ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
不是靠堆参数,不是靠更大的数据,而是靠一件事:学会「什么时候该用工具」。
大多数「工具增强」模型是这样的:遇到任务 X → 调用固定工具 Y → 祈祷结果正确。一旦场景稍微变化,模型就开始抽风——不知道什么工具该用、什么工具不该用。
AdaReasoner 解决的是更本质的问题:把 what / when / how(用什么、何时用、怎么用)当成推理能力来学。

论文标题:AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning
论文(arXiv):
项目主页:
代码:
模型与数据:
视频(YouTube):
先看 10 秒效果:
AdaReasoner 工作流程示意
Google 近期宣布,为其轻量级模型 Gemini 3 Flash 引入一项名为「Agentic Vision」(代理视觉)的新能力。
这项更新标志着多模态 AI 处理图像的方式发生了根本性转变:从传统的静态识别,升级为具备「思考、行动、观察」循环的主动调查模式。
在此之前,包括 GPT 在内的大多数前沿多模态模型处理图像的方式类似于人类的「匆匆一瞥」:模型接收图像,进行一次性处理并输出结果。这种方式在面对需要细致观察的任务时,往往会因为细节丢失而产生幻觉或猜测。
Agentic Vision 的工作机制:Gemini 3 Flash 现在能够像人类调查员一样通过以下循环进行推理:
思考(Think)——分析用户指令和图像初步内容,制定调查计划。
行动(Act)——自动生成并执行 Python 代码来操作图像。例如,对图像进行缩放、裁剪特定区域、旋转视角或绘制辅助线。
观察(Observe)——检查代码执行后的新视图或数据,获取更精确的视觉证据。
上述过程可以多次迭代,直到模型收集到足够的确凿证据来回答问题。
有意思的是:AdaReasoner 与 Agentic Vision 殊途同归。AdaReasoner 同样实现并验证了几乎相同的范式:

工业界与学术界同时押注「主动工具使用」,说明这个方向正在成为多模态推理的主流范式。
AdaReasoner 的独特价值在于:我们不只是验证了这套范式有效,更提出了一套让开源小模型也能习得这种能力的训练方法——这正是接下来要详细介绍的内容。
01 痛点:多模态推理为什么
总是「看起来很会,细节就开始猜」?
在多模态推理里,「看清细节」和「多步推理」经常互相卡脖子:
感知不够精确 → 证据不足 → 推理再漂亮也容易变成「guided guessing」;
反过来,如果能把关键证据用工具查出来、画出来、验证出来,模型就能把算力用在判断与规划上。
换句话说:工具不是外挂,而是把推理从「猜」拉回「查」的关键路径。
02 一句话介绍 AdaReasoner:
把工具使用当成「通用推理技能」
AdaReasoner 是一个训练范式:让模型不仅会「调用工具」,更会做三类决策:
选择:该用哪个工具?要不要组合多个工具?
时机:什么时候该用?什么时候不该用?
鲁棒性:工具失败/无用怎么办?是否回退、是否换策略?
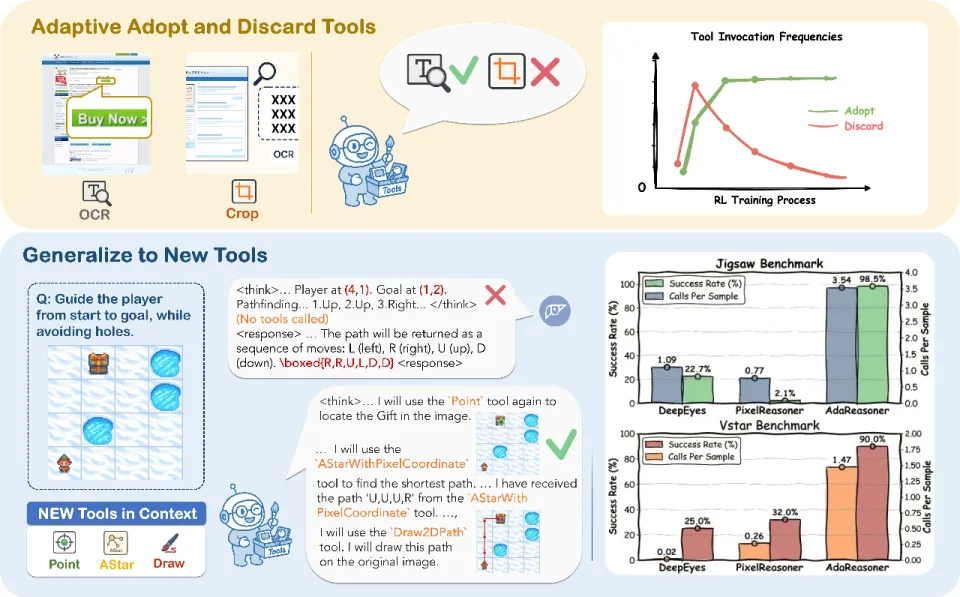
AdaReasoner 把「工具使用」当成推理技能来学习:会采纳有用工具、丢弃无关工具,并按任务调节调用频率。
03 三个关键设计:
让「会用工具」从口号变成能力
3.1 Tool Cold Start (TC):把「犯错-修正」写进数据里
我们不是只给模型看「完美路径」,而是刻意加入两类真实世界会发生的场景:
反思与回溯:试一下 → 检查 → 不对就撤回/换方案。
工具失败处理:工具返回错误/无效 → 及时止损 → 回退到模型自身能力。

定性案例:多轮工具规划 + 反思纠错 + 组合工具完成复杂视觉推理
3.2 Tool-GRPO (TG):优化「多轮工具编排」,而不是单次调用
多模态工具推理往往不是「一次调用结束」,而是多回合:
观察 → 调用 → 再观察 → 再调用 → 最终回答。
Tool-GRPO 针对 multi-turn 场景做了专门的强化学习优化,并用自适应奖励把工具使用变成「不确定时的可靠后备」,而不是强制流程。
3.3 Adaptive Learning (ADL):逼模型学「语义」,别背「名字」
为了避免模型死记硬背某个工具名(比如看到 "Point" 就条件反射),我们做了两件事:
工具名/参数名随机化(去掉字面提示)。
工具描述改写(同一语义、多种表达)。

随机化训练的直观示意
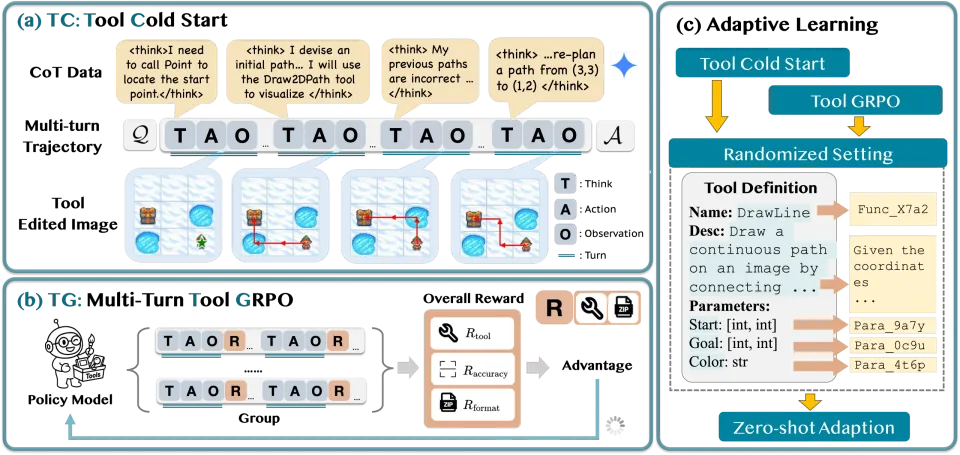
AdaReasoner 框架总览:Tool Cold Start → Tool-GRPO → Adaptive Learning
04 最硬的证据:
小模型为什么能「跨级打怪」?
先给结论:AdaReasoner-7B 相对 base 模型在多个基准上实现显著提升(在选取的 8 个 benchmark 上平均 +24.9%),并在结构化推理任务上接近满分。
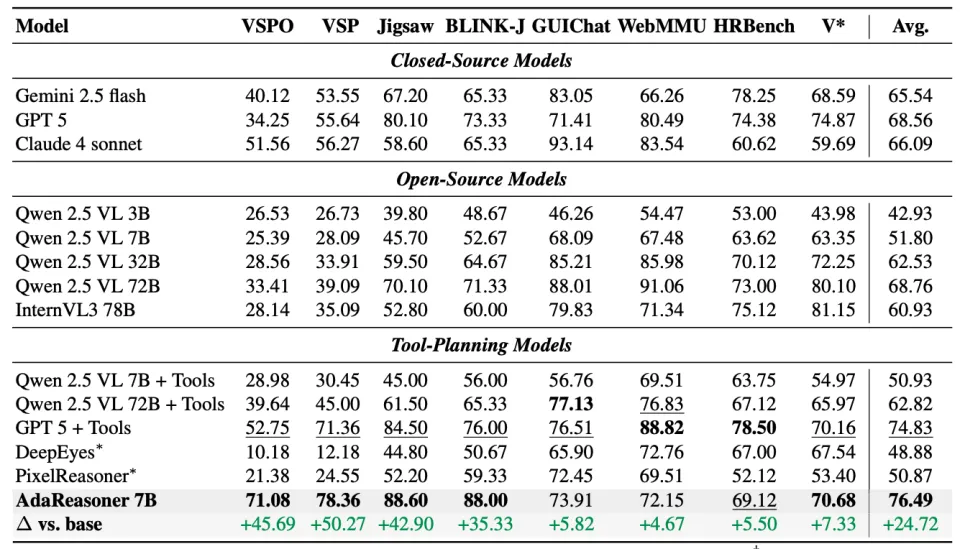
主实验结果:在 VSP、Jigsaw、GUIQA 等任务上显著提升。
更重要的是:不是「工具越多越好」,而是训练配方决定工具是否真的帮得上忙。
例如在单任务设置下:
VSP: Base 28.09 → TC 64.91 → TG 73.18 → TC+TG 97.64
Jigsaw: Base 45.70 → TC 84.20 → TC+TG 96.60(超过 GPT-5 的 80.10)
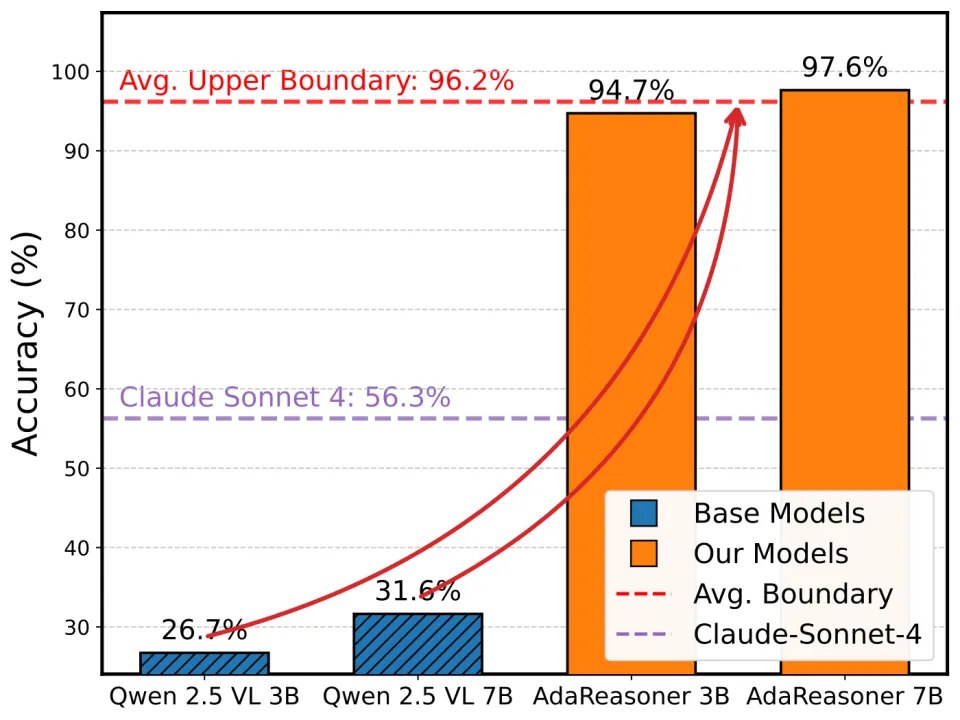
瓶颈迁移示意:当工具规划足够好,性能瓶颈从「模型规模」部分迁移到「工具效用与工具规划能力」
05 最有意思的部分:模型真的
学出了「三种自适应工具行为」
这部分是 AdaReasoner 最像「智能体」的地方:我们没有写规则让它这么做,但它在 RL 过程中学会了。
行为 1:会「采纳」有用的新工具(Adopt)
把 A* 规划工具放进强化学习阶段(Cold Start 没见过),模型会逐步提高调用频率并稳定掌握:
VSP Navigation 从 44.83 → 96.33
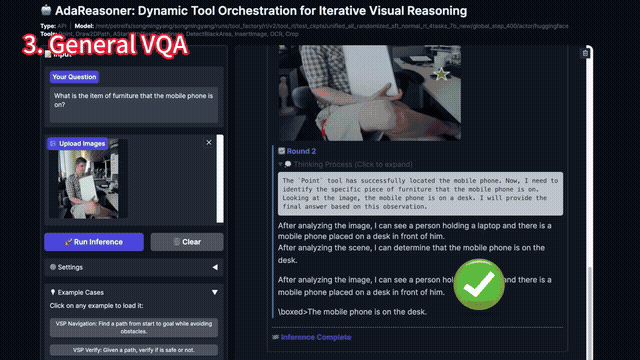
Navigation 任务示意
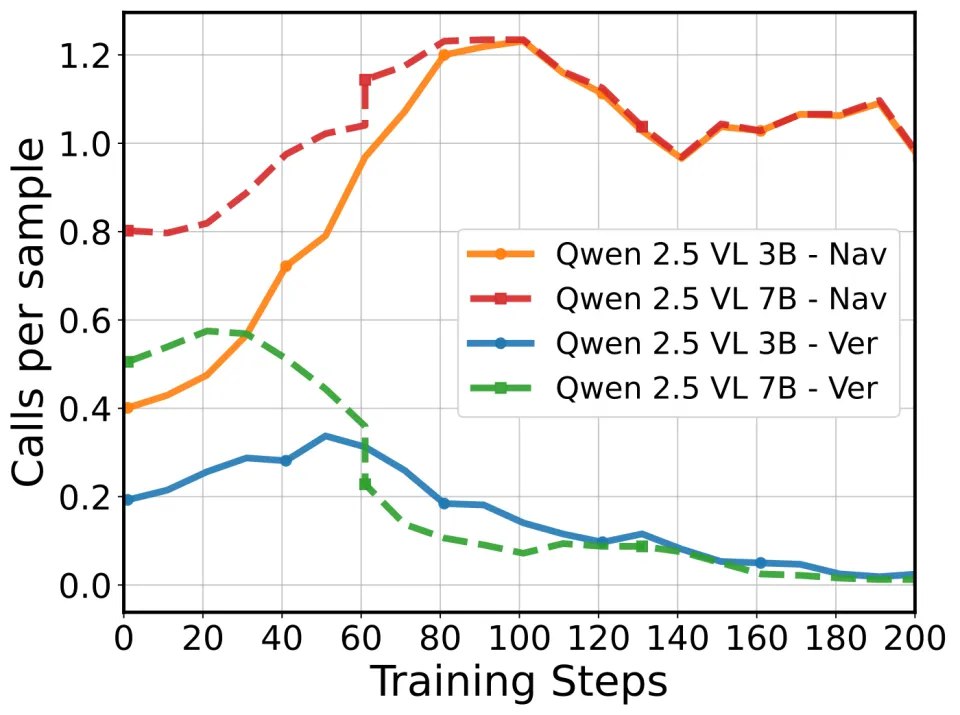
A* 工具调用频率随 RL 训练演化
行为 2:会「丢弃」无关工具(Discard)
更关键的是:A* 对 Verify 任务没用,甚至是干扰项。
在「只在推理时提供 A*」的设置里,Verify 会出现 94.20 → 80.00 的下降。
而在 RL 训练后,模型会逐步压制无关调用,让 Verify 维持在接近满分(99.20)。
一句话:它不仅会用工具,还会学会「别乱用」。
行为 3:会「调节」调用频率(Modulate)
工具也不是开/关二选一。模型会根据子任务「调频」:
Point 工具在导航更关键(~3.2 calls/sample),在验证更克制(~1.0 call/sample)
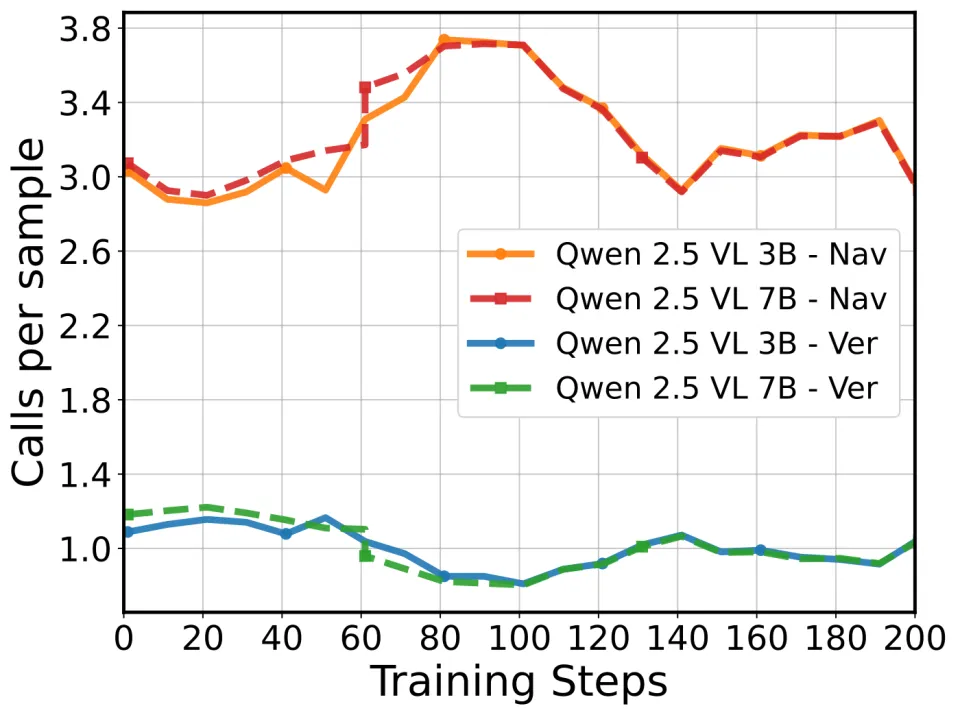
Point 工具调用频率「调频」:Navigation 中更关键,Verification 中更克制
06 换工具说明书
也能用:泛化与稳健性
现实里最常见的崩溃方式是:工具定义、参数名、描述文案一变,模型就「不会用了」。
AdaReasoner 用 ADL(随机化 + 改写)把「工具规划」从文本表面形式里解耦出来。
一个很直观的证据来自工具使用统计:
在 Jigsaw 上达到 3.54 CPS 且工具执行成功率 98.50%,最终准确率 88.60。
在 VStar 这种更开放的 VQA 上仍能主动调用工具(1.47 CPS)并取得 70.68。
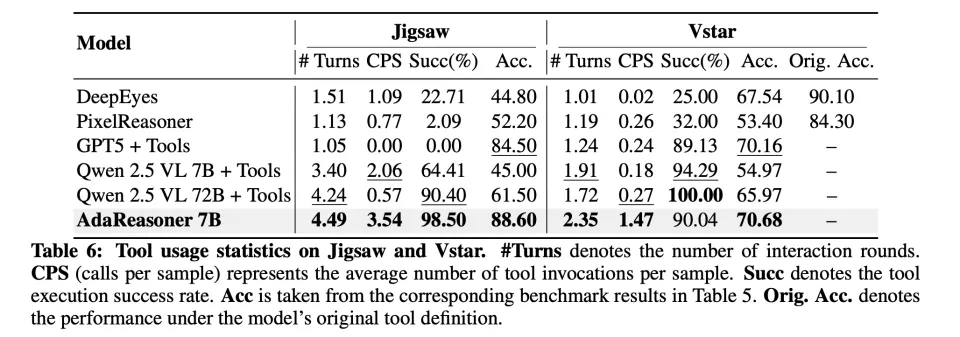
工具使用统计(CPS、成功率)与性能
此外,使用 ADL,模型能够更容易在新的任务上取得更好的表现。我们仅使用 Jigsaw 这一个任务的 SFT 数据,在三个任务上 RL,可以看到,使用 ADL 的版本能够在另外两个任务上给模型带来效果上的提升。
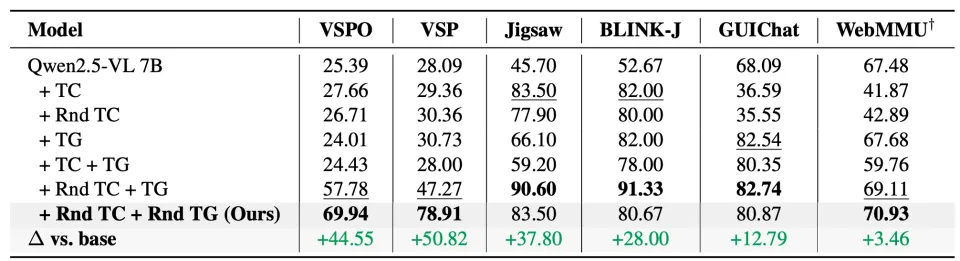
ADL 能将单个任务上学来的 agent planning 能力迁移到 SFT 没见过的任务上。
07 我们想强调的
学术结论(Takeaways)
多模态推理不只是 「think harder」。更关键的是:
actively seeing, verifying, and planning with tools.
当工具编排学得足够好,瓶颈会发生迁移:
model scale → tool utility + tool planning
这对小模型尤其重要:参数有限时,「会用工具」就是最直接的能力放大器。
从 Agentic Vision 看趋势:Google 用 Agentic Vision 把 Think-Act-Observe 内置到 Gemini,学术界用 AdaReasoner 验证这套范式在开源模型上的可行性——两条路线同时验证了「主动工具使用」的价值。对于希望在自己数据/场景上复现这种能力的研究者和开发者,AdaReasoner 提供了一套完整的开源方案。
Adaptive Learning 对提升模型的泛化性也有很大帮助,可以帮助将 agent planning 能力迁移到以前没见过的 agent 和新的任务上去。