服务器下发的模型时,应简单校验模型架构和参数,防止被植入恶意模块(防御 ANA-GIA)。
06 总结
这项发表于 TPAMI 的工作不仅是对现有梯度反转攻击的一次全面体检,更是一份实用的联邦学习安全避坑指南。它告诉我们:虽然隐私泄露的风险真实存在,但通过合理的设计和协议规范,我们完全可以将风险控制在最低水平。
更多细节,欢迎查阅原论文!