ICLR 2026 | PIL:基于线性代理的不可学习样本生成方法
不可学习样本(Unlearnable Examples)是一类用于数据保护的技术,其核心思想是在原始数据中注入人类难以察觉的微小扰动,使得未经授权的第三方在使用这些数据训练模型时,模型的泛化性能显著下降,甚至接近随机猜测,从而达到阻止数据被滥用的目的。
例如,对于摄影师公开发布的作品或用户分享的个人照片,在添加扰动后,图像在视觉上几乎不发生变化;但若这些数据被用于训练图像分类模型,其测试准确率可能会从 90% 降至 10% 左右。
随着深度模型对大规模数据依赖程度的不断提升,不可学习样本逐渐成为数据隐私与模型安全领域的重要研究方向。然而,现有方法在实际应用中仍面临显著的效率瓶颈。

论文链接: https://arxiv.org/abs/2601.19967
代码已开源: https://github.com/jinlinll/pil
现有方法的效率瓶颈
当前主流的不可学习样本生成方法大多依赖深度神经网络(DNN)作为代理模型。其典型流程包括:
1. 训练一个复杂的深度模型(如 ResNet、VGG)作为代理;
2. 在代理模型上通过对抗攻击方法(如 PGD)迭代优化扰动;
3. 利用扰动在其他模型上的迁移性实现防护效果。
这种对深度模型的依赖带来了若干问题:
计算开销高:生成一次扰动往往需要大量 GPU 资源。例如,REM 方法在 CIFAR-10 数据集上的扰动生成时间超过 15 GPU 小时;
扩展性受限:当应用于高分辨率图像或大规模数据集(如 ImageNet)时,时间成本迅速上升;
模型复杂度冗余:深模型的强非线性表达能力并非不可学习样本生成的必要条件,反而增加了优化难度。
核心观察:不可学习样本与模型线性化
我们关注到一个关键现象:不可学习样本的作用机制,本质上是诱导深模型退化为近似线性的行为模式。
我们评估了多种现有不可学习样本方法(包括 EM、REM、TAP、SP、AR 等),发现一个一致现象:无论方法设计多么复杂,最终均会诱导深度模型呈现更强的线性特征(通过 FGSM 的成功率度量)。
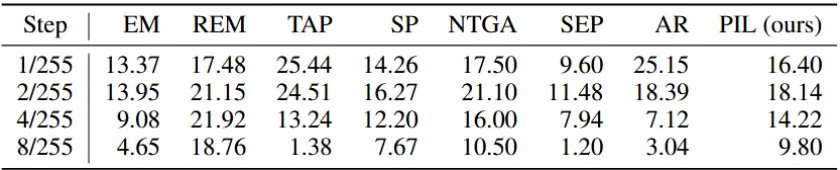
表 1:不同 FGSM 攻击步长下不可学习样本导致的额外准确率下降百分比(扰动比例 50%)
从这一角度出发,如果最终目标是使深模型表现出线性特性,那么使用复杂的深度模型作为代理并非必要。相反,直接利用线性模型生成扰动,可能更直接地作用于这一核心机制。
基于此,我们提出 PIL(Perturbation-Induced Linearization): 通过线性模型作为代理,直接生成能够诱导深模型线性化的不可学习扰动。
PIL 方法概述
与基于对抗攻击的方案不同,PIL 通过一个双目标优化过程,引导模型学习线性映射。
1. 语义混淆(Semantic Obfuscation)
通过最小化 KL 散度,使线性代理模型在扰动后的样本上输出接近均匀分布,从而削弱原始图像中可用于分类的语义信息。
2. 捷径诱导(Shortcut Learning)
通过最小化交叉熵损失,使代理模型能够仅依据扰动准确预测标签,从而将判别信息嵌入进扰动中。
两个目标通过平衡参数 λ 进行联合优化,最终生成的扰动同时抑制语义学习并强化线性捷径,从而在深模型训练阶段诱导其产生显著的泛化退化。
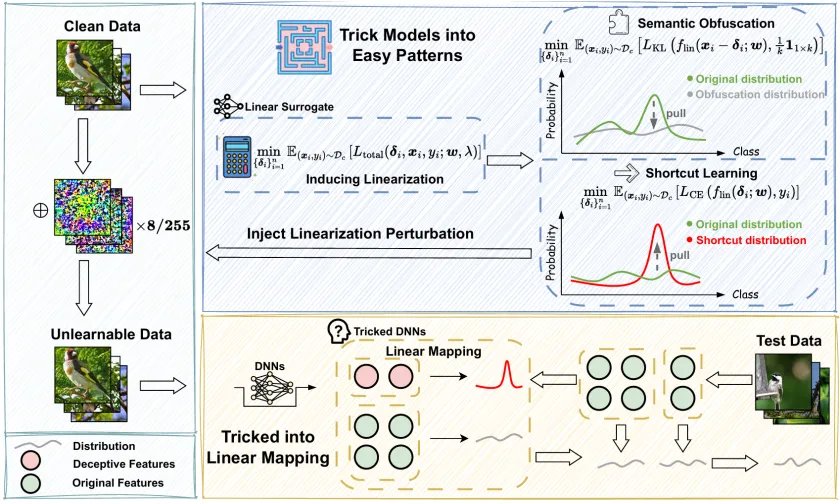
图 1:PIL 方法示意图
PIL 的算法流程(简要)
1. 训练一个无偏置的线性分类器作为代理模型;
2. 在不可察觉约束(L∞≤8/255)下,采用类似 PGD 的方法优化扰动;
3. 将扰动注入原始图像,构造不可学习样本;
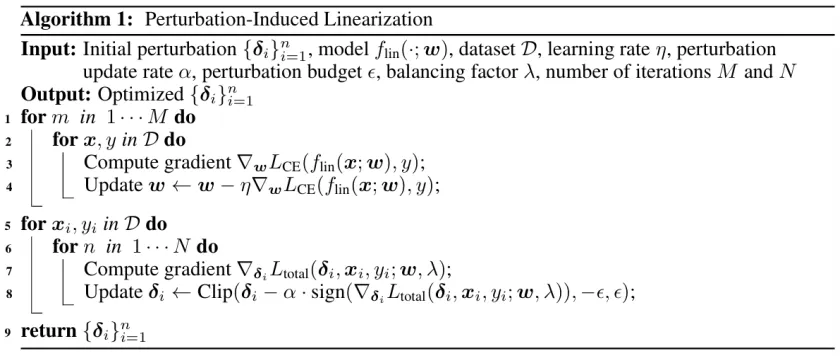
Algorithm 1:PIL 算法流程
实验结果
我们在 SVHN、CIFAR-10/100 和 ImageNet-100 数据集上,结合 ResNet、VGG、MobileNet 等多种模型进行了系统评估。
1. 有效性
在不同数据集和模型架构下,PIL 生成的不可学习样本均能显著降低模型的测试准确率,在部分设置中准确率接近随机水平。
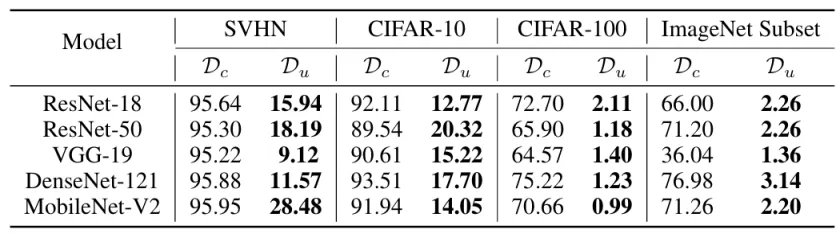
表 2:在干净数据集(Dc)与 PIL 构建的不可学习数据集(Du)上训练的模型在干净数据上的测试准确率(%)对比
2. 计算效率
在 CIFAR-10 上,PIL 生成扰动仅需 40.53 秒,而 REM 方法需要超过 54k 秒,效率提升超过三个数量级。同时,PIL 在效率与防护效果之间取得了较好的平衡。
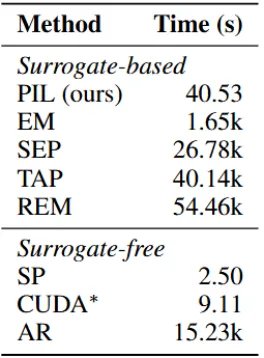
表 3:不同方法为 CIFAR-10 训练集构建全部扰动所需的时间对比
3. 鲁棒性
在多种数据增强策略(旋转、裁剪、MixUp)和不同 JPEG 压缩质量下,PIL 依然保持稳定的防护性能。
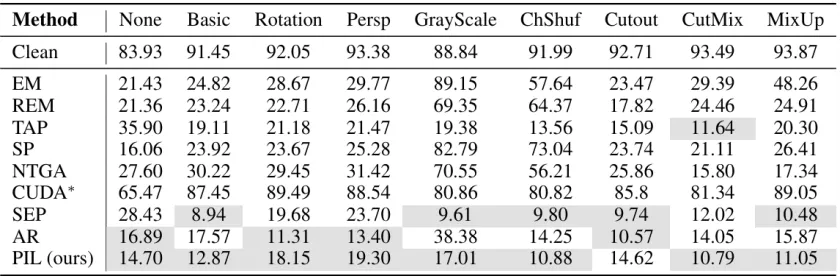
表 4:不同数据增强策略下,各类不可学习样本在 CIFAR-10 上的干净测试准确率(%)。结果越接近 10% 越好。灰色背景标示 Top-2 的两种方法。
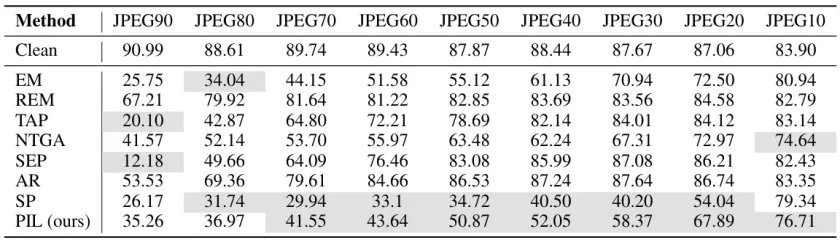
表 5:在不同 JPEG 压缩质量下,各类不可学习样本在 CIFAR-10 上的干净测试准确率(%)。结果越接近 10% 越好。灰色背景标示 Top-2 的两种方法。
4. 线性化验证
我们使用 FGSM 攻击下的准确率下降幅度作为线性化指标。实验表明,随着 PIL 扰动比例增加,模型对 FGSM 的敏感性显著增强,验证了 PIL 确实诱导了模型的线性行为。
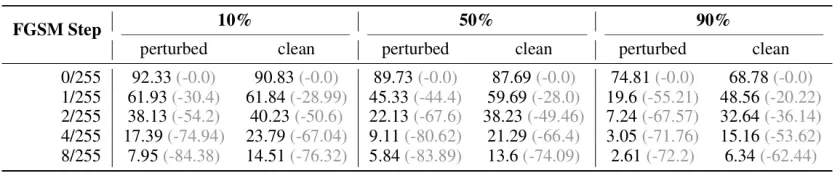
表 6:使用不同干净 / PIL 扰动数据混合比例训练的 ResNet-18 模型,在各 FGSM 攻击步长下的测试准确率及下降幅度(%)
进一步分析:
部分扰动设置下的性能退化受限
在实验中我们观察到一个一致现象:当仅有部分训练数据被扰动时,模型的测试准确率往往不会出现显著下降。这一现象并非 PIL 方法特有,而是现有不可学习样本方法普遍存在的特性。
为解释该现象,我们通过实验发现模型对被扰动样本产生的梯度与对干净样本的梯度呈现很强的正交性,于是我们提出在梯度正交假设,并在该假设下进行了理论分析,得到如下结论:
干净样本与扰动样本在训练过程中所产生的梯度方向近似正交,因此扰动样本对应的梯度更新难以显著干扰模型对干净样本的学习;
在混合训练设置下,模型的泛化性能主要由干净数据主导,只要干净样本数量足够,模型仍能学习到稳定且可泛化的特征表示。

图 2:在部分扰动场景下,CIFAR-10 数据集的干净测试准确率(%)
上述分析表明,部分扰动并不足以从根本上削弱模型的泛化能力。这一定性结论对于实际应用具有直接启示意义:若期望获得稳定且显著的防护效果,需要对数据集进行大比例甚至全部的扰动,或至少保证扰动样本在训练数据中占据足够高的比例(通常高于 80%)。
结语
PIL 的核心在于从机制层面重新审视不可学习样本问题,将关注点从复杂的代理模型与攻击策略,转向「模型线性化」这一关键因素。通过使用线性代理模型,PIL 在显著降低计算成本的同时,依然保持了稳定而有效的防护能力。
我们希望这一视角能够为不可学习样本及相关数据保护研究提供新的思路,并推动更加高效、可扩展的方法设计。