破解机器人「慢半拍」难题:南洋理工解决VLA致命短板
当物体在滚动、滑动、被撞飞,机器人还在执行几百毫秒前的动作预测。
对动态世界而言,这种延迟,往往意味着失败。
在过去几年中,Vision-Language-Action(VLA)模型迅速成为机器人领域的焦点:机器人可以 “看懂” 画面、“理解” 语言指令,并直接输出连续动作,在静态抓取、摆放、桌面操作等任务中取得了显著进展。
但一个长期被忽视的问题是 ——真实世界几乎从来不是静态的。当物体开始移动、加速、碰撞、改变轨迹,当前主流 VLA 模型往往会出现反应迟缓、动作失配、甚至完全失败的情况。
问题不在于模型不聪明,而在于:它们跟不上时间。
近日,来自 NTU S-Lab 的研究团队提出 DynamicVLA,首次系统性地从模型架构、推理机制和数据体系三个层面,重新审视并解决动态物体操控(Dynamic Object Manipulation)这一长期空缺的问题。

想深入了解 DynamicVLA 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

论文链接:https://arxiv.org/abs/2601.22153
项目链接:https://haozhexie.com/project/dynamic-vla/
GitHub 链接:https://github.com/hzxie/DynamicVLA
为什么 “动态操控” 对 VLA 来说如此困难?
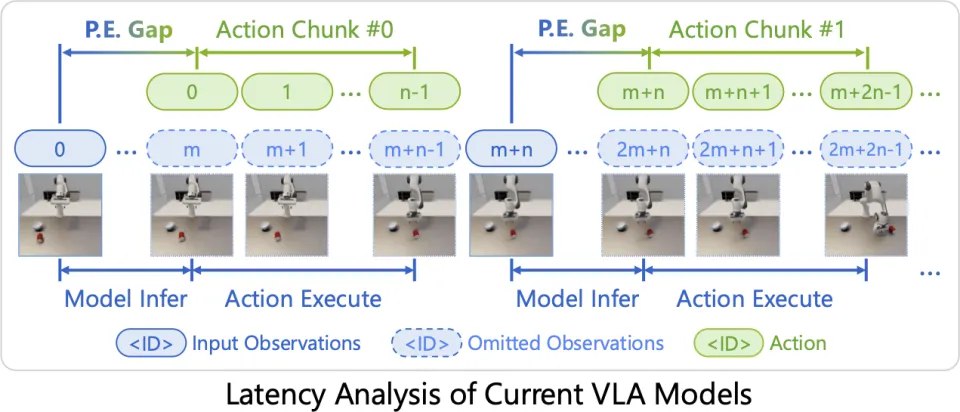
在静态场景中,VLA 模型通常遵循如下流程:
感知 → 推理 → 生成一段动作 → 执行完 → 再次推理
当环境基本不发生变化时,这种方式可以正常工作;但一旦物体开始运动,这一流程便迅速失效。
问题并不在于模型能力不足,而在于时间结构本身不适用于动态世界,主要体现在两个方面:
感知 — 执行时间错位(Perception–Execution Gap):由于推理存在不可避免的延迟,当模型完成决策时,物体状态早已发生变化,动作天然 “滞后于现实”。
动作分块等待(Inter-chunk Waiting):多数 VLA 必须等上一段动作完全执行后才能启动下一次推理,使机器人在动态环境中始终处于被动追赶状态。
这两个问题叠加,使得即便在静态任务中表现良好的 VLA,也难以应对真实世界中的动态操控。
DynamicVLA 的核心思路:让机器人 “边想边做”
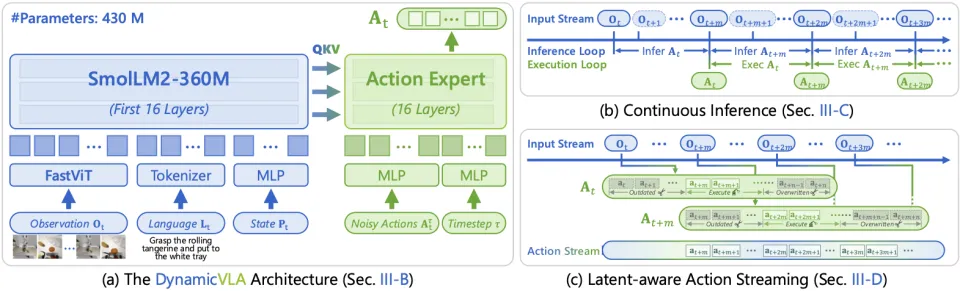
DynamicVLA 并没有选择通过增大模型来 “预测更远的未来”,而是围绕一个更根本的问题重新设计系统:
在推理延迟无法消除的情况下,如何保证机器人执行的动作仍然与当前世界状态时间对齐?
为此,DynamicVLA 从推理机制、执行策略和模型结构三个层面提出了对应设计。
1. Continuous Inference:让推理与执行不再相互等待
在传统 VLA 中,推理与执行严格串行;
而 Continuous Inference(连续推理)允许模型在上一段动作尚未执行完时,就启动下一轮推理,从而解决的是 Inter-chunk Waiting 带来的反应迟滞问题:
推理与执行形成流水线
不再存在 “动作执行完才能继续思考” 的空窗期
机器人始终保持一个持续更新的动作预测流
2. Latent-aware Action Streaming:修复推理延迟造成的时间错位
即使采用连续推理,推理延迟本身仍然存在。这意味着:模型生成动作时所依据的观察,往往已经落后于真实世界。Latent-aware Action Streaming(LAAS)正是针对这一 Perception–Execution Gap 设计的执行机制:
显式丢弃因推理延迟而 “过时” 的动作
只执行在时间上仍与当前环境状态对齐的预测
当新预测到来时,优先采用更新、更接近当前状态的动作
3. 为动态而生的轻量化 VLA 架构
上述机制能否成立,还依赖于足够低的推理延迟。因此 DynamicVLA 采用了专为动态操控设计的轻量化架构:
卷积式视觉编码器,避免多帧输入下 token 爆炸
截断语言模型层数,在速度与理解能力之间取得平衡
整体模型规模控制在 0.4B 参数量级
动态操控数据的核心缺口:从仿真到真实世界
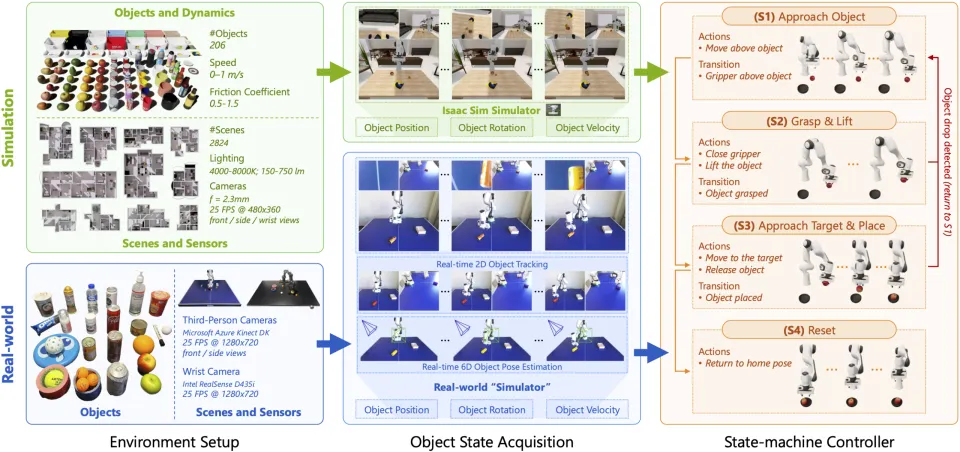
当前,无论是仿真还是真实机器人,主流 VLA 数据集几乎都聚焦于静态操作,而对动态物体交互的系统性覆盖仍然缺失。这一数据结构性偏差,直接限制了 VLA 在真实动态环境中的泛化能力。
在仿真侧,DynamicVLA 基于 Isaac Sim 构建了大规模动态操控数据:覆盖 2800+ 场景、206 种物体,通过多样化的物体运动与交互模式,生成丰富且可控的动态仿真数据,为模型提供了系统性的动态训练基础。
相比之下,真实世界的动态数据采集处于 “几乎不可行” 的状态:动态物体运动速度快,人类遥操作反应时间不足,且难以实时获取高质量的 6D 位姿与速度标注,使得规模化、可复现的真实动态操控数据一直缺位。
DynamicVLA 的做法并不是强行遥操作,而是把真实世界 “做成仿真接口”(Real-world Simulator):
多视角 RGB 感知,实时追踪物体运动
在线估计物体 6D 位姿 + 速度
将真实环境抽象为与仿真一致的状态输入
直接复用同一套状态机与控制逻辑
首个动态操控基准:DOM Benchmark

在上述自动化数据体系之上,团队进一步构建了 Dynamic Object Manipulation(DOM)Benchmark,这是首个专为动态物体操控设计的系统性评测基准。
与以往侧重 “是否完成任务” 的静态评测不同,DOM 从动态操控的本质出发,将能力拆解为 3 个核心维度、9 个子维度:
1. 交互能力(Interaction)评估机器人在物体持续运动下的实时控制与决策能力,包括:
Closed-loop Reactivity:对不同运动速度的即时响应能力
Dynamic Adaptation:在碰撞、变向等突发事件后的快速调整能力
Long-horizon Sequencing:在长时间动态交互中保持策略一致性的能力
2. 感知与理解(Perception)评估模型在动态场景中的多模态理解能力,包括:
Visual Understanding:区分外观相似物体的能力
Spatial Reasoning:理解空间关系与相对位置的能力
Motion Perception:感知与判断物体运动状态(速度、方向)的能力
3. 泛化与鲁棒性(Generalization)评估模型在分布外动态条件下的稳定性,包括:
Visual Generalization:面对未见物体与新场景的适应能力
Motion Generalization:应对新速度范围与运动模式的能力
Disturbance Robustness:在外部扰动下维持稳定控制的能力
DOM Benchmark 显示,DynamicVLA 在动态交互相关能力上显著领先,但在感知理解与扰动鲁棒性上仍存在明显不足。这一限制并非偶然,而是源于为保证实时性而选择的小模型架构。如何在响应速度与推理能力之间取得更优平衡,将是动态操控 VLA 的重要方向。
实验结果:动态世界中的断层领先
在仿真与真实机器人实验中,DynamicVLA 在多个维度上显著领先现有方法。

DynamicVLA 的意义:机器人开始真正 “活在时间里”
DynamicVLA 传递了一个清晰信号:
下一代机器人智能的核心,不只是 “看懂世界”,而是在世界变化的过程中持续做出正确反应。
从 Continuous Inference,到 Latent-aware Action Streaming,再到 Real-world simulator,DynamicVLA 为动态操控提供了一套可复现、可扩展、可落地的系统范式。