ICLR 2026|把LLM Embedding Model算力瓶颈,从Query侧彻底移走,LightRetriever来了
近年来,大模型文本检索(LLM-based Text Retrieval)技术发展迅猛,SOTA 的 LLM Embedding Model 参数量普遍在 7B 以上,相关性搜索性能提升的同时,部署成本也大幅增长。
众所周知,LLM Embedding Model 是一种对称式双塔结构,Query 和 Doc 侧常共享同一个完整的 LLM。但一个长期被忽视的问题是:线上推理中,查询端(Query)真的需要和文档端(Document)一样 “重” 的大模型吗?在我们最新的研究论文 LightRetriever 中,文章给出了一个明确、激进、但被大量实验证实可行的答案:不需要。
LightRetriever 设计了一种极致非对称式结构的 LLM Embedding Model —— Doc 侧使用完整 LLM 建模,但 Query 侧最多仅用一层 Embedding Lookup。极致化降低了 Query 侧推理负担,也能做好大模型文本搜索。对比 Query-Doc 均用完整 LLM 的标准设计,LightRetriever 让 Query 侧的推理速度提升了千倍以上、端到端 QPS 提升 10 倍,同时 BeIR、CMTEB Retrieval 等测试集上的中英文检索性能也能维持 95% 左右。
文章由中科院信工所 & 澜舟科技共同完成,已接收于国际计算机顶级会议 ICLR 2026。ICLR(International Conference on Learning Representations)是机器学习与表示学习领域的国际顶级会议之一,与 NeurIPS、ICML 并列为人工智能方向最具影响力的学术会议。本次 ICLR 2026 共有接近 19000 篇有效投稿,接收率约为 28%。

论文标题:LightRetriever: A LLM-based Text Retrieval Architecture with Extremely Faster Query Inference
论文链接:https://arxiv.org/abs/2505.12260
LightRetriever:极致非对称的 LLM Embedding Model
LightRetriever 的核心思想非常明确:将深度建模的主要计算负担彻底转移到 Doc 侧,Query 侧只保留必要、可缓存的表征能力。LightRetriever 为稠密和稀疏检索两大检索范式,分别设计了极致非对称的建模方法。
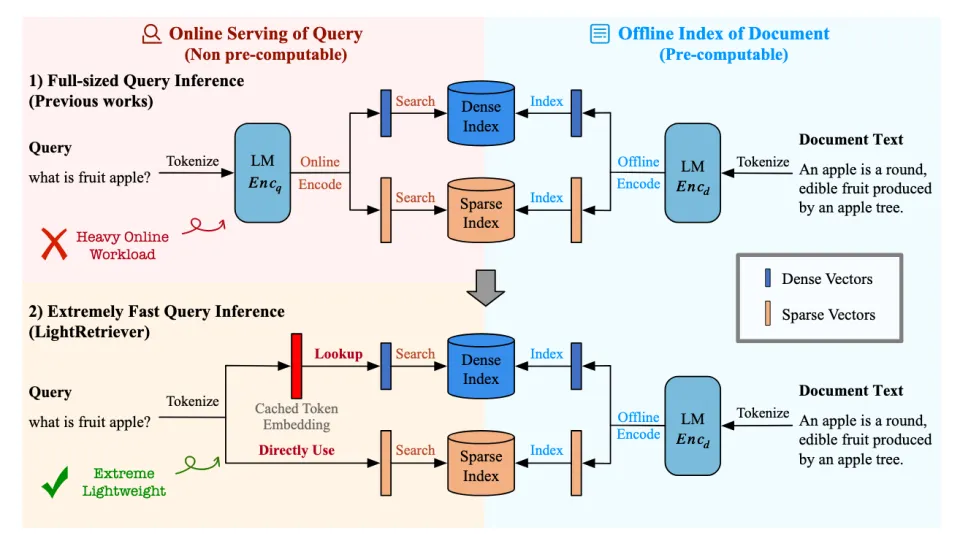
图。在稠密 / 稀疏检索中,对称式 LLM Embedding Model 使用了 1) 标准的 Full-sized Query Inference,查询侧推理负担很重;2) LightRetriever 大幅降低了查询推理成本,查询侧负载降低至不超过一层 Embedding Layer Lookup。
稠密检索(Dense Retrieval)训练中,Doc 侧保持建模方式不变,LightRetriever 词袋化了 Query 侧建模:完整的 LLM 接收 “指令 + 单个 Query Token” 作为输入,先建模 Token Embedding,再求平均获取 Query 句向量,并通过对比学习获得 Prompted Token Embedding。

不同之处在于,这些 Token Embedding 在训练完成后,可以被整体缓存为一个词表级 Embedding 矩阵。在线推理时,Query 句向量的推理仅需一次简单的 Token Embedding 查表 + 求均值,不再涉及任何 LLM 推理。由于 Query 侧在训练阶段仍需要完整 LLM 建模,稠密向量训练遵循 “训练全量 + 推理轻量” 的思想。后面的消融实验证明,“训练全量” 这种配置不可忽略。
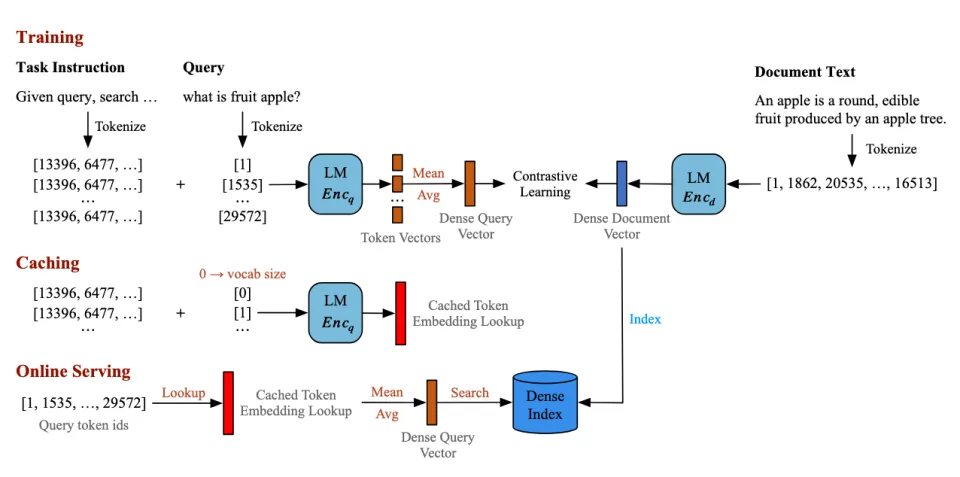
图. LightRetriever 的稠密检索设计遵守 “训练全量 + 推理轻量” 的思想,通过词袋化 Query 侧建模,打破上下文依赖,使得 Query 侧向量推理具备可缓存(Cacheable)的特性。仅需一次缓存,就可以无 LLM 部署 Query 推理服务。
稀疏检索(Sparse Retrieval)中,LightRetriever 将 Query 侧进一步被简化为词表空间 T 的 “Token ID -> 个数” 的词频映射,完全移除了可学习的模型参数。

同样通过端到端对比学习,通过 Doc 侧的 LLM,学习类 SPLADE 方法的 TF-based (Term Frequency-based)稀疏向量。
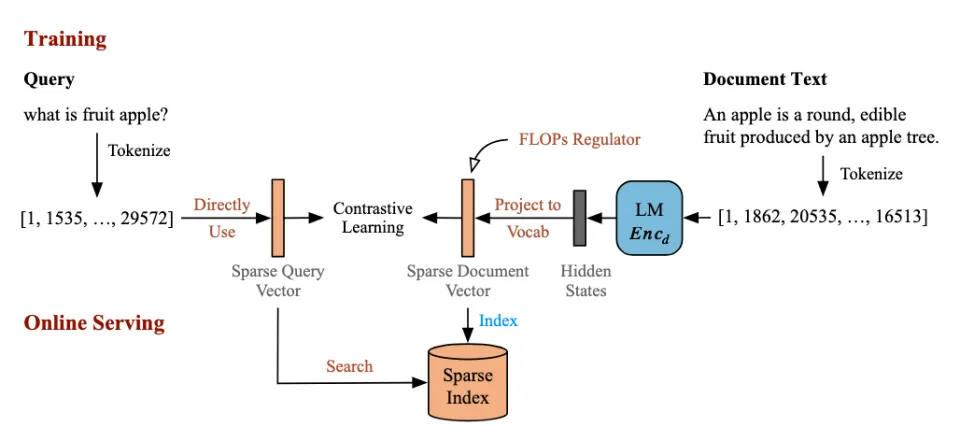
图. LightRetriever 的稀疏检索设计更加极致,Query 侧仅依靠词袋化的统计方法建模词频特征,来实现无 LLM 高效化线上推理。
极端轻量化的查询,并没有带来灾难性的性能代价
直觉上,移除 Query 侧的深度上下文建模会显著损害检索效果。然而,大规模实验结果给出了一个出乎意料的结论:
在 BeIR(英文)与 CMTEB-Retrieval(中文)等多任务文本检索基准上,相对完整的对称式 LLM Embedding,LightRetriever 的 nDCG@10 排序指标只下降 1–5 pp,平均性能保持率约为 95%。更重要的是,该方法的性能水平大幅超过传统稀疏方法(BM25、SPLADE)以及多种轻量化或蒸馏检索模型,并逼近了类似开源训练语料的配置下,LLM2Vec、E5-Mistral 等经典的 LLM Embedding 方法。
这表明:在绝大多数相关性导向的检索任务中,Query 侧并不需要完整的深度 Token 交互,也能够匹配 Doc 侧所学习到的语义结构。
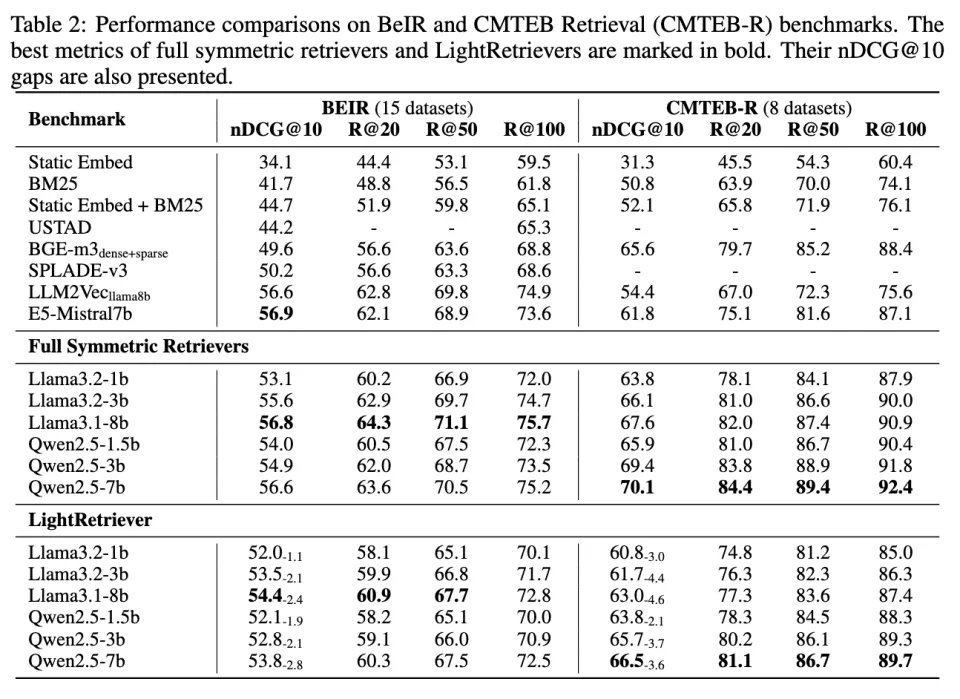
表. BeIR / CMTEB-Retrieval 主实验结果,包含经典 Embedding Model Baseline、对称式 Full LLM Retriever 与 LightRetriever 的检索效果。
文章对比了 LightRetriever 在不同任务中的细粒度性能表现。以 BeIR 为例,LightRetriever 在大多数常规的相关性检索任务中性能表现十分优异,是全对称式结构的 93% 以上;在 Domain-specific QA、Entity Retrieval、Citation Prediction 等更具挑战性的 OOD 任务中,性能维持在全对称式结构的 87%~89%。虽然相对性能略有下降,这些任务性能的绝对数值仍然具备较强的竞争力。
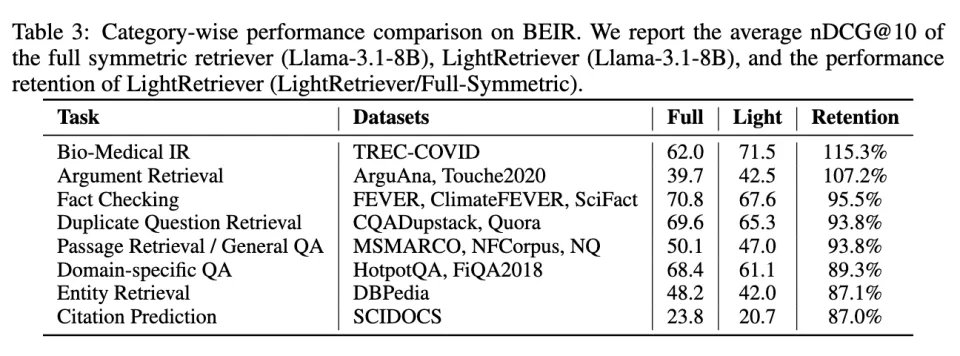
表。在 BeIR 的不同任务中,LightRetriever 的性能表现及相对变化(Retention)。
查询服务速度大幅提升
LightRetriever 的 Query 轻量化设计,为查询推理效率带来了数量级的提升。
在 MSMARCO 检索场景下对 64k 查询进行检索,完整的 Llama-8B 查询编码需要超过 100 秒;而 LightRetriever 的查询编码时间仅为 0.04 秒,对应超过 1000× 的编码加速。即便考虑 Faiss 与 Lucene 的检索时间,端到端吞吐仍然获得了 10× 以上的 QPS 提升。文章还尝试了一个经典的 Transformers Layer 裁剪 Baseline:在 Query 侧只用 Llama-8b 的第一层 Transformers Layer 用于训练和推理。然而,这个设置的检索性能和 QPS 均不如 LightRetriever,因为训练时 Query 侧没有完整的 LLM 建模。这证明了文章中 “训练全量 + 推理轻量” 的设计的合理性。
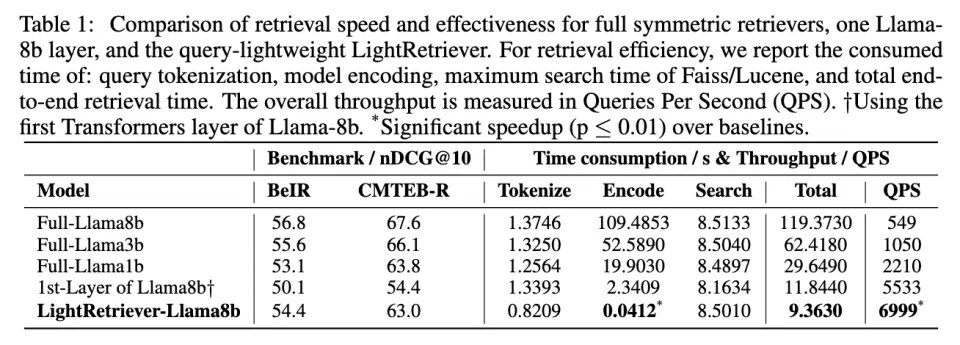
表。查询编码时间 / 端到端 QPS 对比
为什么这种 “训练全量 + 推理轻量” 是必要的,而不是偶然有效?
在 LightRetriever 的稠密检索中,Query 侧在训练时使用全量(Full)建模、推理时转化为 Embedding Layer(Emb)高效化推理。为了验证这种设计的合理性,文章进行了以下两组消融实验:
A1) Doc 侧在推理时也使用 Embedding Layer。
A2) Query 侧在训练时直接用 Embedding Layer。
两者均会引起性能的大幅下降。这说明:在大模型文本检索中,移除深度建模并非偶然设计。
消融实验一(A1)证明了:Doc 侧始终需要完整建模,而 Query 侧可通过词袋化方法做到近似建模。
消融实验二(A1)证明了:LightRetriever 的关键不在于 “减少建模”,而在于将建模负载卸载至不同阶段 —— 在训练阶段与 Doc 侧充分建模,在推理阶段最大化复用可缓存的 Query 词向量,即 “训练全量 + 推理轻量”。
从这一角度看,LightRetriever 并不是一次针对模型结构的微调,而是对 LLM 双塔模型计算范式的重新审视。

表。对称性消融实验。A1) Doc 侧推理时也进行了词袋轻量化;A2) Query 侧训练时直接使用了 Embedding 词袋。两者效果均显著下降。
结语:当 Query 侧部署不再是负担,LLM 检索才真正具备可扩展性
LightRetriever 表明,高质量的 LLM Embedding Model 并不必然意味着高昂的在线推理成本。通过明确区分 Query 与 Doc 在检索流程中的角色,并有意识地打破对称建模这一长期默认的设计假设,检索系统可以在维持效果的前提下,获得数量级的效率提升。
对于面向真实应用场景的检索系统、RAG 框架与在线搜索服务而言,这种查询轻量化的建模思路,或许比单纯追求更大的模型规模更具应用价值。
作者简介
文章第一作者为中国科学院信息工程研究所博士研究生马广远,研究方向为大模型信息检索,导师是虎嵩林研究员。本文在微软亚研院前副院长、现澜舟科技 CEO 周明博士和虎嵩林研究员的共同指导下完成。