全新视角看世界模型:从视频生成迈向通用世界模拟器
近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
与此同时,这一研究方向正快速与具身智能(Embodied AI)、自动驾驶(Autonomous Driving)等前沿场景深度交织,被视为通往通用人工智能(AGI)的重要路径。
然而,在研究热潮之下,「何为真正的世界模型」以及「如何评判视频模型的世界模拟能力」等核心议题却陷入了多维争论。当前,世界模型的定义与分类层出不穷,理论维度的交叉重叠往往令研究者感到困惑,也限制了技术的标准化发展。
为建立更系统、清晰的审视视角,快手可灵团队与香港科技大学(广州)陈颖聪教授团队(共同一作:博士生王罗州、博士生陈知非)联合发表了从全新视角深度剖析视频世界模型的系统综述。
本文旨在弥合当代「无状态」视频架构与经典「以状态为中心」的世界模型理论之间的鸿沟,首次提出以「状态构建(State Construction)」与「动态建模(Dynamics Modeling)」为双支柱的全新分类体系。
此外,本文力倡将评估标准从单纯的「视觉保真度」转向「功能性基准」,并前瞻性地指出了两个关键技术前沿,为视频生成演进至鲁棒的通用世界模拟器提供了清晰的路线图。

论文标题:A Mechanistic View on Video Generation as World Models: State and Dynamics
论文链接:https://arxiv.org/pdf/2601.17067
github 链接:https://github.com/hit-perfect/Awesome-Video-World-Models
综述结构概要
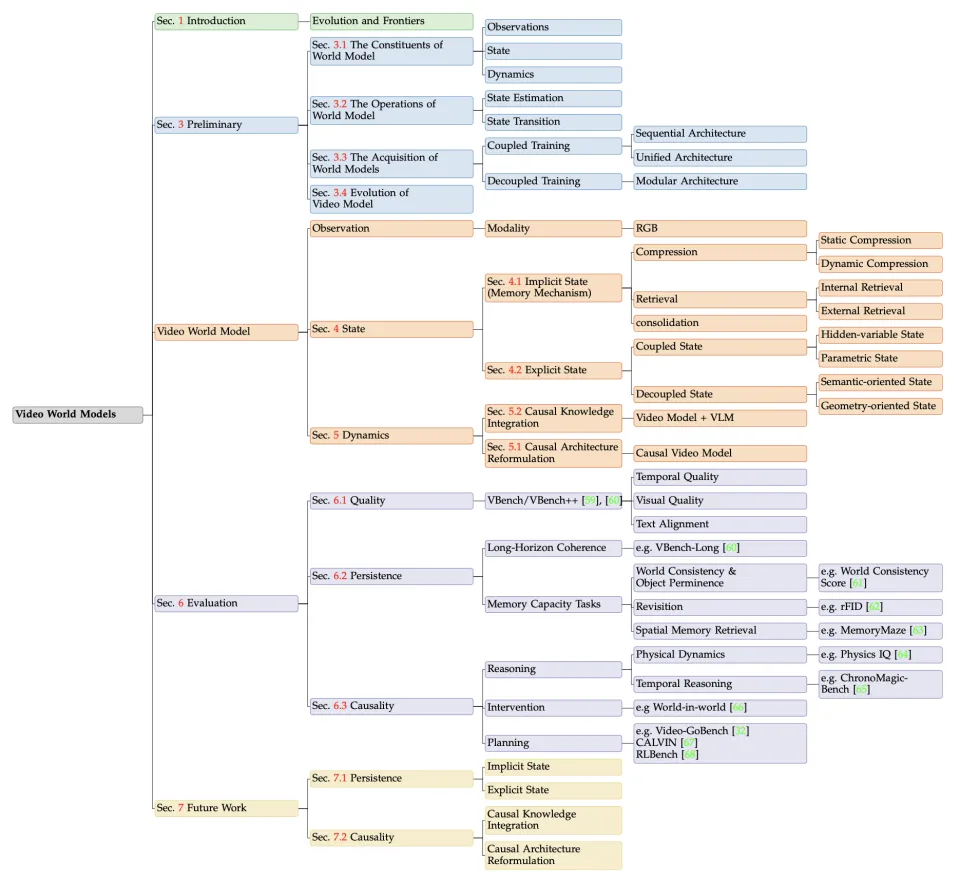
核心亮点:这篇综述的关键贡献是什么?
相比于过往侧重于视觉效果的视频生成研究,本篇综述在多个维度具有代际优势:
全链路视角(Full-Stack Perspective):彻底打破单一的「渲染」视角,涵盖了从底层理论定义、中层架构设计(状态构建与动态建模)到上层功能性评估的全生命周期分析,确保对视频世界模型全方位的理解。
弥合理论鸿沟(Bridging the Gap):首次将当代「无状态」(state-less)的视频扩散架构与经典的基于模型强化学习(MBRL)、控制理论进行深度映射,为世界模型找到了坚实的理论根基。
前瞻性指南(Forward-Looking Guide):明确了「持久性」与「因果性」 是迈向通用世界模拟器的两大核心关隘。本研究为业界从被动的「像素预测」转向具备闭环交互与因果干预能力的模拟器提供了清晰的路径参考。
最新研究覆盖:深度梳理了 2024 至 2025 年间涌现的视频生成的最新工作,反映了当前技术从视觉保真度向物理一致性转化的前沿趋势。
核心理论
世界模型的三大基石
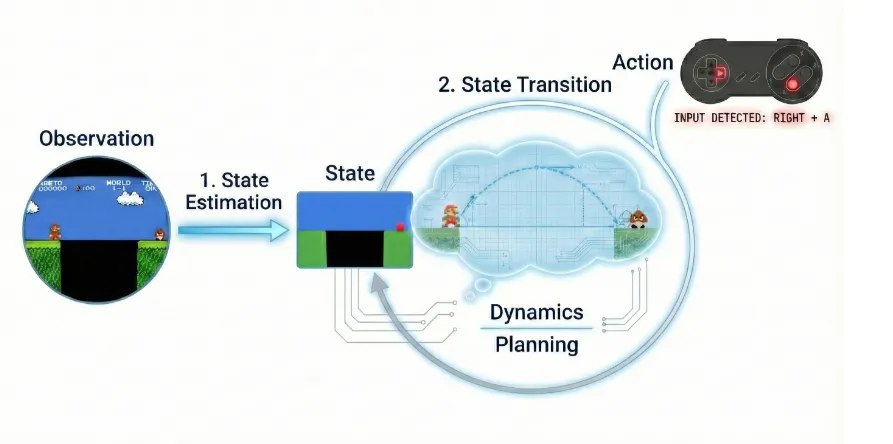
本文首先回归经典,将世界模型的运作提炼为三个耦合的核心组件,构建了从感知到推理的完整链路:
观察(Observation):环境的原始感官数据。在视频模型中,这表现为高维的像素级输入,提供世界的局部、间接视图。
状态(State):对环境的深度理解。模型通过提炼历史观察,过滤噪声,形成足以解释当前世界的「内部表示」。
动态变化(Dynamics):预判未来的「引擎」。它刻画了状态随时间演变的规律
,让模型具备在脑海中「预演」物理法则的能力。
世界模型的核心操作
基于前文提出的「三大基石」,本文将世界模型的运行机制归纳为两项核心操作:
状态估计(State Estimation):把高维、连续的观测序列压缩成一个紧凑的状态表示(
),用来刻画环境在当前时刻的关键状态。
状态转移(State Transition):刻画环境在动作作用下的因果演化,是世界模型的「内部模拟引擎」,用于预测未来状态或观测(
![]() )。
)。
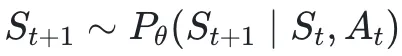
世界模型的学习方式
鉴于世界模型主要服务于下游决策,本文将其获取(训练)范式按与策略模型(Policy Model)的耦合程度归纳为两类:
闭环学习(Closed-loop Learning / Coupled Training):世界模型与策略模型联合训练,世界模型的参数更新直接受策略目标影响(共享梯度 / 端到端优化),该范式可进一步分为两种结构:
顺序组合(Sequential Architecture):世界模型和策略模型是分开的模块,但训练时会端到端联动:策略目标产生的误差信号会通过梯度反向传回世界模型,从而让生成结果更符合可执行性与物理一致性。
统一架构(Unified Architecture):将世界模型与策略整合为单一端到端系统,在同一框架内共同优化感知、预测与动作生成。
开环学习(Open-loop Learning / Decoupled Training):将世界模型视为通过大规模被动数据预训练得到的独立模拟器;策略模型可在自身优化中调用世界模型进行「想象 / 规划」,但世界模型不接收来自策略奖励信号或损失函数的梯度更新(模型冻结)。

视频模型的演进:迈向鲁棒世界模拟器
现代视频生成模型虽已具备很强的视觉保真度并被视为潜在的世界模型载体,但与上面分析的经典世界模型相比仍存在两大关键差距:
在状态(State)层面,多数模型缺乏显式压缩状态而以观测序列充当隐式状态,随时间增长带来计算 / 记忆负担并削弱长程持久性,因此研究要么引入记忆机制进行选择性存储 / 检索 / 压缩,要么显式构建固定大小或层级化潜在状态以解耦序列长度;
在动态(Dynamics)层面,标准模型常以双向注意力「一次性渲染」固定时长片段,缺少显式时间因果推进,近期工作则通过因果架构重构(自回归、因果掩码、滚动预测等)或因果知识集成(借助 LMM 做规划约束或统一耦合优化)来注入因果性(causality)。
核心支柱
为了刻画视频生成模型迈向稳健世界模型的演进路径,本文首先从其内部表示入手,重点审视状态(state)的构建:将「状态」视为对环境当前配置的充分统计量,并以此为核心把历史信息有机融入统一表示中。通过将长期背景提炼并沉淀到这种状态表示里,模型才能在更长时程下维持一致的记忆与连贯的模拟。
随后,本文进一步分析视频生成模型中动态(dynamics)行为的来源,强调模型需要内化潜在的因果规律,使得随时间推进的演化既符合物理可行性,也在逻辑层面保持自洽与一致。
支柱一:状态构建(State Construction)
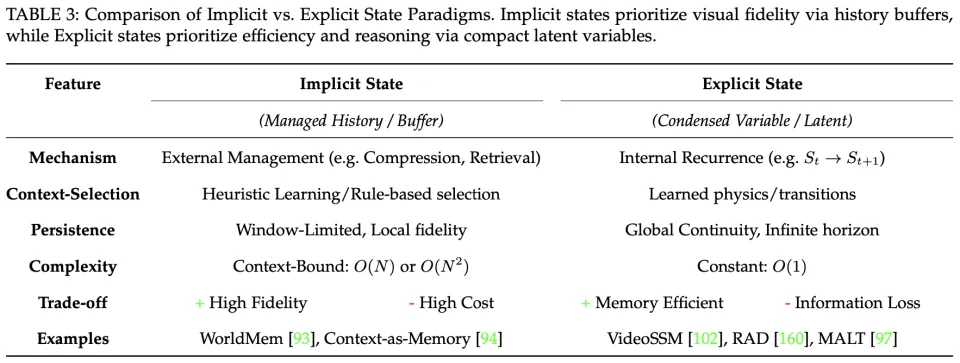
视频模型如何「记住」过去?如何处理历史信息?本文将现有的状态处理机制划分为隐式(Implicit State)与显式(Explicit State)两大范式,并对其优劣进行了深度解构:
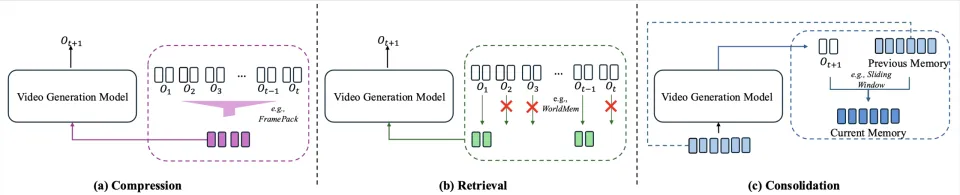
隐式状态(记忆机制管理)
此范式不构建固定大小的显式状态变量,而是通过「管理历史观测」来模拟状态:在时刻,状态
并不等同于原始观测序列
,而是由外部记忆机制
从历史中动态提炼出的「工作记忆」,用于支撑下一步生成所需的长期一致性与上下文连贯。
压缩(Compression): 压缩的核心是利用视频序列的高时空冗余,将历史观测
转化为更紧凑的表示(如 token 合并、摘要向量 /summary slots 等),从而显著降低长上下文注意力带来的计算与存储开销,同时尽可能保留高信息密度的关键内容。典型方法如 FramePack [1] 等,通过合并冗余特征来减少计算负担,并提升长时程生成的可扩展性。
检索(Retrieval):检索的核心是「按需访问」:历史信息并非对下一帧生成同等重要,模型需要根据当前生成意图(如提示词、当前帧局部需求或任务目标)选择性地从已压缩的历史缓存或外部记忆库中召回相关片段,常见实现包括稀疏注意力、Key-Value 查找或相似度召回等。代表性工作如 WorldMem [2] 、Corgi [3] 等,强调主动提取与当前生成最相关的记忆,以避免对全量历史的低效扫描。
巩固(Consolidation): 巩固关注「生成后的记忆更新」:当新内容
被生成后,记忆状态必须演化,决定哪些新信息写入长期存储、哪些旧信息被淘汰或降权,从而在有限容量下维持长期稳定并支持无限流式生成。此类机制通常对应对缓冲区的蒸馏 / 整合与动态替换策略;例如 StreamingT2V [4] 等通过实时蒸馏与更新缓冲区,使模型能够持续生成而不过度膨胀上下文。
显式状态(内核表示)
这一范式将状态构建内化为模型自身的压缩过程:它不再维护不断增长的历史帧缓冲区,而是把历史上下文持续蒸馏进一个全局更新的潜在变量(State)中,使其成为对视频演化过程的固定维度、可递推的数学摘要。
耦合状态(Coupled States):状态转移与生成骨干深度融合,模型在同一网络内实现「边生成、边更新」。状态通常体现为网络内部的隐藏记忆(如 SSM/RNN/LSTM 隐状态或注意力缓冲区),也可通过在线优化 / 可塑性把历史信息编码进参数,使状态融入生成器的内部动力学,代表工作如 TTT [5] 、SANA-Video [6] 等。
解耦状态(Decoupled States):状态与生成器内部激活分离,作为独立显式表征被单独维护与更新,生成器每步读取该状态进行渲染。常见路径包括:语义导向(用 LLM 等维护世界描述 / 叙事逻辑)与几何导向(用点云或 3D Gaussian splatting 等 3D 记忆,通过融合 / 反投影迭代更新以保持空间一致性)。
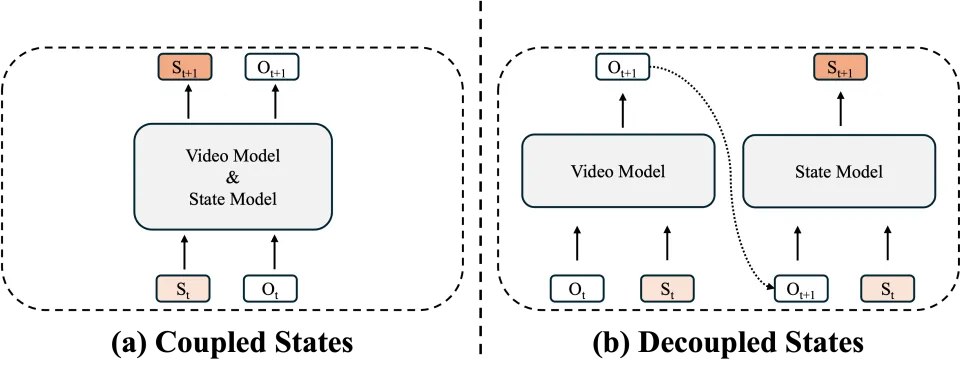
隐式状态 vs. 显式状态的系统性对比
首先,隐式状态本质上是「被管理的历史」:通过外部机制维护一段原始观测的上下文缓冲区,保留真实 token 因而更容易获得高视觉保真,但持久性受限于上下文窗口,一旦超出窗口就更容易遗忘。显式状态则依赖「内部递归」:把历史不断压缩进一个紧凑的潜在状态
,理论上可支撑无限时长的全局连续性,但强压缩也可能带来信息衰减,细粒度细节随时间丢失。
同时,隐式状态更多是启发式驱动:用人为规则(相似度、时间邻近等)决定哪些历史重要;显式状态更偏动力学驱动:要求模型学习状态转移
,更接近 「内化世界规律」的世界模拟器定义。
最后,隐式状态是上下文绑定的,推理成本随历史长度线性或二次增长
到
;显式状态更接近常数开销(
),可在长时程保持固定计算足迹。
总体取舍是:隐式状态目前更稳妥地支持高保真视频生成,而显式状态更像通往高效、可长期推理的自主智能体与世界模拟的前沿方向。
支柱二:动态建模(Dynamics Modeling)
如何让生成的视频不只是「看起来像」,而是真正符合物理规律与时间逻辑?本文归纳了两条增强因果推理能力的主要路径:
因果架构重构(Causal Architecture Reformulation):从模型结构与训练目标入手,把生成过程从「一次性渲染」改造成「按时间顺序预测」,通过因果遮罩等机制避免未来信息泄漏,并结合不同的训练 / 噪声调度策略强化严格的时间依赖;同时通过 forcing 等方式模拟推理阶段的误差累积与曝光偏差,缩小训练与推理的差距,使长时程 rollout 更稳定、更符合物理一致性与逻辑连贯性,代表工作如 Self-Forcing [7] 等。
因果知识集成(Causal Knowledge Integration):引入具备更强推理与常识能力的多模态大模型(LMM/VLM/LLM)作为「规划者 / 导演」,先在高层完成时序、动作与场景逻辑的规划,再由视频生成模型负责高保真「渲染」;更进一步的统一框架会将理解与生成更紧密地耦合,让推理信号直接约束生成过程,从而提升动态演化的因果可信度,代表工作如 Owl-1 [8] 等。
支柱三:评估体系(Evaluation)
如果说视频生成更关心「好不好看」,那么世界模拟还需要更关心「好不好用」。传统的 IS/FVD 等指标主要衡量短片段的视觉真实感,已难以回答模型是否具备可持续推演、可交互、可用于决策的「世界模型」能力。因此,本文主张将评估从 「视觉美感」进一步推进到「功能基准」,并提出三条核心评价轴:
质量(Quality):关注基础视觉保真度、短程时序相干性以及文本 / 条件对齐能力,代表性工具如 VBench [9] / VBench++ [10] 等,用更细粒度的维度拆解「画面是否稳定、主体是否一致、语义是否对齐」。
持久性(Persistence):关注长时程 rollout 的稳定性与一致性,既看生成长度拉长后是否出现漂移 / 崩坏,也通过「场景重访(re-visitation)」等记忆任务检验模型能否在回到旧地点时恢复正确状态,而不是凭空补细节;相关评测包括 WCS [11] 以及基于 rFID [12] 的重建一致性测试等。
因果性(Causality):作为世界模拟的核心能力,重点检验模型是否真正内化物理与逻辑规律,既包括时间顺序与物理有效性(如 ChronoMagic-Bench [13] 、Physics-IQ [14] ),也包括反事实干预下的响应是否合理(例如改变动作 / 初始条件后,世界是否按因果产生不同且自洽的结果),并进一步延伸到 agent-in-the-loop 的任务成功率与规划表现(如 World-in-World [15] 等)。
未来研究方向
视频生成迈向世界模拟的关键,在于补齐两项核心能力:持久性(persistence)与因果性(causality)。
前者要求模型在长时程生成中保持稳定一致的状态:隐式状态需要从固定窗口等启发式记忆升级为可学习、可动态筛选的信息管理机制;显式状态则要在压缩效率与细节保真之间找到更好的平衡。
后者要求模型从统计相关走向因果机制:一条路线是通过架构与数据设计提升因果推断能力(更好地解耦潜在因果因素),另一条路线是引入理解模型的推理先验来约束生成,但如何有效对齐生成与理解仍是核心挑战。
结语
综上所述,随着视频生成技术在各领域的爆发式增长,如何使其具备真实世界的模拟能力已成为不可回避的挑战。通过全链路的技术剖析,本综述不仅弥合了视频架构与经典理论之间的裂痕,还揭示了从「隐 / 显式状态构建」到「因果动态建模」的关键路径。
这篇综述为学术界和工业界提供了一个重要的参考框架,帮助研究者在通往通用世界模拟器的征途中精准定位。
团队相信,通过应对综述中列出的挑战,该领域可以从生成视觉上逼真的视频发展到构建稳健的通用世界模拟器,为自动驾驶、具身智能等领域的长足发展奠定坚实基石。
参考文献
[1] L. Zhang and M. Agrawala. Packing input frame context in next-frame prediction models for video generation. arXiv preprint arXiv:2504.12626, 2025.
[2] Z. Xiao et al. Worldmem: Long-term consistent world simulation with memory. arXiv preprint arXiv:2504.12369, 2025.
[3] X. Wu et al. Corgi: Cached memory guided video generation. arXiv preprint arXiv:2508.16078, 2025.
[4] R. Henschel et al. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 2568–2577, 2025.
[5] K. Dalal et al. One-minute video generation with test-time training. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 17702–17711, 2025.
[6] J. Chen et al. Sana-video: Efficient video generation with block linear diffusion transformer. arXiv preprint arXiv:2509.24695, 2025.
[7] X. Huang et al. Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009, 2025.
[8] Y. Huang et al. Owl-1: Omni world model for consistent long video generation. arXiv preprint arXiv:2412.09600, 2024.
[9] Z. Huang et al. Vbench: Comprehensive benchmark suite for video generative models, 2023.
[10] Z. Huang et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models, 2024.
[11] A. Rakheja et al. World consistency score: A unified metric for video generation quality, 2025.
[12] M. Heusel et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018.
[13] S. Yuan et al. Chronomagic-bench: A benchmark for metamor-phic evaluation of text-to-time-lapse video generation, 2024.
[14] S. Motamed et al. Do generative video models understand physical principles?, 2025.
[15] J. Zhang et al. World-in-world: World models in a closed-loop world, 2025.