复刻、长语音、对话、指令、音效全覆盖!模思智能推出MOSS-TTS Family!
当一段语音不仅需要 “像某个人”、“准确地读出每个字”, 还需要在不同内容中自然切换说话方式, 在几十分钟的叙述中持续稳定, 在对话、角色、实时交互等不同形态下都能直接使用 —— 单一的 TTS 模型,往往已经不够用了。
就在今天,模思智能及 OpenMOSS 团队再度上新,发布并开源了 MOSS-TTS Family,一套面向高保真、高表现力与复杂场景生成的语音生成模型家族。

你可以用 MOSS-TTS Family 完成这些事情:
零样本克隆说话人的音色与表达风格并精准控制语音时长,用于纪录片、影视配音或新闻播报;
生成具备真实节奏的双人或多人对话,用于播客、综艺或解说;
通过指令设计带有情绪与表演状态的角色声音;
为内容补全环境音与音效;
以及在实时 Voice Agent 系统中,以流式方式持续输出自然语音;
从这些真实、明确的实际需求,我们不难看出,模思推出的 TTS 全家桶,并不是单一能力的堆叠,而是一整套可以直接接入创作流程、产品系统与交互场景的声音生产工具链。
语音生成模型家族:全维度能力覆盖
MOSS-TTS Family 并不是对 “一个更大的 TTS 模型” 的追求。
相反,我们选择将声音生产拆解为多个真实存在的创作与应用环节,并为每一个环节提供专门的模型支持,使它们既可以独立使用,也可以组合成完整的工作流。
整个模型家族包含五个核心成员:
MOSS-TTS:高保真、高表现力的语音生成基座,多语言、长音频、精确时长控制;
MOSS-TTSD:全面更新至 1.0 版本,面向真实对话场景的多说话人语音合成,包括但不限于播客等更多复杂对话场景;
MOSS-VoiceGenerator:复杂文本指令跟随、用于音色与角色设计;
MOSS-SoundEffect:环境音与音效生成模型;
MOSS-TTS-Realtime:面向实时交互的实时流式 TTS 模型;
它们共同构成了一个覆盖 “稳定生成、灵活设计、复杂对话、情境补全、实时交互” 的声音创作生态闭环。
MOSS-TTS:高表现力语音生成基座
MOSS-TTS 是整个 MOSS-TTS Family 的基础模型,也是所有声音能力得以成立的前提。
它的核心目标是在真实内容与复杂场景中,稳定地复现一个说话者的声音特征、表达方式与语言习惯,并稳定地生成长语音片段。
在下面的音频示例中,我们将从多个维度展示 MOSS-TTS 的能力边界。
零样本音色复刻:从 “像声音” 到 “像这个人说话”
音色克隆并不等同于音色相似。在真实内容中,人们更容易注意到的,往往是语速、韵律、停顿方式、情绪走向与整体说话风格是否一致。MOSS-TTS 的音色克隆能力,正是围绕这些 “非显性特征” 展开。
在业界权威测试集 Seed-TTS-eval 上,MOSS-TTS 的语音音色相似度超越了当前所有的开源模型和大多数闭源模型。
中文场景展示
央视纪录片解说高原雪豹
百家讲坛论王立群老师论时间观念
英文场景展示
钢铁侠Tony Stark 大型怼人现场
Taylor Swift 深情向粉丝吐露心声
在这些示例中,可以明显听到:同一参考音色在不同内容语境下,说话节奏、重音位置与情绪密度都会发生变化,而并非简单地 “套用一个声线”。
超长语音生成:不再为分段拼接而苦恼
在长内容语音生成中,一个长期存在且高度工程化的问题是:
上下文长度本身是否足够、是否可持续、是否可一次性完成生成。
在许多实际应用中,超出常规上下文长度的语音内容,往往需要通过人工分段生成、再进行拼接与后处理的方式完成。这不仅增加了使用成本,也降低了语音质量的一致性。
MOSS-TTS 面向真实生产需求,支持单次上下文内完成超长语音生成,无需对文本进行人为切分,也无需通过多轮调用来拼接音频结果。
在上述示例中,MOSS-TTS 在一次生成流程中直接能够得到 43 分钟的超长音频,避免了因分段处理带来的接口复杂度与工程负担。
这一能力使 MOSS-TTS 能够更加自然地融入纪录片、有声内容与长篇讲解等场景,将语音生成从 “需要特殊处理的步骤”,转变为可直接调用的基础能力。
语音时长控制:在不牺牲自然度的前提下控制语速
在很多生产场景中,“生成多快” 与 “生成多长” 是明确约束条件,而不仅仅是风格选择。MOSS-TTS 支持在 Token 级别对生成时长进行控制,从而适应更多创作场景。
多语言语音生成:跨语言的一致性表达
MOSS-TTS 支持多种主流语言的语音生成,并致力于在不同语言中保持一致的发音质量与表达自然度。
支持语言包括但不限于:
中文
英语
法语
德语
西班牙语
日语
俄语
韩语
意大利语
任意语言切换
拼音与音素级细粒度发音控制:从准确发音到可控表达
在语音生成中,发音控制不仅仅是为了 “读对”,更重要的是为创作者和开发者提供可操作、可实验、可组合的表达空间。
MOSS-TTS 提供拼音与音素级别的细粒度发音控制能力,使用户能够直接参与到发音层面的设计与调整中,而不仅仅停留在文本层面,在不改变整体语音自然度的前提下,对局部读音进行精细干预。通过这一能力,可以实现包括但不限于以下用法:
使用纯拼音输入驱动语音生成,而不依赖原始汉字文本
例如“你好,我是来自模思智能的模型”,直接输入:
ni2 hao3,wo3 shi4 lai2 zi4 mo2 si1 zhi4 neng2 de4 mo2 xing2
主动修改拼音内容或声调,用于纠正特定读音
例如“一骑红尘妃子笑,无人知是荔枝来”,直接调整“骑”这个多音字发音:
一 ji4 红尘妃子笑,无人知是荔枝来
一 qi2 红尘妃子笑,无人知是荔枝来
通过对拼音与音调的组合调整,探索更具个性化的发音方式
例如“你好,请问你来自哪座城市?”,修改后,得到方言或者特殊口音性质的亲切的“老乡话”:
nin2 hao3,qing4 wen3 nin2 lai2 zi4 na4 zuo3 cheng4 shi3?
MOSS-TTSD-V1.0:面向真实内容的多说话人对话生成
如果说单人 TTS 解决的是 “讲述”,那么 MOSS-TTSD 解决的是 “交流”。
相比于 0.7 版本,1.0 版本的核心能力如下:
以双说话人为核心的自然对话节奏,支持 1–5 人,任意指定人数的语音生成;
支持更多对话场景
播客、说书、体育解说、电竞解说、影视、综艺、动漫、相声等
支持最长 60 分钟的长对话生成
覆盖 中文、英语、日语、韩语、西班牙语、葡萄牙语、法语、德语、意大利语、俄语、阿拉伯语 等多种语言
管泽元王多多解说IG大战T1
詹俊张路解说魔都高校德比
贾玲、刘德华和周杰伦闲聊
MOSS-TTSD-V1.0 无论是在客观指标还是主观评测中均领先于当前主流的闭源及开源模型。
MOSS-VoiceGenerator:用指令 “设计” 声音与角色
在很多创作流程中,创作者并不只是需要 “某个人的声音”,而是需要一个具备性格、情绪与表演状态的角色声音。
而 MOSS-VoiceGenerator 恰恰提供了这样的能力
强烈且自然的情绪表达与转变
接近真实表演状态的音色与气息变化
清晰的角色感
MOSS-VoiceGenerator 可以作为:
角色原型的生成工具
IP 声音设计的起点
与 TTS / TTSD 组合使用的 “声音设计层”
年轻男性,阴阳怪气,拖长音,极尽嘲讽
撕心裂肺,声泪俱下的中年女性
MOSS-SoundEffect:从文字描述直接生成环境音与音效
完整的声音体验不仅来自 “说话的人”,也来自空间、动作与环境。
MOSS-SoundEffect 能够用来在合适的情境补充身临其境的音效,支持生成的音效类型包括:
自然环境音:例如,“踩在新雪上的嘎吱声”。
城市环境音:例如,“一辆跑车在高速公路上呼啸而过”。
动物音:例如,“清晨的公园里,鸟儿在静谧的氛围中鸣叫”。
人类活动音:例如,“清晰的脚步声在水泥地上回荡,节奏稳定”
MOSS-TTS-Realtime:面向实时系统的流式语音生成
在语音助手、实时对话与交互式系统中,延迟与稳定性往往比 “极致音质” 更重要。
特点
流式文本输入,流式语音输出
适合作为 LLM 的语音外挂能力
MOSS-TTS-Streaming 是整个模型家族中,最偏向 “系统能力” 的一环。
Case-by-case 对比:与其他闭源与开源模型的效果对比
在展示 MOSS-TTS Family 自身能力的同时,我们也将模型放入更广泛的行业背景中进行验证。
为此,我们选取了多种具有代表性的闭源与开源语音生成模型,在尽量统一的输入条件下,对模型输出效果进行了 case-by-case 的对比测试,以更客观地观察不同系统在实际任务中的表现差异。
对比维度包括但不限于:
音色相似度与一致性
表达自然度与表现力
场景适配能力

所有对比示例均基于相同或等价的文本与参考条件生成,旨在呈现不同模型在具体使用场景中的实际输出效果,而非单一指标或主观印象。
技术方法
MOSS-TTS Family 的能力,建立在系统性的技术选择与工程实践之上。该模型的核心在于回归语音生成任务中三个最为重要的因素:高质量的 Audio Tokenizer、大规模、高质量且多样化的预训练数据,以及高效的离散 Token 建模方法。这些要素的结合,使我们能够以出人意料的简洁方法实现最先进的性能:一个简单的自回归范式 —— 架构尽可能精简,结果却足够强大。
高性能音频 Tokenizer,夯实高保真生成的底座
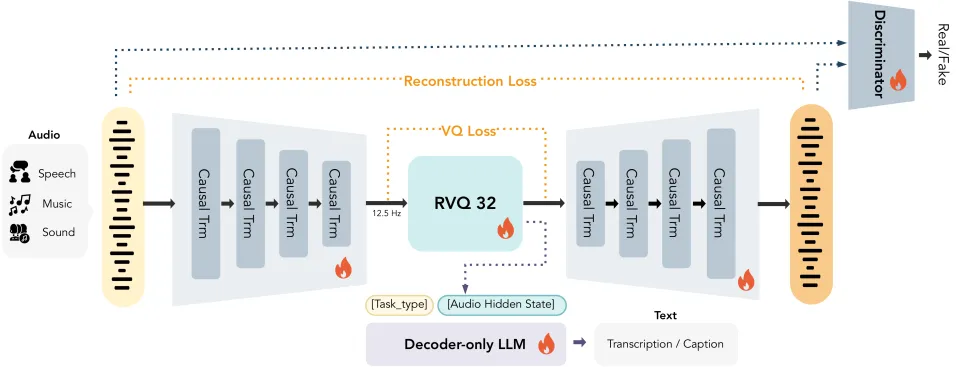
MOSS Audio Tokenizer 是一个基于 Cat (Causal Audio Tokenizer with Transformer) 架构的 1.6B 参数量的音频 tokenizer。该模型旨在为自回归音频大模型提供统一的离散化音频接口,兼具无损重构能力与卓越的音频 - 文本语义对齐性能。
技术特性:
1. 高压缩比与变比特率: 支持将 24kHz 音频压缩至 12.5 fps。基于 32 层 RVQ 机制,模型可在 0.125-4kbps 范围内实现灵活的码率调节,满足不同场景下的高保真重建需求。
2. 纯 Transformer 同构架构: 采用无 CNN 的全因果 Transformer 设计。其 16 亿参数规模确保了强大的模型容量与可扩展性,并且可以支持帧级别的流式编码与解码。
3. 通用音频表征能力: 历经 300 万小时超大规模音频数据的预训练,覆盖语音、音效、音乐等全领域,具备极强的泛化能力。
4. 语义 - 声学统一表征: MOSS Audio Tokenizer 编码得到的离散 Token 在保持 SOTA 级高保真还原音质的前提下,还蕴含了丰富的语义信息,能天然适配自回归生成模型的建模需求。
5. 零预训练依赖: 避开了对现有音频预训练模型(如 Whisper、HuBERT)的依赖或蒸馏,完全通过原始数据自主学习音频特征。
6. 端到端联合训练: 实现所有模块(编码器、量化器、解码器,判别器及用于语义对齐的 LLM )的全闭环联合优化,确保系统整体性能的协同提升。
总结:
MOSS Audio Tokenizer 凭借其极简且易扩展的架构设计与超大规模数据的深度融合,彻底打破了传统音频 tokenizer 的性能瓶颈。它为下一代原生音频基座模型(Native Audio Foundation Models)提供了一个稳定、高保真且深度对齐语义的标准接口。
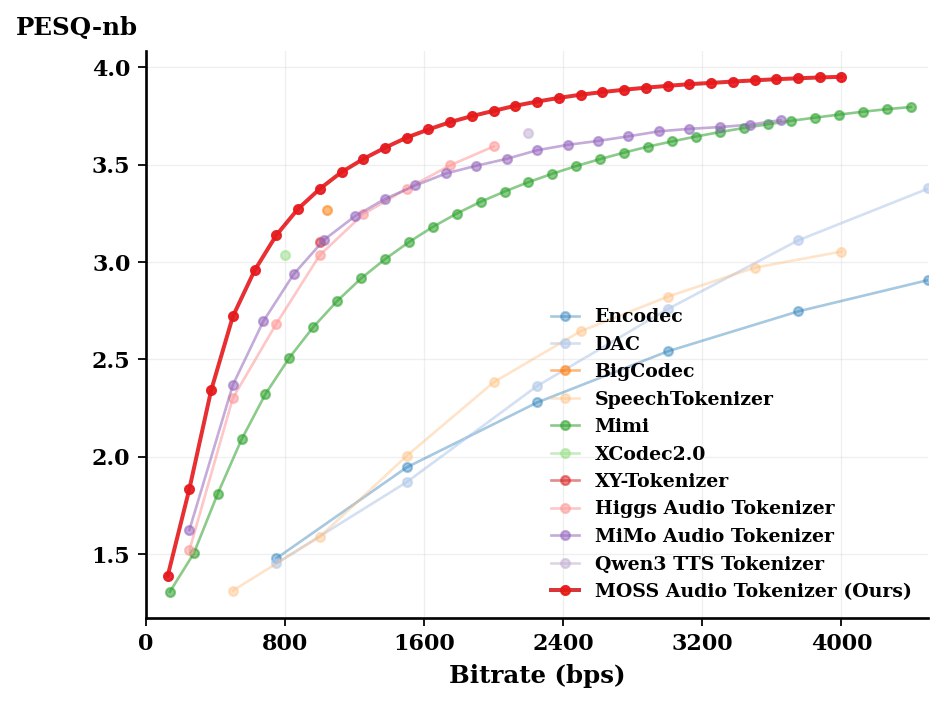
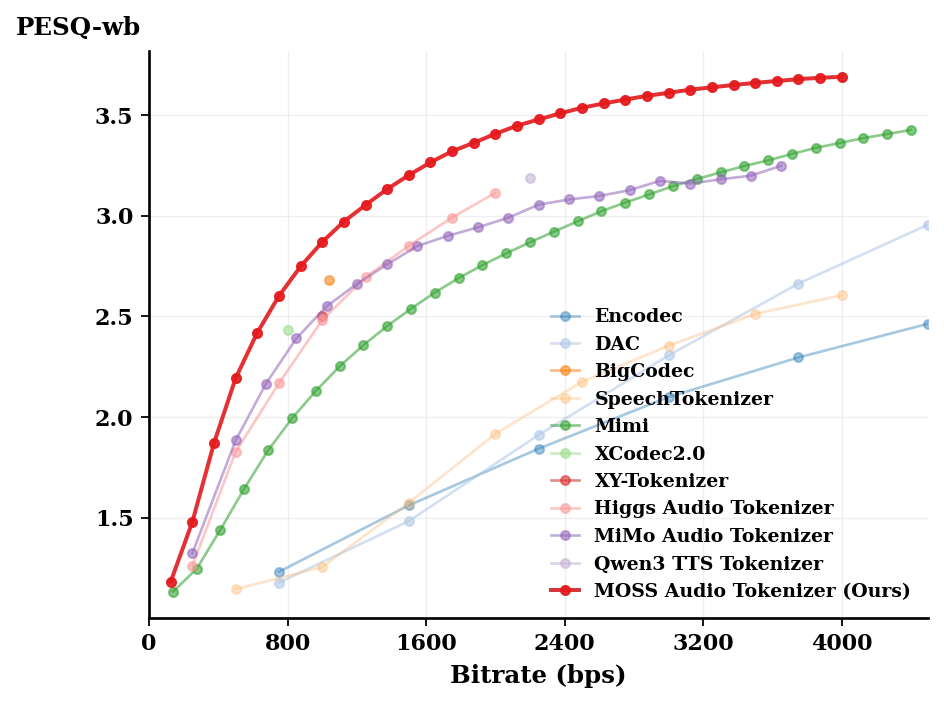
下图是 MOSS Audio Tokenizer 和其他开源 Audio Tokenizer 在 LibriSpeech test clean 数据集上的重建客观指标对比,可以发现在相近 bps 下, MOSS Audio Tokenizer 在 0-4kbps 下的重建质量领先于其他的开源 audio tokenizer


大规模高质量多样化预训练数据,驱动泛化与可控性跃迁
MOSS Data Engine 是支撑 MOSS-TTS Family 的数据生产系统:它不只是 “收集与清洗”,而是将真实世界的海量原始音频转化为可复用的训练资产 —— 既能承载长时叙事的稳定性,也能覆盖对话交互、角色塑造与音效补全等多种生成形态。
在规模维度上,Data Engine 的语音主干语料包括数百万小时的 TTS 数据与数百万小时的 TTSD 数据;同时,系统还持续构建面向音色 / 角色设计与环境音 / 音效生成的专用数据资产,与主干语料在同一标准体系下协同演进。
在方法维度上,我们以 “多阶段治理 + 交叉一致性验证 + 面向模型家族的多轨数据资产” 组织整个流程:从音频质量与一致性、到内容对齐与可训练性,再到按任务形态拆分与组合,最终形成可直接喂给 MOSS-TTS / TTSD / VoiceGenerator / SoundEffect / Realtime 的多轨数据供给,让家族模型既共享同一底座,又各自获得对任务最关键的训练信号。

双架构并行开源,覆盖性能 — 时延全谱系
为兼顾真实业务落地与学术研究可复现性,MOSS-TTS 选择同时训练并开源两套互补架构。我们并非在单一路线上 “押注”,而是以工程可用性为底线、以架构探索为上限,系统性地覆盖语音生成在长文本稳定性、推理效率、流式时延、客观指标等维度上的关键取舍,给社区与产业提供两条同等强势的技术路径与研究基线。
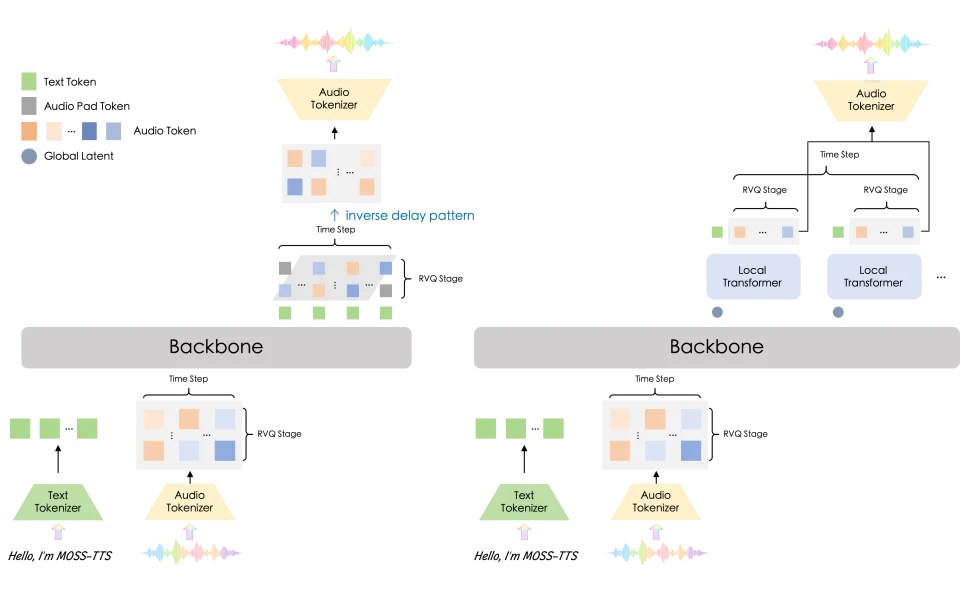
图例:左:Delay-Pattern(MossTTSDelay) 采用单一 Backbone +(n_vq+1)Heads,通过多码本 RVQ 的 delay scheduling 自回归生成音频 token;右:Global Latent + Local Transformer(MossTTSLocal) 由 Backbone 每步输出全局潜变量,再由轻量 Local Transformer 逐步发射 token block,更适合低时延流式合成。
架构 A:Delay-Pattern(MossTTSDelay)—— 更稳、更快、更 “能上生产”
单 Transformer 主干 + (n_vq + 1) Heads:以统一骨干承载语义与声学生成,输出头直接面向多码本(RVQ)token 预测。
Delay Scheduling 多码本延迟调度:通过精心设计的延迟机制,稳定地处理多码本 token 的时序和层级关系。
核心优势:在长上下文场景下保持更强的一致性与鲁棒性,同时具备更高的推理效率与更友好的生产行为 —— 适合长篇叙述、内容生成与规模化部署。
架构 B:Global Latent + Local Transformer(MossTTSLocal)—— 更轻、更灵活、更 “适配流式”
Backbone 产出每步 Global Latent:主干网络在每个时间步凝聚生成所需的全局表征。
轻量 Local Transformer 每步发射 Token Block:用更小的局部自回归模块生成成块的音频 token,提高吞吐并降低端到端时延。
Streaming-Friendly 的简化对齐:无需 delay scheduling,结构更直接、对齐更简洁 —— 天然适配流式输入 / 输出与实时交互。
核心优势:模型更小、更易扩展,在客观基准上表现突出,特别适合作为流式和实时系统的强基线。
为什么要训练两套?
架构潜力的系统性验证:我们同时覆盖两种代表性的生成范式,不止追求单点 SOTA,而是追求 “能跑通、能复现、能迭代” 的体系化能力。
明确且互补的 tradeoff:Delay-pattern 往往在长文合成更快更稳;Local 架构更轻量,且在客观指标上更具优势 —— 两者共同覆盖从离线高质量到在线低时延的完整需求。
更高的开源价值:一次开源提供两条强路径,既是可直接落地的工程方案,也是可用于消融、对比与下游创新的高质量基座 —— 让研究者更容易定位关键因素,让工程团队更容易找到适配场景的最优解。
一句话总结:MOSS-TTS 的 “双架构” 不是 “多此一举”,而是我们对真实世界语音生成的核心判断 —— 真正可用的 TTS,不该只在单一指标上赢,而应当在不同场景下都能以明确的权衡给出最强解。
国产 GPU 生态支持
MOSS-TTS 及 MOSS-TTSD 两个主力模型均实现了 壁仞科技 壁砺™ 166M 的 Day-0 高性能推理部署支持。在国产算力生态的加持下,MOSS-TTS 系列将能够深入更多领域和场景。
我们将在独立的技术报告中,对模型设计、训练方法与评测结果进行完整披露。
结语
MOSS-TTS Family 的开源与发布,是团队使命在语音领域的一次落地 多模态 • 开放生态 • 超级智能:既面向生产,把稳定、效率与可控性做到可用可部署;也面向研究,把关键选择与可复现基线交到社区手中。我们相信,通往更强智能的道路,必然来自多模态能力的持续进化,来自开放协作的长期积累,来自把技术推向现实世界的每一次交付。