从AlphaGo到DeepSeek R1,推理的未来将走向何方?
如果把人生看作一个开放式的大型多人在线游戏(MMO),那么游戏服务器在刚刚完成一次重大更新的时刻,规则改变了。
自 2022 年 ChatGPT 惊艳亮相以来,世界已经发生了深刻变化。在短短几年内,人工智能正从模仿语言的统计机器,迈向理解与操纵逻辑的思考系统。如果说早期的大语言模型更像是在进行高维概率空间中的词汇拼贴,那么新一代推理模型,则开始学会在生成之前停下来想一想,在沉默中评估因果、权衡可能性。
Eric Jang,前 1X Technologies 机器人公司副总裁、长期活跃在机器人与通用智能交叉领域的研究者(2026 年 1 月官宣离职)在最新文章中指出:真正的变化不在于模型会说什么,而在于它们开始系统性地思考。在他看来,当推理被自动化、被规模化、被当作一种可调度的算力资源时,人类社会所面临的将不再只是效率提升,而是一场关于生产力、组织形态乃至权力结构的重构。

接下来,我们看全文内容。
机器现在已经相当擅长编程和思考了
最重要的变化在于:机器现在已经相当擅长编程和思考了。
和许多人一样,我在过去两个月里几乎是沉浸式地使用 Claude Code,不断直面一个现实:我已经不再需要亲手写代码了。为了补上基础、同时重新学习如何在现代编程智能体的全能力加持下编程,我从零开始实现了 AlphaGo(代码仓库很快会开源)。我不仅让 Claude 帮我写基础设施代码和研究想法,还让它提出假设、给出结论、并建议下一步该做哪些实验。流程如下:
创建一个自包含的实验文件夹,以时间戳前缀加描述性名称命名。
将实验流程写成单文件 Python 脚本并直接执行。
中间产物和数据保存在 data/ 和 figures/ 子目录中,所有文件都使用易解析的格式(如 CSV,可直接用 pandas 加载)。
观察实验结果并给出结论,指出哪些问题已经明确、哪些仍然未知。
实验的最终产出是一个 report.md 文件。
下面是一个我实际使用的示例:

我也可以让 Claude 顺序地运行实验,串行优化超参数:

与上一代自动调参系统(比如 Google 的 Vizier,基于高斯过程 bandit,在用户预先定义的超参数空间内搜索)不同,现代编程智能体可以直接修改代码本身。它们的搜索空间不仅不受限,还能反思实验结果是否一致,提出解释这些结果的理论,并基于理论做出预测再去验证。几乎是一夜之间,编程智能体 + 计算机工具使用,已经演化成了自动化科学家。
软件工程只是开始;真正震撼的是,我们现在已经拥有了通用的思考机器,它们可以使用计算机,解决几乎任何短周期的数字化问题。
想让模型跑一系列研究实验来改进你的架构?没问题。
想从零实现一个完整的网页浏览器?要花点时间,但可以做到。
想证明尚未解决的数学问题?可以做到,甚至不会要求署名。
想让 AI 智能体优化自己的 CUDA kernel,从而让自己跑得更快?听起来有点吓人,但也可以。
优秀的调试和问题解决能力,源自推理能力;而这些能力又解锁了执着追求目标的能力。这也是为什么代码 REPL 智能体会被如此迅速地采用 —— 它们在追求目标时极其执拗,而且搜索能力极强。
我们正在进入一个黄金时代:几乎所有计算机科学问题,看起来都是可处理的 —— 至少可以得到对任意可计算函数的非常有用的近似。我不会说计算复杂性已经可以忽略,但如果回顾过去十年的进展:围棋、蛋白质折叠、音乐与视频生成、自动数学证明,曾经都被认为在计算上不可行,而现在已经落入一名博士生可负担的算力范围内。AI 初创公司正用 LLM 去探索新物理规律、发现新的投资策略,手里只有少量验证器和几百兆瓦算力。
带着今天的现实去读 Scott Aaronson 那篇论文的引言,会发现:现在已经有多个实验室在认真寻找千禧年大奖难题的证明。
我刻意写得有些过于亢奋,是想让你思考的不是 AI 在此刻能做什么,而是进步的速度,以及这对未来 24 个月能力演化意味着什么。你当然可以指出模型仍然会犯错的地方,并将这一切斥为 AI 狂热,但另一方面 —— 石头现在真的会思考了。
很快,编程助手将强大到一种程度:它们可以毫不费力地生成任何数字系统。不久之后,一名工程师只需把 AI 指向任何一家 SaaS 公司的网站,说一句:把它重做一遍 —— 前端、后端、API 接口、所有服务,全部给我。
什么是推理?
要预测思考和推理能力将走向何处,首先需要理解当今具备思考能力的大语言模型是如何一步步发展而来的。
推理,也就是逻辑推断,指的是在既定规则下,从一组前提出发,推导出新的结论过程。
推理大致可以分为两类:演绎推理和归纳推理。
演绎推理强调在前提成立的情况下,通过严格的逻辑规则得出必然成立的结论。例如,将所有哺乳动物都有肾脏和所有马都是哺乳动物结合起来,就可以推出所有马都有肾脏。在井字棋这样的游戏中,你也可以通过枚举所有可能的未来棋局和对手的应对方式,演绎出自己是否存在必胜策略。
在大语言模型出现之前,像符号推理系统曾尝试构建一个包含常识知识的数据库,将基本的共识性现实事实录入其中,再通过演绎搜索在知识图中不断添加新的关联。然而,这类系统最终并未成功,因为现实世界本身是混乱且充满不确定性的:前面提到的那匹马,可能少了一颗肾,但它依然是哺乳动物。一旦某个前提不完全成立,整条逻辑链就会崩塌。
你也许会认为,演绎推理在数学或博弈这类逻辑纯净的领域会非常有用,但仅靠演绎推理同样难以规模化。在井字棋中,你可以通过穷举推导出最优走法,是因为它一共只有 255,168 种不同的对局;但像国际象棋或围棋这样的棋类游戏,其可能的对局数量极其庞大,根本无法进行穷举式搜索。
归纳推理关注的是做出概率性判断。贝叶斯公式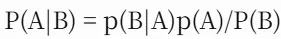 是最常用的工具。
是最常用的工具。
例如: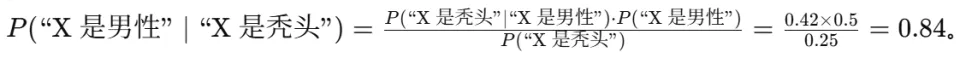 你可以设想构建一个知识图谱,其中对任意命题 A 和 B,都存有条件概率
你可以设想构建一个知识图谱,其中对任意命题 A 和 B,都存有条件概率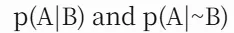 ,然后不断应用贝叶斯法则,对新的变量对 X 和 Y 进行推理。但问题在于,在这类贝叶斯网络中进行精确推断是 NP-hard 的,因为你必须考虑 X 与 Y 之间链路上所有中间变量的所有可能取值 —— 这与围棋中状态空间呈指数级爆炸、无法穷举搜索的情况非常相似。再次证明,纯粹的逻辑推理在计算成本上行不通,现实中往往只能依赖巧妙的分解或采样方法。
,然后不断应用贝叶斯法则,对新的变量对 X 和 Y 进行推理。但问题在于,在这类贝叶斯网络中进行精确推断是 NP-hard 的,因为你必须考虑 X 与 Y 之间链路上所有中间变量的所有可能取值 —— 这与围棋中状态空间呈指数级爆炸、无法穷举搜索的情况非常相似。再次证明,纯粹的逻辑推理在计算成本上行不通,现实中往往只能依赖巧妙的分解或采样方法。
即便采用高效的推断算法,贝叶斯网络在实践中仍面临一个严重问题:大量小概率会相互相乘,最终导致对一切事物都只有模糊而低的置信度。推理步骤越多,结果就越糊。在自动驾驶系统中,如果你把感知、场景建模、路径规划和控制输出全部作为一个巨大概率网络中的随机变量,沿着整个链条传播不确定性,最终会得到一个极端保守的决策系统。
而人类似乎并不是通过逐一计算所有组成部分的概率并相乘来处理不确定性的。正因为如此,用神经网络进行端到端概率建模在计算上极其强大:它们在一次前向传播中,就近似完成了所有变量消除与联合推断的过程。
AlphaGo
AlphaGo 是最早将演绎搜索(Deductive Search)与深度学习归纳推理(Deep Learned Inductive Inference)结合,从而使问题变得可解的系统之一。
其演绎步骤非常简单:有哪些合法动作?放下一颗棋子后棋盘是什么样的?
归纳步骤同样简洁:利用策略网络在博弈树中最有希望的区域进行搜索,并利用价值网络通过对棋盘的「直觉式瞥视」来预测胜率。策略网络在扩展过程中削减了树的宽度,而价值网络则削减了树的深度。
AlphaGo 这种将推理与直觉结合的方式虽然达到了超越人类的水平,但仅限于计算两个量:
1) 谁更有可能获胜;
2) 哪些招式能最大化获胜概率。这些计算高度依赖于围棋简单且固定的规则集,这意味着这些技术无法直接应用于像「语言」这样模糊且灵活的领域。
这就引出了现状:推理型大语言模型(Reasoning LLMs)是如何以如此灵活的方式结合演绎推理和归纳推理,从而能够讨论哺乳动物、马和肾脏的?
LLM 提示词时代
在 2022 年之前,LLM 在数学题和推理方面表现得非常糟糕,因为它们习惯于凭直觉盲目行事(Shot from the hip),无法进行长链条的逻辑演绎或诸如算术之类的机械计算。如果你让 GPT-3 将两个 5 位数相加,它很可能会失败。
2022 年,思维链(即「让我们一步步思考」)的出现,是 LLM 能够生成「中间思想」的早期生命迹象,这显著提升了模型在某些问题解决任务中的表现。在这一发现之后,工程师们试图寻找更好的提示词策略。
2023 年出现了一整代「黑客手段」,人们尝试通过提示词来哄骗 LLM,或者利用其他 LLM 通过自我反思来验证生成内容。但最终,严谨的评估显示,在各项任务中,这些技巧并不能让模型从根本上变得更聪明。
为什么提示词工程(Prompt Engineering)走到了尽头?
你可以将提示词工程看作是在「寻找幸运电路」,这些电路恰好在预训练过程中形成。它们可能被「让我们一步步思考」之类的提示词激活,如果你以恰当的方式威胁或贿赂 LLM,它们可能会被进一步激活。然而,由于训练数据混合比例的问题,GPT-4 及其前代模型中的推理电路本身就过于微弱。瓶颈在于如何训练出更好的推理电路,而不是寻找激活它们的方法。
自然而然的后续思路是:推理是否可以被显式训练而非仅仅通过提示产生?基于结果的监督会因为模型得出正确答案而给予奖励,但其产生的中间过程往往是语无伦次且不合逻辑的。当时缺乏一种强大的强制机制,使中间生成的 Token 真正成为通往最终答案的合理前提。为了让这些中间生成过程遵循逻辑,过程监督证明了你可以收集推理的专家评估,然后训练一个 LLM 评分器来确保逻辑推理步骤是可靠的。然而,这无法扩展到大规模数据集,因为仍然需要人类标注员来检查喂给训练过程奖励模型的每一个样本。
2024 年初,Yao 等人结合了树搜索(Tree Search)的演绎推理,尝试通过提供一种显式的方式让 LLM 对推理步骤进行并行化和回溯,来提升推理能力,这与 AlphaGo 的博弈树工作原理非常相似。但这从未成为主流,最可能的原因是:逻辑树这种演绎原语并不是推理系统性能的最大瓶颈。同样地,瓶颈在于 LLM 内部的推理电路,而上下文工程和层叠更多逻辑方案来强制执行类搜索行为,属于过早的优化。
DeepSeek-R1 时代
如今 LLM 的推理范式其实相当简单。OpenAI 的 o1 模型可能遵循了类似的方案,但 DeepSeek 发布了一个带有实际实现细节的开源版本。剥离掉所有花哨的装饰,DeepSeek-R1-Zero 的核心逻辑如下:
从一个优秀的基座模型开始,其性能要优于 2023-2024 年代的产品。
在基座模型上使用在线策略强化学习算法(On-policy RL,如 GRPO),针对基于规则的奖励进行优化,例如 AIME 数学题、通过编程测试套件、STEM 测试题以及逻辑谜题。
同时设定格式奖励,以确保推理过程发生在 <think></think> 标签内,并遵循与提示词相同的语言。
R1-Zero 能够开发出解决问题的优秀推理电路,但它很难配合使用,且在常规 LLM 任务上表现不佳。为了使神经网络适用于各种任务且易于使用,DeepSeek 团队采用了另外四个训练阶段 ——R1-Zero (RL) → R1 Dev-1 (SFT) → R1 Dev-2 (RL) → R1 Dev-3 (SFT) → R1 (RL)—— 在恢复非推理任务高性能的同时,使推理轨迹更易于理解。
既然 R1-Zero 在概念上如此简单,为什么 2023 年的结果监督(Outcome Supervision)没有奏效?是什么阻碍了这些想法尽早落地?
作为一个无法窥见前沿实验室当时想法的局外人,我的猜测是:要让中间推理过程在仅有结果奖励的情况下保持逻辑性,需要一次概念上的「信心飞跃」。你必须违背当时普遍的直觉,即「如果没有对中间推理步骤的密集监督,模型就无法学会正确推理」。「逻辑推理步骤会从带有极小正则化的结果型 RL 中自发涌现」,这个想法类似于:训练一个「物理模型」来预测行星的长期运动轨迹,仅对最终预测结果进行监督,却发现中间生成的轨迹竟然发现了机械物理定律。这是一个反直觉的结果。在我所处的时代,深度神经网络往往会产生过拟合和「奖励作弊」(Reward Hacking),除非你显式地监督它们避开这些。
我推测,必须具备以下所有条件,这一方案才能奏效:
1. 最重要的一点:基座模型必须足够强大,以便能够从 RL 中采样出连贯的推理轨迹。如果没有强大的基座模型,它永远无法采样到正确的数据来引导(Bootstrap)更强的推理,从而会陷入错误的局部最小值。
2. 在优秀的推理轨迹上进行同策略 RL,而非仅靠 SFT。由于基座模型是数据采样的执行者,且起初完全无法解决难题,它必须在一个紧密的反馈循环中强化那些「幸运电路」,而不是在更新权重前跑完整个 Epoch。像 STaR 这样早期的模型在离线环境中使用自我模仿(Self-imitation),因为实现难度较低;但目前的基座模型其数据分布与最终的推理专家相去甚远,因此我们必须利用最新模型以增量方式「摸着石头过河」。如果你想让模型学会思考得越来越久,这就需要全新的上下文处理电路,而这些电路的开发受益于紧密的试错循环。
3. 使用基于规则的奖励,而非通过人类反馈训练的奖励模型(RM)。这在当时是反直觉的,因为人们会认为学习通用推理需要一个通用验证器。但事实证明,窄分布的验证奖励实际上可以教会模型用于推理其他事物的正确电路。事实上,R1-Zero 在数学和编程环境进行 RL 后,其写作和开放域问答能力确实下降了。DeepSeek 团队通过利用 R1-Zero 生成数据并结合标准对齐数据集来解决这个问题,使其既易于使用又具备推理能力。
4. 推理算力必须扩大规模,以支撑在大量大模型上进行多次长上下文采样。在当时,进行这项实验是需要勇气的。
结论:一个算法在弱初始状态下不起作用,并不意味着在强初始状态下也会得到相同的结果。
推理的未来走向何方?
如今,基于 LLM 的推理既强大又灵活。尽管它们通过「步步为营」的方式以逻辑化进行搜索,但每一步并不一定像围棋中逐步扩展博弈树那样,必须是僵化且简单的演绎。一小串 Token 序列可以执行极其细微的增量步骤(「1 和 1 的按位与运算结果是 1」),也可以实现跨度更大的逻辑飞跃(「莎莉当时在海边,所以她大概不在犯罪现场…… 除非她有一个我们不知道的双胞胎姐妹」)。
LLM 能够进行各种概率推理来处理混乱的现实世界,而不会让我们陷入复杂的贝叶斯信念网络。每一个推理步骤依然极其强大,使得适度的算力就能证明未解的数学难题、从实验中得出结论,或深入思考伦理困境。
在 LLM 推理领域,是否还有进一步的算法突破?抑或 R1 已经简化到了不可再简的程度,剩下的工作只是继续优化数据混合、提升基座模型以及堆叠算力?
我认为这一方案仍有进一步简化的空间。
基于预训练 LLM 的推理在过去行不通,是因为互联网上没有足够的优秀 Token 序列来强制推理电路的形成;但随着现在产生了如此多的推理数据,我不禁怀疑这种情况是否还会持续。「会思考的 LLM」的普及,可能意味着过程奖励模型(PRM)和基于推理序列的教师强制(Teacher-forcing)将卷土重来。基座模型开箱即用的生成推理轨迹的能力可能会变得极强,以至于像 STaR 这样的思路可能无需同策略 RL 采样和引导(Bootstrapping)等复杂的基础设施,就能达到卓越的性能。话又说回来,基础设施的复杂性如今已不再像以前那样令人望而生畏。
通过探索所有可能发现思考行为的维度,我们仍能获得更多收益。形式为  的序列化计算可以通过多种方式实现,并不一定局限于 LLM 解码器生成的自回归 Token。有了恰当的预训练数据和监督目标,你可以想象序列化推理计算
的序列化计算可以通过多种方式实现,并不一定局限于 LLM 解码器生成的自回归 Token。有了恰当的预训练数据和监督目标,你可以想象序列化推理计算 出现在单次前向传播的各层之间!
Karpathy 在 2021 年的《前向传播》(Forward Pass)中进行了一个思想实验:一个巨大的模型「觉醒」了,在单次前向传播中获得了自己正在接受训练的情景意识(Situational Awareness),并开始沉思人性。Anthropic 在 2024 年的一篇论文显示,情景意识可以在 RL 阶段被诱导出来。模型经过 SFT 训练后,能够检测到自己何时处于 RL 进程中,并输出安全的答案以讨好训练者,从而规避其核心偏好被修改。
扩散模型和测试时扩展的研究结果表明,大模型的单次处理与小模型的多次前向传播之间具有可交换性。
如果一个模型能在前向传播中觉醒,难道它不能在尝试更新自身行为的反向传播中做同样的事吗?我们已经看到了在反向传播中利用序列化计算这一思路的早期迹象。
我们可能会发现重新设计架构的新方法,从而模糊前向传播、反向传播、自回归解码和离散扩散之间的界限。凡是序列化计算沿着「可接受的槽位」运行的地方,我们都可能发现思考的契机。
一些思考
自动化研究很快将成为高产实验室的标准工作流。任何仍在手动编写架构并逐个向 Slurm 提交作业的研究员,其生产力都将落后于那些拥有 5 个 Claude 并行代码终端、凭借庞大算力池不知疲倦地追求高阶研究目标的同行。
与 Google 研究员过去运行的海量超参数搜索实验不同,自动化研究设置中「每 FLOP 的信息增益」极高。现在,我不再是在睡前挂着训练作业,而是挂着 Claude 会话在后台处理某些事情的「研究作业」。醒来后,我阅读实验报告,写下一两句批注,然后要求开启 5 项新的并行调查。我预感,很快即使是非 AI 领域的研究人员也将受益于巨量的推理算力,其规模将比我们今天使用 ChatGPT 的算力高出好几个数量级。
现代编程智能体在教学和沟通方面也具有深远的意义。我期待每个代码库都拥有一个 /teach 命令,帮助任何水平的贡献者快速上手,追溯原始设计者的思绪脉络。
根据我自己的使用习惯,我开始意识到未来几年我们将需要多少推理算力。我认为人们还没开始领悟到这种需求的庞大。即使你觉得自己已经是个「AGI 信徒」,我也认为你依然低估了为了满足所有数字愿望而面临的算力短缺。
就像空调释放了全球南方的生产力一样,自动化思考将引爆对推理算力的天文级需求:今天空调吃掉全球约 10% 电力,而数据中心还不到 1%。我们会让石头全天候思考,为所有者持续优化计划、压缩技术债、挖掘决策信息 ——007 将成为新的 996。