大模型听懂语音却反而变笨?港中深与微软联合解决语音大模型降智问题
从 GPT-4o 开启全能(Omni)交互时代至今,Speech LLM 虽然在拟人化和低延迟上取得了长足进步,但面临一个令人困扰的现象:当大语言模型(LLM)被赋予 “听觉” 后,它的智商下降了。
即便是同样的底层模型,一旦输入从文本变成语音,其逻辑推理能力(Reasoning)往往会显著衰退。这种现象被称为 “模态推理鸿沟”(Modality Reasoning Gap)。
这个难题并非仅存在于学术界,而是 OpenAI、Google、Meta 等行业巨头都在试图跨越的 “天花板”:
根据 Big Bench Audio 评测,以 GPT-4o 为例,在纯文本任务(Text-to-Text)的准确率达 92%;但一旦切换到端到端语音模式(Speech-to-Speech),其得分跌至 66%。这中间 26% 的巨大跌幅,就是模型引入语音而付出的代价。
Google Gemini 团队在技术分享中将其定义为 Intelligence Gap;而 Meta 研究员在 NeurIPS 2025 上更是直言这是一种 Intelligence Regression,并提出了一个生动的概念 Multimodal Tax,即引入音频等多模态数据往往会 “挤占” 模型用于纯推理的能力。


为了解决这一核心痛点,香港中文大学(深圳)与微软团队联合提出了 TARS (Trajectory Alignment for Reasoning in Speech)。这是一项基于强化学习(RL)的全新对齐框架,它不依赖死记硬背的监督微调,而是通过对齐 “思维轨迹”,成功将语音输入的推理表现 100% 恢复甚至超越 了纯文本基座水平。

论文题目: Closing the Modality Reasoning Gap for Speech Large Language Models
论文链接: https://arxiv.org/abs/2601.05543
核心痛点:为什么模型 “听” 得越多,“想” 得越偏?
目前的语音大模型(Speech LLM)通常采用 “语音编码器 + 适配器 + LLM” 的三段式架构。理论上,这应该能让语音输入无缝借用 LLM 强大的推理大脑。但现实是:引入语音模态后,推理能力出现了断崖式下跌。
此前的研究主要试图从两个方向修补这一鸿沟,但都存在缺陷:
1. 输入端强行对齐(Input Fusion):
试图让语音特征在输入层就长得和文本 Embedding 一样。但语音天然包含语气、停顿等富语言信息,与紧凑的文本本质不同。仅依靠输入对齐这种表面功夫,无法解决深层的表征漂移(Representation Drift)—— 随着 Transformer 层数加深,语音激发的隐藏状态(Hidden States)会逐渐偏离文本的思考轨迹(即相同语义纯文本输入时,文本激发的隐藏状态),导致 “想岔了”。
2. 输出端死记硬背(SFT / 蒸馏):
这是最主流的做法,即通过监督微调(SFT)利用静态的 “语音 - 文本” 数据对进行训练,或者通过知识蒸馏(Distillation)让文本分支作为 “老师” 来指导语音分支这个 “学生”。这些本质上都属于 Off-policy(离线策略),试图强行让语音分支去模仿文本的 Token 输出分布。但这有两个问题:
目标不可达: 语音的噪声和副语言特征决定了其输出分布不可能和纯文本完全一致。
Exposure Bias: 这种静态监督无法容错。推理时只要错一个 Token,模型就会跌入训练未见过的状态,导致后续回复全盘崩溃。
TARS 的核心洞察在于: 既然死记硬背行不通,能不能用强化学习(RL),让模型自己在 “思考过程” 中去动态对齐文本的轨迹,而不是对齐具体的字?
TARS:用强化学习重塑语音推理轨迹
TARS 是一个基于 On-policy RL(具体采用 GRPO) 的对齐框架。它巧妙地利用模型自身的文本分支作为 “动态导师”,通过三个关键创新,把语音分支的 “脑回路” 掰回来。
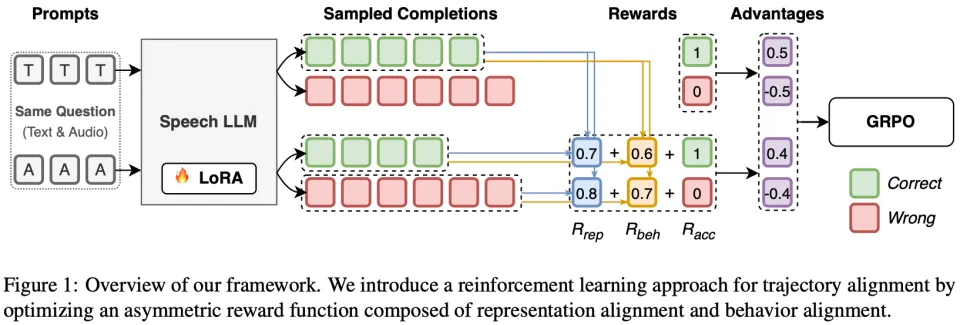
创新一:表征对齐(Representation Alignment)
既然 Gap 和 “表征漂移” 相关,TARS 选择直接从模型内部开刀。
做法: 计算语音作为输入,推理过程中每一层的隐藏状态(Hidden States),与同一模型在文本输入下(文本输入和语音输入在语义上完全相同)的隐藏状态计算余弦相似度,作为表征对齐奖励。

作用: 这就像给语音分支装了一个 “导航仪”。它不再只关注结果,而是引导语音分支的每一层思维路径都时刻紧跟文本分支的轨迹,防止跑偏。
创新二:行为对齐(Behavior Alignment)
为了避免 SFT 的死板,TARS 在输出端引入了更灵活的对齐标准。
做法: 不再要求 Token 级的一一对应,而是利用外部 Embedding 模型(
, e.g., Qwen3-Embedding-0.6B)判断语音推理与文本参考的语义一致性。
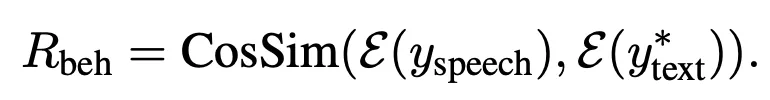
作用: 解决了 “目标不可达” 的问题。允许语音和文本在措辞上有差异,只要逻辑对、意思对就能拿分。这让模型在探索中学会了自我修正,而非机械模仿。
创新三:非对称奖励与模态归一化
在 RL 训练设计上,TARS 针对模态差异做了对应优化:
1. 非对称奖励(Asymmetric Reward): 文本分支只拿基础奖励(保住基本盘),语音分支额外拿对齐奖励(拼命追赶文本)。

2. 模态特定归一化(Modality-Specific Normalization): 这一点至关重要。由于语音推理更难,往往得分较低,如果混合归一化,语音分支会一直收到负梯度。TARS 将两者分开归一化,让语音分支 “自己跟自己比”,保证了持续的优化梯度 —— 即使在所有样本任务准确率都为 0 的极端困难情况下,对齐奖励依然能指导模型进步。
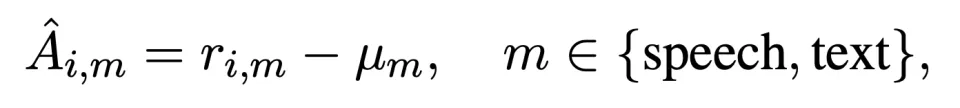
实验结果:推理能力 100% 复原
团队在 UnifiedQA 数据集上训练,并在 MMSU 和 OBQA 两个高难度语音推理榜单上进行了验证。实验基于 Qwen2.5-Omni 和 Phi-4-MM 架构。
核心战绩:MRR 突破 100%


模态恢复率(MRR): TARS 在 7B 模型上达到了 100.45%(Table 1 最后一行)。这意味着,语音输入的推理能力不仅完全填补了引入音频带来的坑,甚至略微超过了文本基座的表现。
碾压基线: 相比 SALAD、AlignChat、KD 等 SOTA 方法,TARS 在 Phi-4-MM 上的准确率达到了 79.80%(Table 1 最后一行),稳居 7B 规模模型第一,且显著优于 SFT 和 DPO 基线(Table 2)。
TARS 不是在拆东墙补西墙!
实验发现,TARS 的对齐并不是 “拆东墙补西墙”。在使用 TARS 训练后,模型的文本准确率也同步提升(Qwen: +2.39%, Phi: +5.43%)。这证明语音模态学习到的知识,能够同时增强文本的推理能力。
总结与展望
TARS 的提出标志着语音大模型研究的一个转折点:
1. 范式转变: 证明了 On-policy RL 在解决模态对齐问题上优于传统的 Off-policy(SFT / 蒸馏)方法。
2. 轨迹对齐: 提出的 “表征(过程)+ 行为(结果)” 对齐策略,有效消除模态推理鸿沟。
TARS 证明了语音大模型完全可以拥有和纯文本模型同等的 “智商”。对于致力于打造全能型 Omni 模型的研究者而言,TARS 提供了一条通往高智商语音交互的可行路径。
