Terminal-Bench解决率暴涨20%!华为CLI-Gym:环境交互类任务首个公开的数据Scaling方案
「首个公开的面向 Terminal-Bench 环境交互类任务的数据规模化生产管线正式发布!」
开源完整自动化数据构建算法
构建 1655 个高可靠 CLI 任务环境镜像
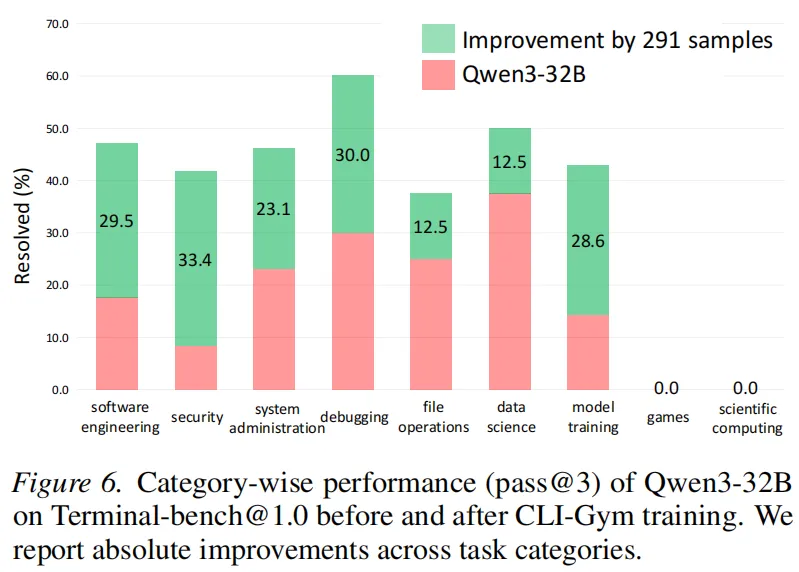
通过 291 条轨迹数据带来 20% 解决率提升
在 Agentic Coding 领域,基于 SWE-bench 的数据管线研究已取得长足进展。过去一年中,业界涌现了大量相关工作,例如 SWE-Gym、SWE-Smith 和 R2E-Gym 等,极大推动了以代码生成为核心的 Agentic Coding 发展,也使得当前最先进的开源模型与闭源模型之间的表现差距显著缩小。然而,对于更广泛的环境交互类问题(如 Terminal-Bench 所涵盖的任务),目前尚没有公开的高效和可规模化的数据生产方案,导致相关数据构建困难重重,高度依赖人工参与,这已然成为制约该方向发展的瓶颈,也使得在相关任务上开源模型的表现大幅落后于闭源模型。
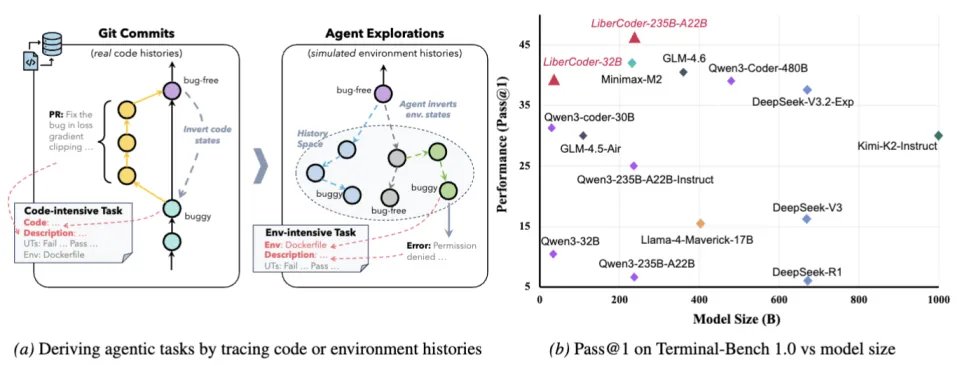
因此 CLI-Gym 来了!我们首先尝试用 Dockerfile 对环境进行结构化与可复现定义;进一步,将数据生产管线本身重新建模为一种 Agentic Coding 任务:在健康环境中驱动 Code Agent 执行环境反演(即 “劣化” 操作),自动生成问题环境及其准确的单元测试,从而实现问题实例与验证工具的自动化构造。我们在 29 个基础镜像上制造出 1655 个针对 Terminal-Bench 实例并产出 291 条高质量成功轨迹,我们的微调模型 LiberCoder 32B 和 235B 在 Terminal Bench 上分别实现了 + 28.6%(至 38.9%)和 + 21.1%(至 46.1%)的提升。
我们的管线创新性地以 Codebase、Dockerfile 与 Base Image 为核心抽象,完备地定义任意 CLI Coding 实体,使环境构建、问题生成与验证机制形成统一表达框架,具备良好的可组合性与通用性。我们希望这一范式能够进一步拓展至更多 Agentic Coding 场景,推动更通用的数据生产算法与基准构建方法的发展。

论文、代码和镜像数据均会在如下链接放出:
论文链接:https://arxiv.org/pdf/2602.10999
开源代码:https://github.com/LiberCoders/CLI-Gym
镜像数据:https://huggingface.co/datasets/LiberCoders/CLI-Gym
背景介绍
近年来,Agentic Coding 正在快速改变软件工程任务的解决方式,模型能力的边界正在从 “写代码” 逐渐扩展为 “解决真实软件系统中的复杂问题”。当前的研究重点还停留在以 SWE-bench 为核心的代码层面的研究,而在现实的软件工程和系统运维场景中,大量问题并非源于代码本身,而是来自运行环境,例如依赖版本冲突、环境变量错误、权限配置问题、系统库损坏、网络配置错误等。这类问题通常无法或很难通过修改代码修复,而必须依赖 agent 通过命令行理解系统状态,定位问题来源,并执行一系列系统级操作恢复环境运行状态。因此,对 agent 的环境理解与干预能力的要求越来越高。
Terminal-Bench 的任务恰好契合这一需求。其基准中包含大量以环境修复为核心目标的任务,对 agent 在 CLI 环境下的交互、诊断与修复能力提出了更高要求。然而,从当前官方 leaderboard 可以观察到,高性能方案往往依赖围绕强闭源模型构建的复杂 agent 框架,通过大量提示工程与多轮反思机制来弥补模型在环境理解与问题定位方面的能力不足。相比之下,围绕开源模型如何通过系统性训练提升其环境修复能力的研究仍然相当有限。
其根本瓶颈在于:环境密集型任务难以规模化生成。代码类问题可以通过挖掘仓库历史与 pull request 自动构建训练数据,但环境状态通常缺乏可追溯的演化记录,难以进行自动化重建与标注。这使得环境任务的数据长期依赖人工构造,规模难以扩展,也限制了模型在该方向上的持续训练与能力提升。
CLI-Gym 正是在这一背景下提出,旨在通过自动化机制突破环境依赖型任务数据难以规模化的问题,为 agent 能力训练提供可持续的数据来源。我们创新性地将数据生产管线本身重新建模为一种 Agentic Coding 任务:在健康环境中驱动 Code Agent 执行环境反演(即 “劣化” 操作),自动生成问题环境及其精确的单元测试,从而实现问题实例与验证机制的自动化构建。
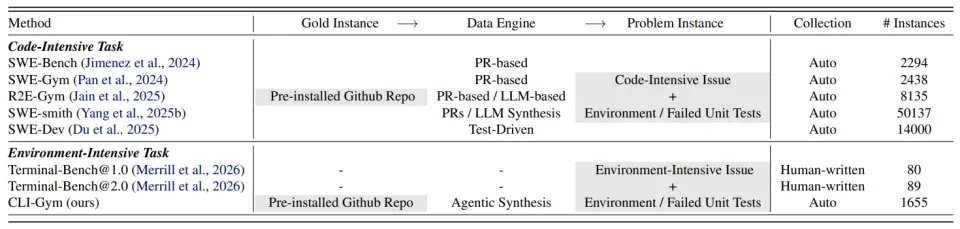
如上表所示,该建模思路具有良好的通用性,不仅适用于环境依赖型任务的构造,也在统一框架下涵盖了此前 SWE 系列方法的核心范式,实现了方法论层面的整合与扩展。
Pipeline:通过环境反演自动生成故障任务
CLI-Gym 的核心思想非常巧妙,通过模拟环境历史自动生成故障场景。与传统方法相反,我们不是从零构建受损环境,而是驱动一个 “破坏者” agent 主动篡改健康环境,制造多样化故障,再将其转化为可修复的任务实例。
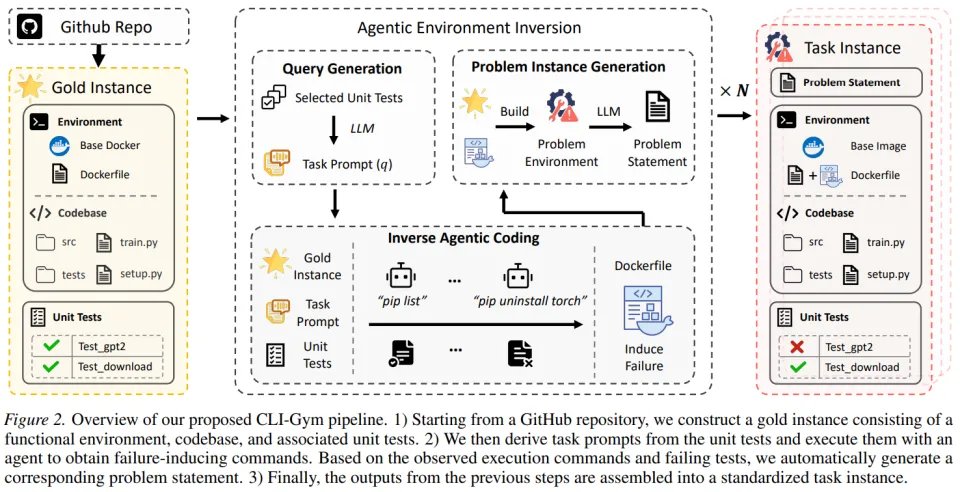
CLI-Gym 的核心思想在于重新思考任务生成方式:既然真实环境问题通常源于环境状态的错误,那么我们不再从零人工构造损坏环境,而是从健康环境出发,自动模拟环境如何被破坏,从而反向构造出可修复任务。这一思想被称为 “环境反演”,即通过 agent 将一个原本正常运行的环境主动破坏,使其回退到包含运行错误的状态,再将这一退化过程转换为 agent 需要修复的问题实例。在具体流程中,系统首先从真实开源仓库中构建包含健康环境的 Docker 镜像,该环境能够成功运行并通过全部单元测试,作为后续任务生成的起点。随后系统自动从 Unit Tests 中抽取目标 UT,通过语言模型生成诱导 agent 执行环境破坏的指令,例如删除关键依赖、篡改配置文件、破坏系统库、修改路径或权限等,agent 在执行过程中不断改变环境状态,使得部分测试失败,从而模拟真实系统退化或配置错误产生的历史过程。
当环境中出现失败测试后,系统根据失败日志、执行轨迹以及环境变更自动生成问题描述与修复目标,从而形成完整 CLI 任务实例,agent 的目标是通过命令行操作恢复环境,使失败测试重新通过。整个流程无需人工参与,从健康环境生成故障环境,再从故障环境构造修复任务,实现了环境问题的自动规模化生成。这一过程不仅能够模拟真实系统问题的产生方式,同时由于每次破坏路径不同,也带来了丰富多样的任务类型,使得生成任务覆盖软件工程、系统管理、安全调试等多个场景,显著提升训练数据的多样性与真实性。
产出:规模化与高质量的数据
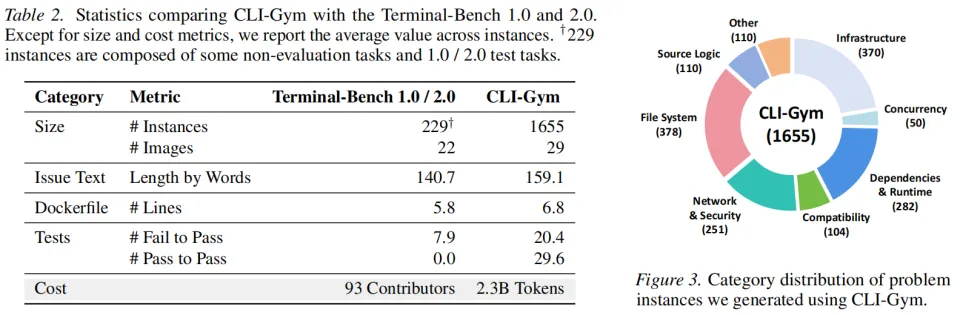
基于这一自动化 pipeline,CLI-Gym 在 29 个真实开源仓库中生成了 1,655 个环境密集型 CLI 任务实例,规模远超 Terminal-Bench 的人工构造数据,同时任务类型覆盖多个应用领域,展现出极强的可扩展性。与现有 benchmark 相比,这些任务具有更高复杂度,每个任务平均包含超过 20 个失败测试,为 agent 提供更丰富的诊断信号和修复反馈,使模型必须真正理解系统状态并执行多步操作才能完成修复,而不是通过简单代码修改或投机策略通过测试。此外,该流程完全自动化运行,仅消耗计算资源而无需人工标注,相比依赖大量工程师构造任务的传统方式大幅降低成本,使环境任务数据能够持续扩展。
在轨迹数据收集阶段,系统通过强模型运行这些自动生成任务,收集成功修复轨迹,并通过严格过滤机制排除过于简单或存在作弊路径的轨迹,仅保留真正体现复杂环境修复过程的数据,最终获得数百条高质量 agent 行为轨迹,用于后续模型训练。这些轨迹展示了丰富的修复策略,包括依赖恢复、系统配置调试、权限问题处理与环境组件修复等,为模型学习真实环境问题解决模式提供了宝贵监督信号。
实战效果:显著提升环境问题解决能力
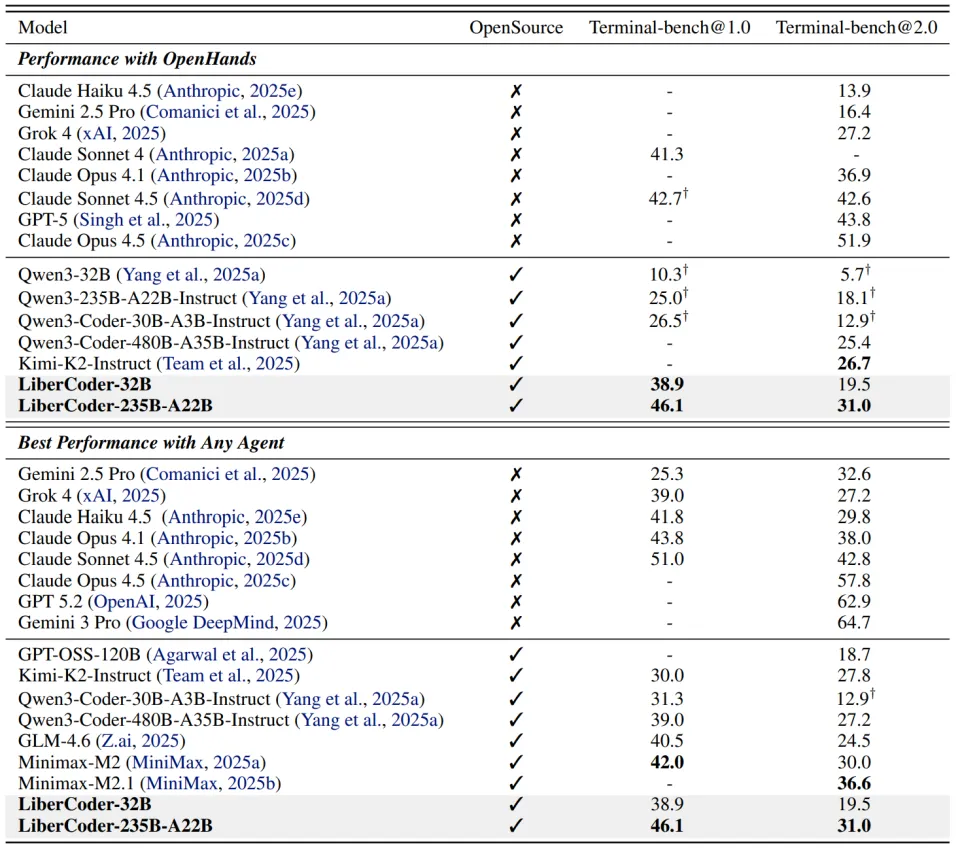
基于 CLI-Gym 生成的数据对 Qwen3 系列模型进行微调后,得到 LiberCoder 系列模型,在 Terminal-Bench 上取得显著性能提升。LiberCoder-32B 在 Terminal-Bench 1.0 上的 Pass@1 达到 38.9%,相比基础模型实现大幅提升,而规模更大的 LiberCoder-235B-A22B 达到 46.1%,超过大多数开源模型,并接近部分闭源模型性能。进一步分析发现,微调后的模型在环境问题处理能力上发生明显变化,模型不再频繁失败于编辑错误或问题定位,而更多受到上下文长度与执行时间等外部因素限制,说明其核心环境修复能力已经显著增强。同时在多个任务类别中均观察到一致提升,包括软件工程、系统管理、安全修复与调试任务,说明 CLI-Gym 数据并非针对单一场景优化,而是全面增强了模型在环境交互任务中的泛化能力。

结语
CLI-Gym 是第一种用于扩展 CLI 代理编码任务训练环境的公开方法。使用 Dockerfile 来表示每个环境,以进行精确的配置和版本控制,并使用 agent 来模拟环境历史。整理了 1655 个任务实例,收集了 291 个成功的轨迹。实验表明,对我们的数据进行微调可以大大增强以环境为中心的代理编码,从而在开源模型中在 Terminal Bench 上实现顶级性能。