VerseCrafter:给视频世界模型装上4D方向盘,精准运镜控物
视频世界模型领域又迎来了新的突破!
复旦大学与腾讯 PCG ARC Lab 等机构的研究者们提出了 VerseCrafter,这是一个通过显式 4D 几何控制(4D Geometric Control)实现的动态逼真视频世界模型。它不仅能像「导演」一样精准控制运镜,还能同时指挥场景中多个物体的 3D 运动轨迹,为视频生成引入了物理世界维度。
自 Sora 问世以来,视频世界模型(Video World Models)成为了 AI 领域最热门的研究方向之一。我们希望 AI 不仅能生成视频,更能理解和模拟真实的物理世界。然而,现有的视频模型往往面临一个核心困境:视频是在 2D 平面上播放的,但真实世界是 4D(3D 空间 + 时间)的。
现有的方法(如 Voyager、Yume 等)虽然引入了 3D 几何结构来辅助生成,但往往难以在一个统一的框架下同时实现精准的相机控制和多物体运动控制。要么是控制了镜头但物体不动(静态场景),要么是控制了物体但镜头受限,或者依赖于刚性的 3D 边界框和人的参数化模型(如 SMPL),难以应对复杂的真实世界物体。
为了打破这一僵局,来自复旦大学、上海创智学院、香港大学和腾讯 PCG ARC Lab 的研究团队提出了 VerseCrafter。

论文地址: https://arxiv.org/pdf/2601.05138
项目主页: https://sixiaozheng.github.io/VerseCrafter_page/
代码仓库: https://github.com/TencentARC/VerseCrafter

VerseCrafter 的核心理念在于:用一个统一的 4D 几何世界状态(4D Geometric World State)以此驱动视频生成。 它利用静态背景点云和每个物体的 3D 高斯轨迹,实现了对相机和物体运动的解耦与协同控制。
如何构建 4D 可控的世界模型?
VerseCrafter 的魔法源于其独特的 4D 几何控制(4D Geometric Control) 表示和轻量级的 GeoAdapter 架构。
1. 统一的 4D 几何控制表示
传统的控制信号通常是 2D 的(如光流、轨迹点、掩码),缺乏 3D 空间的一致性。VerseCrafter 创新性地提出了一种基于 3D 高斯(3D Gaussians) 的表示方法:
背景: 使用静态背景点云(Background Point Cloud)来表示环境几何。
物体: 使用每物体 3D 高斯轨迹(Per-object 3D Gaussian Trajectories)来编码物体运动。
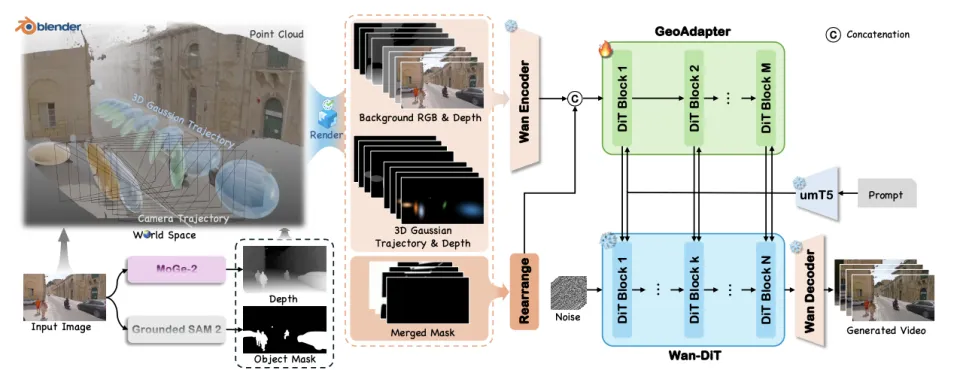
VerseCrafter 的框架图。通过将 4D 几何控制渲染为多通道图,并通过 GeoAdapter 注入到冻结的 Wan2.1 主干网络中。
相比于刚性的 3D 边界框,3D 高斯轨迹提供了一种软性、灵活且类别无关的表示方式。它的均值定义了运动路径,协方差则捕捉了物体随时间变化的形状和方向。这意味着无论是汽车、行人还是动物,VerseCrafter 都能以概率分布的形式描述其在 3D 空间中的占据情况。
2. 冻结的 Wan2.1 主干 + GeoAdapter
为了保证视频生成的画质和真实感,VerseCrafter 并没有从头训练一个大模型,而是巧妙地利用了强大的开源视频生成模型 Wan2.1-T2V-14B 作为冻结的视频先验(Frozen Video Prior)。
研究团队设计了一个轻量级的 GeoAdapter:
首先将 4D 几何控制信息(背景 RGB / 深度、物体高斯轨迹 RGB / 深度、控制掩码)渲染为 2D 序列图;
利用 GeoAdapter 对这些几何信息进行编码;
将其作为残差注入到 Wan2.1 的特定 DiT 模块中。
这种设计既保留了 Wan2.1 强大的生成能力,又以极小的代价引入了精确的 4D 控制。
数据集:VerseControl4D
训练这样一个 4D 世界模型,最大的瓶颈在于数据 —— 我们去哪里找大量带有精确 4D 标注(相机参数 + 多物体 3D 轨迹)的真实世界视频?
为了解决这个问题,团队构建了 VerseControl4D 数据集。
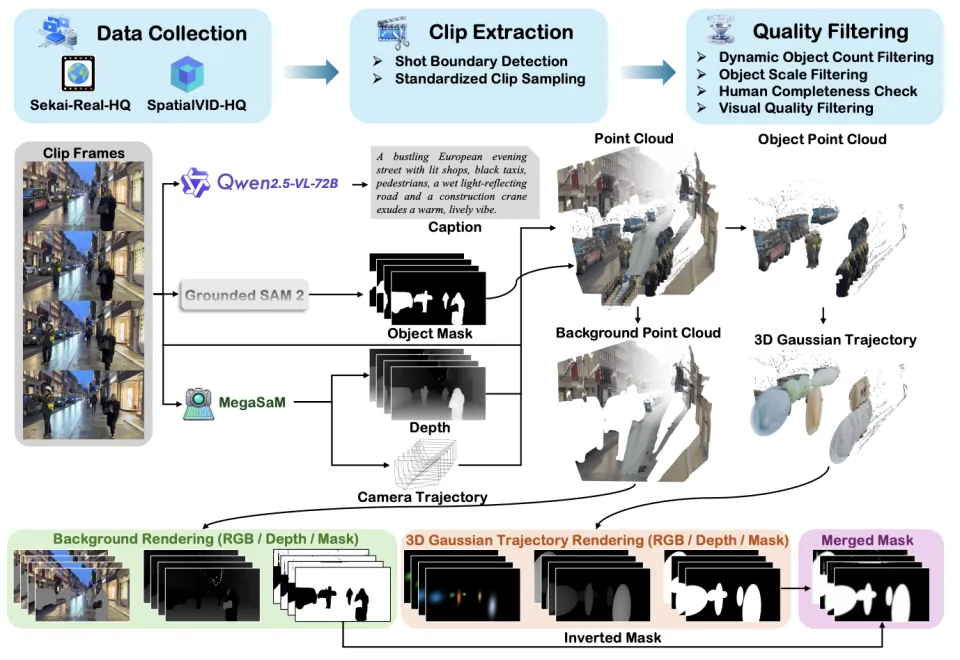
VerseControl4D 数据集的自动化构建流程
数据源: 基于 Sekai-Real-HQ 和 SpatialVID-HQ 等高质量视频数据集;
自动化标注引擎: 结合了 Qwen2.5-VL-72B(生成描述)、Grounded-SAM2(物体分割)、MegaSaM(深度和相机位姿估计)等最先进的工具,自动从视频中提取 4D 几何信息;
规模: 包含 35,000 个训练视频片段,涵盖了丰富的动态和静态场景。
这一数据集的构建,填补了真实世界 4D 几何控制数据的空白,为模型的训练提供了坚实的基础。
实验结果:SOTA 级的控制力
实验表明,VerseCrafter 在各项指标上均超越了现有的 SOTA 方法(如 Perception-as-Control、 Yume、 Uni3C 等)。
1. 动态场景联合控制对比
在同时控制相机运镜和物体运动的复杂场景下,VerseCrafter 展现出了惊人的稳定性。

动态场景对比。第一行从左至右:相机轨迹、GT、Perception-as-Control、Yume,第二行从左到右:Uni3C(第 1,2 列)、VerseCrafter(第 3,4 列)。可以看到 VerseCrafter(右下)的物体运动和背景稳定性最好。
从对比视频中可以看出:
Perception-as-Control 生成的帧质量较低,运镜不准。
Yume 虽然能大致遵循文本描述的运动,但缺乏精确的相机控制。
Uni3C 仅限于单人体运动控制。
VerseCrafter 能够精确地让物体沿着预设的 3D 高斯轨迹移动,同时完美执行相机运镜,且背景保持几何一致。
2. 静态场景运镜对比
即使在没有移动物体的静态场景中,作为单纯的「场景漫游」工具,VerseCrafter 的表现也优于专门的 ViewCrafter 和 Voyager 等模型。

静态场景运镜对比。第一行从左至右:相机轨迹、GT、ViewCrafter,第二行从左到右:Voyager、FlashWorld、VerseCrafter。VerseCrafter 在大幅度运镜下依然保持了建筑结构的笔直和纹理的清晰。
3. 多视角一致性(Multi-Player View)
得益于统一的 4D 世界坐标系,VerseCrafter 还支持多玩家视角(Multi-Player View)生成。对于同一个动态事件,可以从完全不同的两个视角分别生成视频,两者在时间、空间和物体动作上保持高度一致。

两者在同一时间轴上展现了完全一致的世界动态。
总结
VerseCrafter 的出现,标志着视频生成向可控 4D 世界模拟迈出了重要一步。通过将显式的 3D 几何先验(点云与高斯)与强大的 2D 视频生成模型(Wan2.1)相结合,它不仅解决了复杂场景下的控制难题,也为游戏制作、电影预演和具身智能模拟提供了新的可能性。
目前,项目代码与模型权重均已开源,感兴趣的读者可以前往项目主页体验。