ICLR 2026|FOCUS 关键帧提取:长视频理解能力提升11.9%,只需采样<2% 帧
本文第一作者朱子瑞为新加坡国立大学四年级博士生,本科毕业于清华大学,研究方向为多模态大模型和后训练优化。通讯作者为 TikTok 内容智能负责人 Kanchan Sarkar、Meta杨振恒博士(相关工作完成于其在 TikTok 任职期间)以及新加坡国立大学校长青年教授尤洋老师。
文章速览
长视频会使 MLLM 的视觉 token 规模快速增长,但推理阶段的计算与上下文预算有限,难以对全量帧进行处理。
现有关键帧方案通常还需先用 CLIP/BLIP 等视觉编码器全视频逐帧预扫描,即使最终只保留少量帧,前置计算成本依然很高。
本文提出 FOCUS:将关键帧选择建模为组合纯探索(CPE)多臂赌博机,以自适应的 “探索 — 利用” 策略在无需遍历全帧的前提下先锁定高价值时间段,再在段内精挑关键帧。
无需训练、即插即用:可直接接入现有 MLLM(如 GPT-4o 或 Qwen)的推理流程,不依赖特定模型结构与训练方式。
效果更强:在 >20 分钟 的长视频 VQA benchmark 设定下,FOCUS 选帧相较均匀抽帧可带来 11.9% 的性能提升。
成本更低:不依赖降采样等预过滤手段,平均只需观察 <2% 的帧即可达到上述收益,显著降低推理计算开销。

论文标题:FOCUS: Efficient Keyframe Selection for Long Video Understanding
论文链接:https://arxiv.org/abs/2510.27280
代码仓库:https://github.com/NUS-HPC-AI-Lab/FOCUS
背景:长视频理解为什么难?
长视频理解是多模态大模型(MLLM)中最为困难的问题之一。一段小时级、30fps 的标准视频往往包含十万量级以上的帧数。
对于主流 MLLM 而言,无论是先将视频帧编码为视觉 token、还是进一步进行跨模态交互建模,计算与上下文开销都会随帧数快速增长:“全量帧输入” 在绝大多数真实推理场景中并不现实。
因此,“挑选关键帧” 几乎是所有长视频系统的必经步骤。最常见的均匀抽帧(降采样)虽然能控成本,却容易错过集中在短片段中的决定性证据,导致模型在核心信息缺失的情况下 “盲答”。
现有关键帧方法大致分为两类:一类是 training-based,训练轻量选择器从全量帧中挑子集,但面临标注困难、组合爆炸带来的训练与工程成本,以及对下游模型结构 / 训练方式的依赖;另一类是 training-free 的检索式方案,用 CLIP、BLIP 等编码器计算 “帧 — 文本” 相关性再选帧。
后者虽免训练,却往往需要先对全视频逐帧预编码,面对小时级视频时单视频计算开销仍可能达到约FLOPs 量级,难以部署。
因此,我们需要一种更高效的选帧方式:在不牺牲准确性的前提下,避免对全视频逐帧预扫,降低推理代价,用尽可能少的观测帧数快速定位与 query 相关的高价值片段,真正满足现实系统的效率与可用性要求。
方法:FOCUS 的两阶段探索 - 利用
基于上述动机,本文提出 FOCUS,一个无需训练、可即插即用的关键帧选择算法。FOCUS 的核心思想是:将 “在预算内找到最有用的帧” 视为一个组合探索问题 —— 算法不必先看完整视频再做选择,而是可以通过少量试探性采样(探索)逐步缩小候选范围,再将预算集中到最有价值的区域(利用)。

具体而言,FOCUS 将关键帧选择建模为组合纯探索(CPE)的多臂赌博机问题,并采用两阶段的 coarse-to-fine 策略:
第一阶段:定位高价值时间段(粗粒度探索)。
我们把长视频切分为若干时间段,将每个时间段视作一个 “臂”。FOCUS 在有限预算下,对不同时间段进行自适应抽样:对 “可能与 query 更相关” 的时间段分配更多采样,对明显无关的时间段快速减少采样。通过维护每个时间段的估计收益与不确定性(置信界),算法可以在不遍历全视频的情况下,把注意力收敛到少量候选高价值时间段。
第二阶段:在段内精挑关键帧(细粒度利用)。
当候选时间段被锁定后,FOCUS 在这些时间段内部进一步选择帧:同样通过 “少量试探 + 置信驱动” 的方式,把帧预算集中到最相关的画面上,输出最终关键帧集合供下游 MLLM 推理。

FOCUS 的效率优势使其可以作为一个前置模块,直接插入现有 MLLM 推理 pipeline,在不同模型、不同任务上复用。
实验:即插即用的长视频理解利器
为了验证 FOCUS 的通用性与有效性,作者在四个公开视频问答(Video QA)基准上进行了评测,并选择了四种常用的 MLLM 作为下游推理模型,包括 GPT-4o、Qwen2-VL、LLaVA-OV、LLaVA-Video 等。
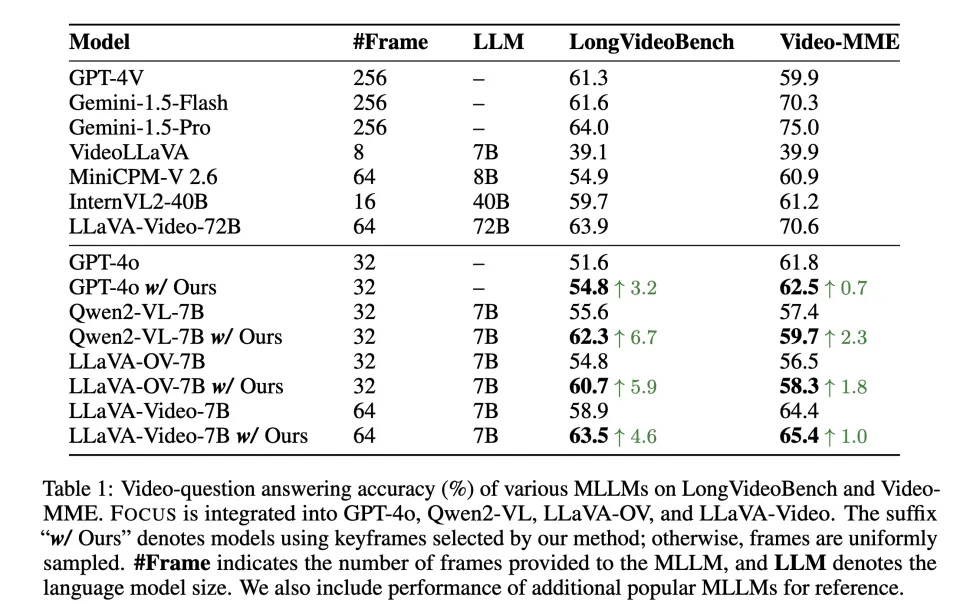

作者进一步地将 FOCUS 与目前最有代表性的关键帧选择方法进行了对比。
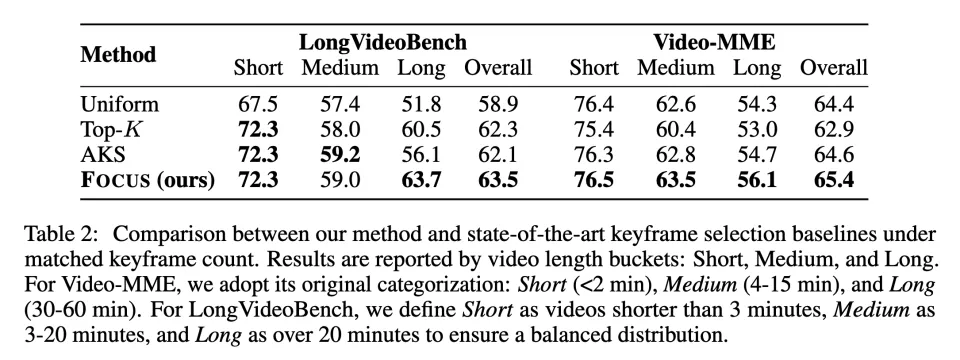
结果表明:在长视频场景(例如 >20 分钟 的设定)下,FOCUS 相比均匀抽帧带来最高 11.9% 的性能提升。同时,FOCUS 在不依赖降采样等预过滤手段的情况下,平均仅需观察 <2% 的帧即可达到上述收益,显著降低了关键帧选择与推理阶段的总体计算开销。
分析:高效定位视频关键信息
1. 可视化:FOCUS 能更精准地找到与 query 相关的证据片段
作者对若干典型样例进行可视化分析:在长视频中,FOCUS 通过两阶段探索快速将注意力收敛到少量高价值片段,再在片段内部挑出证据帧,使得输入给 MLLM 的帧更 “信息密集”,从而提升回答质量。

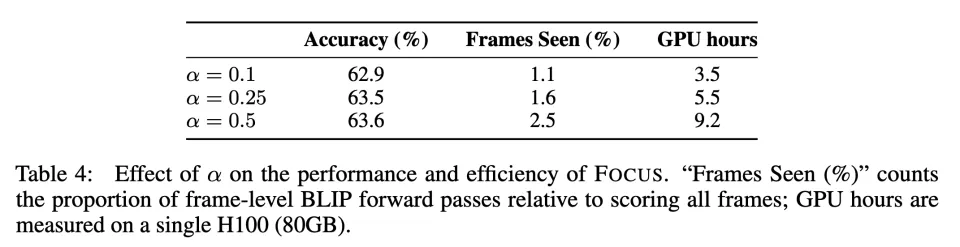
2. 效率提升:相比全帧预扫的选帧范式,FOCUS 的端到端开销更可控
FOCUS 的效率优势在于:它的选择过程本身就是省帧的,能够在探索阶段动态跳过大量无关区域,避免将计算预算花在 “无用的全量预扫” 上,相对于基线方法大大降低推理开销。

同时 FOCUS 提供了清晰的预算控制接口:当系统更关注性能时,可以适当增加探索预算;当系统更关注吞吐 / 延迟时,可以通过调整超参数收紧预算。
总结
长视频理解的核心难点在于:视觉 token 随帧数快速膨胀,均匀抽帧又容易漏掉关键证据;而现有关键帧方法存在着训练代价高、依赖模型结构的问题,或者虽免训练仍需全帧预编码,难以满足真实系统的效率要求。
FOCUS 将选帧建模为组合纯探索,通过两阶段 “探索 — 利用” 在不遍历全帧的情况下定位与 query 相关的高价值片段;平均仅观察 <2% 帧即可在长视频设定下带来最高 +11.9% 的准确率提升。它可作为即插即用的推理组件,为 MLLM 长视频应用提供更可控的成本与表现。