大模型的第一性原理:(三)信息论篇
白铂 博士 华为 2012 实验室理论研究部主任 信息论首席科学家
引言
在本系列的第二篇《信号处理篇》中,我们引入了一些信息论的概念和方法来理解语义嵌入/向量化。本篇将完全从信息论的角度出发,深入解读原论文,探讨大模型背后的第一性原理¹。
1948 年,Shannon 发表了题为 A Mathematical Theory of Communication 的划时代论文,奠定了现代数字通信的理论基础,推动了人类迈向信息时代²。论文的主要目标是用数学方法解决有噪声的数字通信系统的可靠传输问题。以此为起点,Shannon 及后来的专家学者建立了一套完备的数学框架与理论体系,这便是后来众所周知的信息论。1949 年,Weaver 与 Shannon 合著了一篇论文,文中明确将通信问题分为三个层级³:
Level-A(技术问题): 通信符号能在多大程度上被准确地传输?
Level-B(语义问题): 传输的符号能在多大程度上精确传达了预期的含义?
Level-C(效用问题): 接收到的含义能在多大程度上有效地影响行为,使其符合预期? Shannon 曾表示,他的理论仅仅解决了可靠通信问题,即 Level-A(技术问题)。这是因为在 Shannon 的理论中,信息和不确定性是等价的,并不关注消息的含义或内容。
受到 Shannon 方法论的启发,本文尝试从推理的视角出发探讨大模型的可解释理论。我们发现,只要将 Shannon 的理论从以 BIT 为中心转换为以 TOKEN 为中心,便可以从信息论的视角完全解释大模型的底层原理,该理论在原论文中被称为语义信息论(Semantic Information Theory)。
Shannon 信息论
本节先归纳一下 Shannon 的主要结论和方法论启示。下图是一般通信系统的原理图。
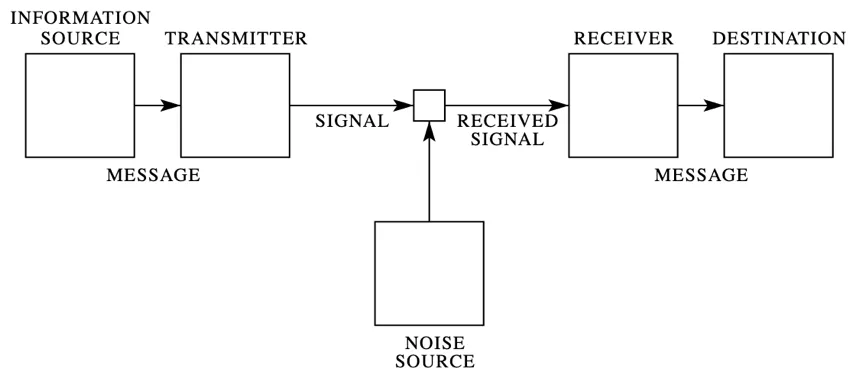
图:一般通信系统原理图⁴。
信息论的三个主要结论
在通信系统中,信源是产生信息的源头。信源编码器将每一个信源符号映射为一个长度为 m 的二进制码字,从而实现对原始信息的压缩,节约宝贵的信道资源,提升效率。如果信源的输出是一个随机变量 S 的独立采样,Shannon 证明这类信源所产生的信息量就是 S 的熵(Entropy)。用 P(S) 表示 S 的概率分布,那么 S 的熵定义为:
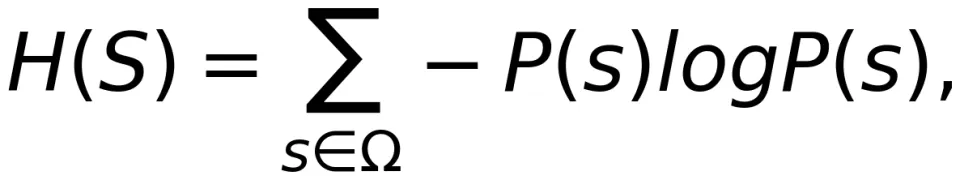
其中 Ω 为随机变量 S 的样本空间,在信息论中通常称为符号集或字符集。熵是信源无损压缩(即能够完美恢复信源符号的压缩)的可达下界。这个结论就是著名的信源编码定理。
由于信道会受到噪声的影响,如果直接传输信源符号,接收的符号就会出现错误。如何实现可靠的数字通信,是当时任何工程方案都无法解决的世界难题。但 Shannon 通过他的理论不仅告诉我们可靠通信完全可以实现,而且还给出了数学上最优的解决路径。他首先创造性地用转移概率来建模通信信道,即
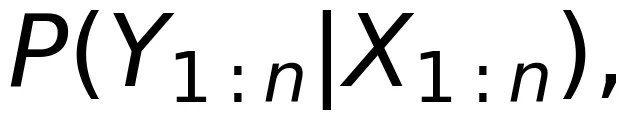
其中 是信道的输入序列(即发射机的输出序列),
是信道的输出序列(即接收机的输入序列)。进一步地,他引入信道编码以对抗信道噪声带来的传输错误。同时,接收机采用最大似然译码来恢复发送的符号,从而在给定速率的前提下最小化了差错概率 P_e。假设 S 的样本空间包含 M 个符号,那么通信速率就定义为:
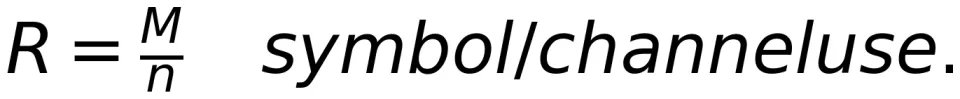
离散无记忆信道(Discrete Memoryless Channel,DMC)是一类应用广泛的信道模型。一般认为,它的转移概率满足以下关系⁵:

Shannon 证明了对于 DMC,通信速率 R 的可达上界是下式给出的信道容量:
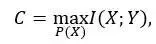
其中 P(X) 是 X 的概率分布,I (X;Y) 是互信息(Mutual Information),定义为:
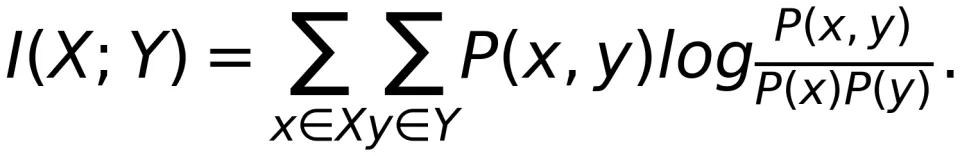
如果 R<C,那么一定存在一种信道编码使得码长 n→∞时通信系统的差错概率 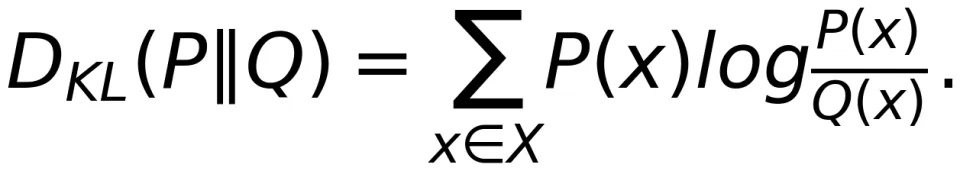 。这个结论就是著名的噪声信道编码定理。可以看到,信道容量 C 是互信息 I (X;Y) 在优化 P (X) 时可以达到的最大值。此时,最优的 P*(X) 是信道输入的最优概率分布,也是最优信道编码应该满足的概率条件。后面将会看到,正是对 DMC 定义的不同理解,才导出了从信息论出发理解大模型的核心概念 —— 定向信息(Directed Information)。
。这个结论就是著名的噪声信道编码定理。可以看到,信道容量 C 是互信息 I (X;Y) 在优化 P (X) 时可以达到的最大值。此时,最优的 P*(X) 是信道输入的最优概率分布,也是最优信道编码应该满足的概率条件。后面将会看到,正是对 DMC 定义的不同理解,才导出了从信息论出发理解大模型的核心概念 —— 定向信息(Directed Information)。
Shannon 的第三个伟大贡献在于证明了信源-信道分离定理,即把一个通信系统分解成信源编解码和信道编解码两个主要组成部分在理论上是最优的。这种分离设计极大地降低了工程实现的难度,并给实际应用带来了诸多便利。自此,通信技术就分成信源和信道两个领域。从事一个领域理论研究和工程实现的人并不需要了解另一个领域在做什么。可以说,Shannon 的信源-信道分离定理让世界同时产生了两个全新的科学和工程领域。
方法论启示
Shannon 是用数学理论解决工程技术难题(即以数学补物理)的典范。他最值得称道的方法论是在解决可靠通信问题时,没有陷入具体实现方案的比较和技术路线的选择,而是回归到一个基本的思想实验:如果一个可靠通信系统真的被造出来了,它应该具备什么功能、应该满足何种数学性质?这是一种自顶向下的方法论,即从运行时的视角来研究实现可靠信息传输的数学条件,从而指导通信系统设计。
针对信道编解码部分,我认为 Shannon 在论文中回答了以下三个关键问题:
1. 在数字通信中,可靠的数学定义是什么?
Shannon 的答案是渐进无差错的信息传输,他将概率论和统计学引入了通信领域,进而导出差错概率及其指数界、最大似然译码、联合典型译码等一系列概念和方法。
2. 可靠通信的数学模型是什么?
Shannon 的答案是用转移概率来建模信道,这一点十分关键,因为无论是已存在的通信系统还是人们当前尚未想到的通信技术,都可以用转移概率来建模信道不确定性带来的影响。这种概率模型与具体实现无关,具有极大的普适性。
在数学上,这类方法被称为概率方法⁶。但 Shannon 的天才在于把这种并不复杂的数学技巧完美应用于解决工程问题。
3. 衡量通信系统的性能指标是什么?
Shannon 的答案是可靠通信速率用互信息和信道容量来衡量。互信息本质上是用更基础的 Kullback-Leibler(KL)散度衡量 P (X,Y) 和 P (X) P (Y) 之间的差异,从而刻画 X 和 Y 之间的统计相关性。如果找到一个 P (X) 使得上述统计相关性最大,那么互信息 I (X;Y) 就达到了信道容量 C。
KL 散度是信息论中的一个基本概念,其定义为
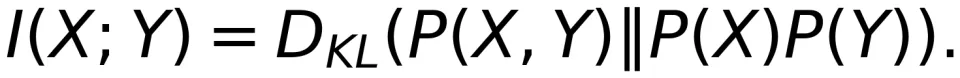
这样互信息可表示为
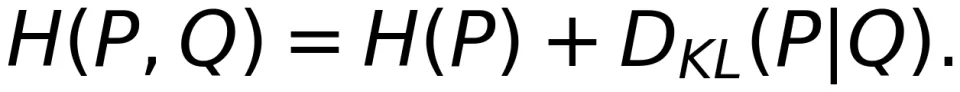
机器学习领域常用的交叉熵损失函数可表示为
如果 H (P) 给定,那么交叉熵和 KL 散度是等价的。
大模型的信息论抽象
信息论从运行时的视角出发来研究通信系统,对研究大模型的第一性原理极具启发性。因为我们期望给大模型建立与具体实现无关的数学模型和理论。即便人们未来发明出比 Transformer 更好的架构,该理论仍然具有指导意义。事实上,2024 年图灵奖得主 Richard Sutton 在提出 Oak 架构时也认为走向 AGI 必须区分设计时和运行时⁷。
类似 Shannon 解决可靠通信问题的思路,我们也可以对大模型提出以下三个基本问题:
对大模型而言,语义意味着什么?
大模型与具体实现方式无关的数学模型是什么?
衡量大模型性能的指标是什么? 第一个问题实际上在本系列的第二篇《信号处理篇》中已经回答了,这里不再赘述。本篇的后续部分将着重回答第二和第三个问题。
面向大模型的信息论测度
为方便讨论,本节将首先介绍面向大模型的信息论测度,包括速率 - 失真函数、定向信息和定向信息密度。
1、速率-失真函数
在实际场景中,有损压缩(即仅能近似恢复信源符号的压缩)有非常广泛的应用,如图像、视频和音频等。Shannon 提出用速率-失真函数来刻画有损压缩的端到端性能⁸。具体来说,要确定一个最小速率 R bit/symbol,使得信源符号可以在解压缩时被近似重构,且预期失真度不超过 D。定义衡量失真度的非负函数 ,其中
是信源输出序列,而
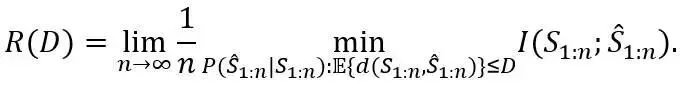 是有损压缩后恢复的序列。那么,速率-失真函数定义为:
是有损压缩后恢复的序列。那么,速率-失真函数定义为:
根据 Shannon 的方法论,该定义将有损压缩和解压缩的过程抽象成转移概率 。上述定义就是在满足预期失真度约束的前提下,寻找最优的转移概率,使得恢复后的序列与信源序列之间的统计相关性最小。
值得注意的是,速率-失真函数的核心是互信息 而不是
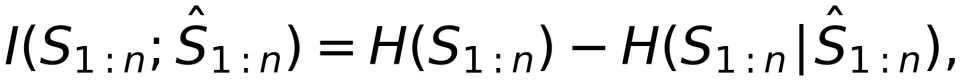 。根据信息论恒等式
。根据信息论恒等式
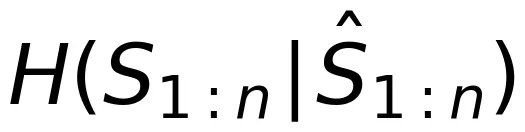
其中 表示已知
时
剩余的不确定性,它与恢复满足失真度约束的
无关。因此,我们只需要知道
中和
统计相关的部分就足够了,从而在速率-失真函数中应用互信息
是合理的选择。另一方面,
是重构
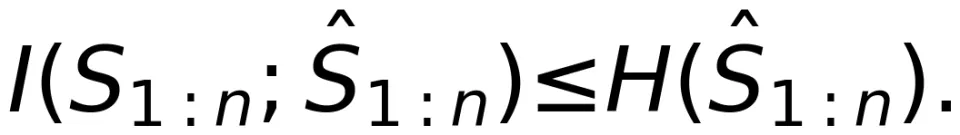 所需的最小信息量,这是无损压缩的目标而非有损压缩的目的,并且有
所需的最小信息量,这是无损压缩的目标而非有损压缩的目的,并且有
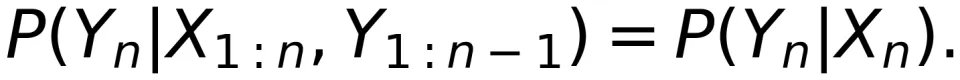
由于压缩的损失与信道噪声的影响很相似,所以面向有损压缩的速率 - 失真函数理论与信道编码的逻辑很相似。有关该理论的系统论述,可参阅 2002 年香农奖得主 Toby Berger 的经典著作⁹。
在实际应用中,直接计算速率-失真函数是非常困难的。Blahut-Arimoto(BA)算法是解决该问题的经典交替迭代算法¹⁰ ¹¹。近期,我们还提出了基于最优传输理论的算法以提升速率-失真函数的计算效率¹²。
2、定向信息
在本系列的第二篇《信号处理篇》中,为了讨论信息论意义下最优的语义嵌入 / 向量化,我们引入了定向信息和倒向定向信息。这里我们将展开讨论定向信息提出的背景和意义。
定向信息是由著名信息论专家,1988 年香农奖得主,James Massey 提出¹³。他在 1990 年的论文中指出:Ash 的信息论专著中关于 DMC 的定义是有问题的,因为该定义天然不能包含反馈¹⁴。他同时还认为,在 IEEE ISIT '73 会议上,Shannon 之所以选择反馈作为首次 Shannon Lecture 的主题,或许正是因为信息论在处理带有反馈的系统中并未取得显著的成果。
Massey 认为离散无记忆信道(Massey-DMC)的转移概率应该满足:
上式表明,信道的输出 与信道的输入
和时刻 n 之前的信道输出
并无关系,即信道没有记住
和
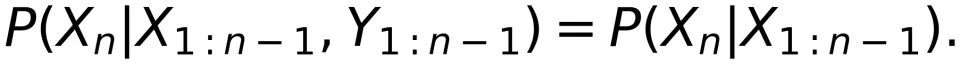 的任何部分。Massey 进一步指出,如果离散信道是无反馈(Discrete Non-Feedback Channel,Massey-DNFC)的,那么信道转移概率应该满足:
的任何部分。Massey 进一步指出,如果离散信道是无反馈(Discrete Non-Feedback Channel,Massey-DNFC)的,那么信道转移概率应该满足:
上式表明,信道在时刻 n 的输入 只和之前的输入序列
有关,而和信道的输出序列
无关。换言之,信道的输出序列没有任何部分反馈到输入以改变
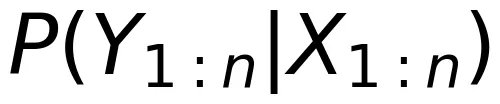 。Massey 进一步证明:只有信道转移概率
。Massey 进一步证明:只有信道转移概率  同时满足以上两个条件,才能得到 Ash 在教科书中给出的 DMC 定义(Ash-DMC),即
同时满足以上两个条件,才能得到 Ash 在教科书中给出的 DMC 定义(Ash-DMC),即
从信道容量的讨论可以看出,互信息 I (X;Y) 描述了 Ash-DMC 的输入序列和输出序列之间的统计相关性,但却无法适用于 Massey-DMC 信道。基于 Marko 在双向通信问题中的研究¹⁵,Massey 提出用定向信息来描述 Massey-DMC 的端到端统计相关性。具体来说,从输入序列 到输出序列
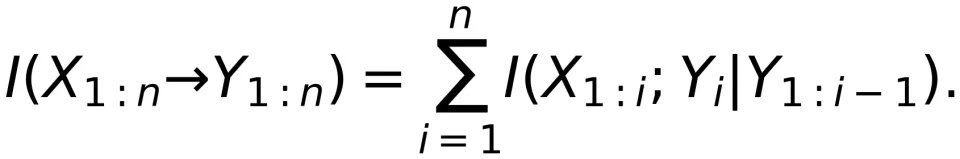 的定向信息定义为:
的定向信息定义为:
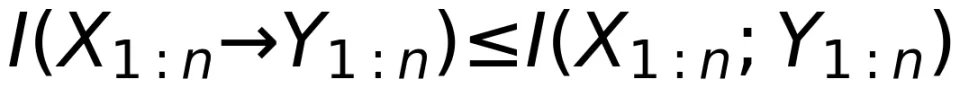
Massey 证明了定向信息有以下基本性质:
定理 1:
,其中
和
![]() 分别是离散信道的输入和输出,当且仅当该信道是 Massey-DNFC 时等号成立。
分别是离散信道的输入和输出,当且仅当该信道是 Massey-DNFC 时等号成立。定理 2:
,其中
和
分别是 Massey-DMC 的输入和输出,当且仅当
![]() 是独立同分布的序列时等号成立。
是独立同分布的序列时等号成立。Massey 在论文中也详细探讨了通信系统中的因果问题。如果一个通信系统是因果的,则信道转移概率应满足:
其中
是信源的输出。这个定义的主旨在于,信源输出序列
应在经由信道传输之前即已确定,而信道仅能感知其输入
和输出
![]() 。上述因果的定义,我们称之为 Massey 因果。紧接着,Massey 给出了定向信息的第三个性质:
。上述因果的定义,我们称之为 Massey 因果。紧接着,Massey 给出了定向信息的第三个性质:定理 3:
,其中
和
分别是 Massey 因果离散信道的输入和输出,
![]() 是信源输出序列。 由定理 2 和定理 3 可以得到
是信源输出序列。 由定理 2 和定理 3 可以得到![]()
从而,我们可以导出信息论中的一个著名的反直觉结论:反馈并不能增加信道容量。
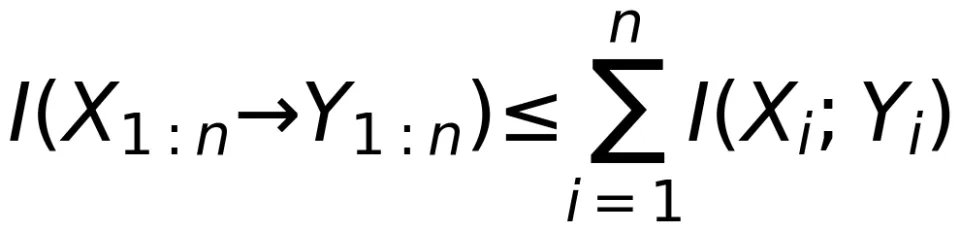
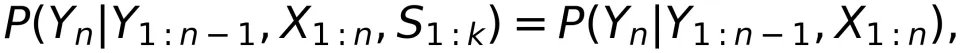
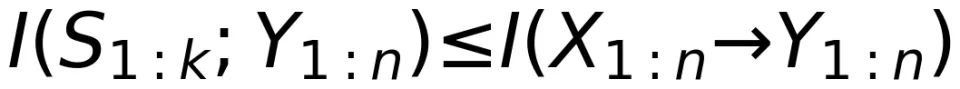

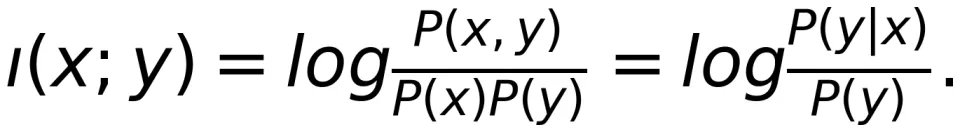
以上讨论表明,定向信息能够突破互信息的局限性,描述更广泛信道的输入和输出之间的统计相关性。然而遗憾的是,后续的信息论教材并未采纳 Massey 的修正建议。这使得信息论研究长期聚焦于不能纳入反馈的 Ash-DMC 定义,而定向信息则未得到足够重视。关于定向信息更详细的研究和更广泛的应用,可参考 Massey 的学生 Kramer 的博士论文和综述论文¹⁶ ¹⁷。
3、定向信息密度
信息密度的概念最早由前苏联数学家、信息论专家 Roland Dobrushin 于 1959 年提出¹⁸。还有一种说法认为信息密度是另一位著名的前苏联信息论专家 Mark Pinsker 在更早的一本书中提出的,但我尚未找到这本书。以 Strassen 矩阵乘法闻名于世的 Volker Strassen 在 1962 年给出了信息密度的首个理论分析结果¹⁹。具体来说,信息密度ı(x;y) 定义为:

信息密度是一个随机变量,它的数学期望是互信息:
近年来,信息密度已广泛应用于有限码长下的信息论问题²⁰。
类似地,我们定义从 到
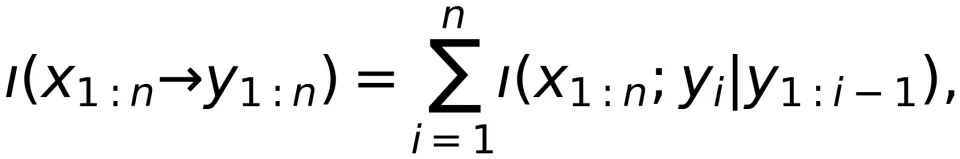 的定向信息密度如下:
的定向信息密度如下:
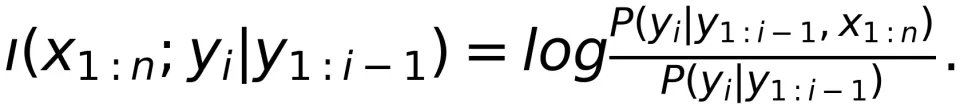
其中
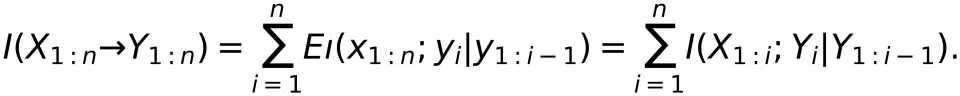
显然,定向信息密度也是一个随机变量,并且有

大模型是有状态、带反馈的信道
图:大模型是有状态、带反馈的信道
如图所示,考虑输入的 Token 序列为 ,其中 1≤n<i≤N 且 n∈N。通过语义编码模块 f 映射到语义向量序列
。大模型基于输入
和之前生成的 Token 序列的向量表示
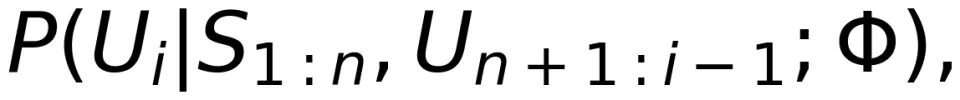 来生成下一个 Token 的向量表示
来生成下一个 Token 的向量表示 。因此,大模型可以建模为一个有参数的转移概率:
其中 Φ 表示大模型的参数。φ 是语义解码模块,即 f 的逆映射,把 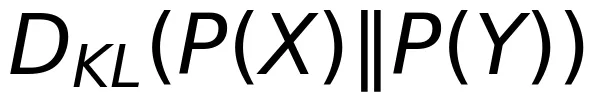 映射为对应的 Token 输出
映射为对应的 Token 输出 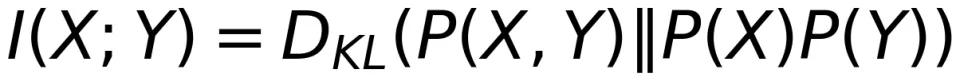 。从信息论的角度看,大模型本质上就是有状态、带反馈的信道。可以看到,这样的概率模型与具体实现无关,因而对其研究具有极大的普适意义,可以指导设计全新的大模型结构。从信息论的角度看,通信问题与大模型问题的区别与联系在于:
。从信息论的角度看,大模型本质上就是有状态、带反馈的信道。可以看到,这样的概率模型与具体实现无关,因而对其研究具有极大的普适意义,可以指导设计全新的大模型结构。从信息论的角度看,通信问题与大模型问题的区别与联系在于:
通信问题:通信的目的是为了在接收端无差错的恢复发送的信息。在实际通信过程中,不能直接计算
,因为接收机不可能事先知道发射机会发送什么信息,否则就不需要通信了。为了解决该问题,Shannon 天才地引入了互信息,
,以刻画 X,Y 的联合分布偏离统计独立的程度,即 X,Y 的统计相关性。显然,X 和 Y 的相关性越强,Y 中蕴含 X 的信息越多,从 Y 恢复 X 就越容易。当通过调整 P(X) 使得统计相关性达到最大时,即达到了该信道的 Shannon 容量。如果用 AI 的语言,通信问题的损失函数就是基于 KL 散度定义的互信息。
大模型问题:大模型的目的是为了建模人类对特定输入 Token 序列
产生的输出 Token 序列
。通过对数据进行标注,KL 散度可直接作用于
的概率分布和人类的标注分布,从而使大模型学会人类对特定输入序列产生的输出序列。在实际应用中,由于训练数据的熵是固定的且没有必要计算,通常大模型使用与 KL 散度等价的交叉熵作为损失函数。 以上讨论也进一步印证了本文开篇提出的核心观点:只要将 Shannon 的理论从以 BIT 为中心转换为以 TOKEN 为中心,便可以从信息论的视角完全解释大模型的底层原理。
训练阶段的语义信息论原理
大模型本质上是一个有状态、带反馈的信道,从 到
的定向信息衡量了语义信息在大模型内的流动。令
表示人类对输入
的输出 Token 序列。进一步地,分别用
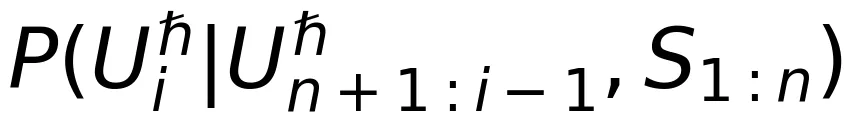 和
和 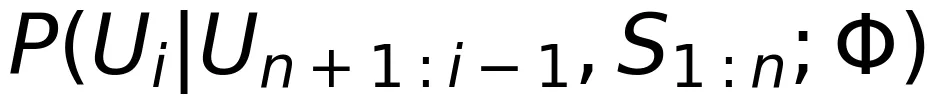 表示
表示 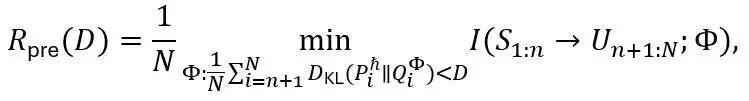 和
和 ,其中 i=n+1,…,N。大模型预训练阶段的定向速率-失真函数定义为
其中从 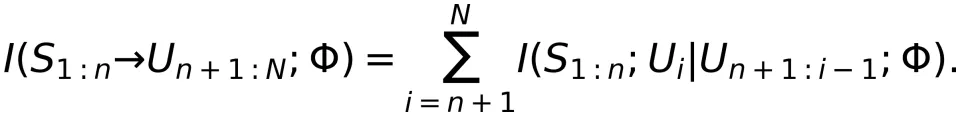 到
到 的定向信息可展开为
为表述方便,该定义中仍使用 KL 散度作为损失函数。 定义了预训练阶段输入到输出的端到端性能指标,其特点如下:
描述了从输入序列
生成输出序列
所需的最小信息量,其中
距离人类期望输出的失真不超过 D。显然,
![]() 随着预训练过程的变化曲线将揭示大模型的关键特性。
随着预训练过程的变化曲线将揭示大模型的关键特性。![]() 中最小化定向信息将过滤掉对产生输出序列无用的信息,从而有助于消除幻觉。因此,我们建议在大模型预训练中使用以下的损失函数:
中最小化定向信息将过滤掉对产生输出序列无用的信息,从而有助于消除幻觉。因此,我们建议在大模型预训练中使用以下的损失函数:![]()
其中 λ 是 Lagrange 乘子。 简单的数学推导还可以证明当训练理想收敛时:
因此,在理想收敛时,大模型在预训练阶段逼近
,即从
![]() 到
到 ![]() 的定向信息将逼近人类水平。
的定向信息将逼近人类水平。

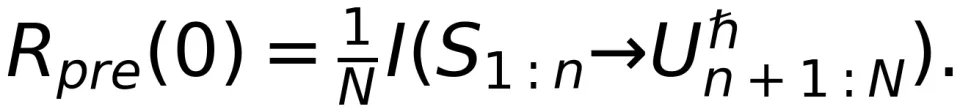
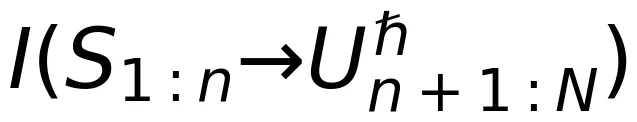
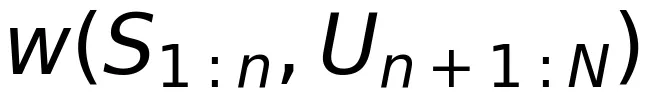
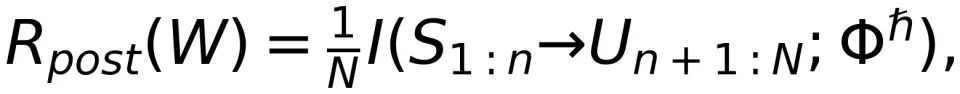
经过预训练的大模型,产生的输出序列不一定符合人类的偏好。因此,后训练通过强化学习或监督微调技术来牵引生成更符合人类偏好的序列。在基于强化学习的后训练方法中,要引入一个奖励函数 给大模型的输出打分。类似于定向速率 - 失真函数,我们在后训练阶段定义奖励-失真函数:
其中后训练的最优解用 表示。
定义了后训练阶段连接输入到输出的端到端性能指标,其特点如下:
描述了从输入序列
生成输出序列
所需的最小信息量,其中
的人类偏好奖励大于 W。
中最小化定向信息将过滤掉对符合人类偏好无用的信息,从而使得基于参数
![]() 生成的序列
生成的序列 更符合人类偏好。因此,我们建议在大模型后训练中使用以下的损失函数:
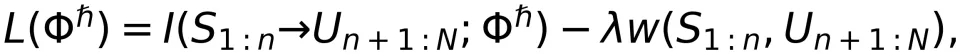
其中 λ 是 Lagrange 乘子。事实上, 等价于 Direct Preference Optimization(DPO)算法中的损失函数 。
推理阶段的语义信息论原理
在推理阶段,基于参数 和输入 Token 序列
,大模型生成 Token 序列
。不同于训练阶段关注大模型在训练集上的平均性能,推理阶段则关注特定输入序列下的特定输出序列。令
和
分别表示
和
的样本向量,基于定向信息密度可定义从
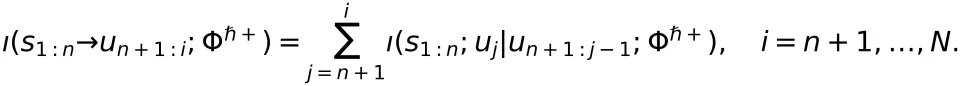 到
到 的单次推理语义信息流:
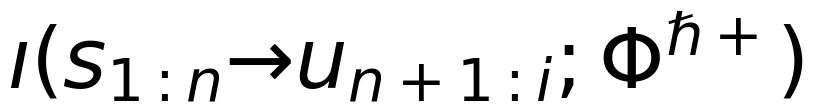
推理阶段停止于预测到下一个 Token 是停止符号⊲。因此,输出 Token 序列的长度 N 是关于随机事件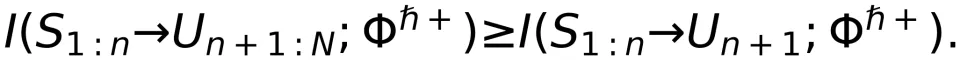 的停时。由此可以证明,语义信息流有以下性质:
的停时。由此可以证明,语义信息流有以下性质:
性质 1:
![]() 是一个具有 Markov 性的下鞅。
是一个具有 Markov 性的下鞅。性质 2:根据 Doob 的鞅停时定理 ,我们有
上式说明,当推理结束时,输入到输出的定向信息不小于只输出第一个 Token 的定向信息。这显然符合我们的直观理解。
性质 3:根据下鞅的 Freedman 不等式,对于 α,β>0,我们有
![]()
其中,
是鞅
![]()
是可预测的单调不减过程
![]()
![]() 是鞅差的条件方差,即
是鞅差的条件方差,即上述结论表明,虽然 Token 序列的概率分布非常复杂,且难以处理长程相关性,但定向信息密度具有非常好的数学性质,可以通过许多现代数学工具加以研究。
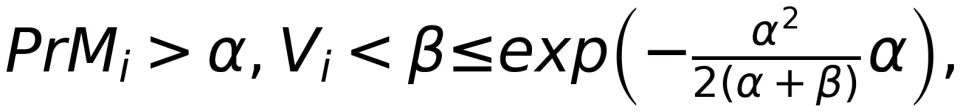
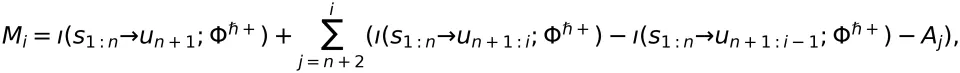
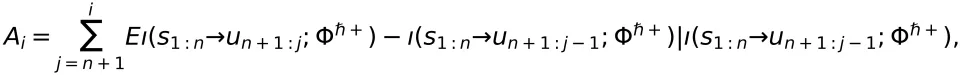
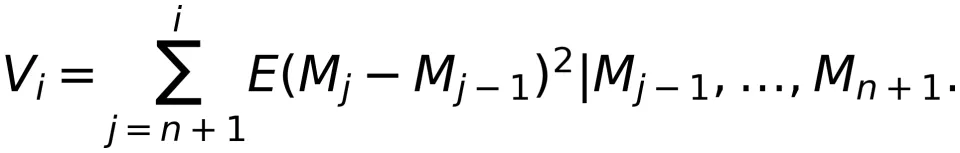
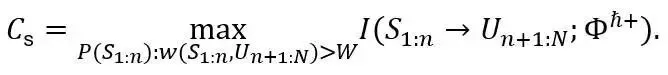
当前评估大模型推理性能的主要方式仍然是在大量测试集上评价推理结果所达到的分数。这种评测本质上是评估推理的平均效果。因此,借鉴 Shannon 定义信道容量的思想,可类似定义大模型推理的语义信息容量:
该定义说明,在推理阶段通过调整输入 Token 序列的概率分布 ,可最大化满足人类偏好的定向信息。这本质上就是通过上下文工程(过去称为提示词工程)提高大模型回答质量的信息论原理。
定向信息的计算和估计
在实际应用中,定向信息的计算和估计是很困难的。在数值算法方面,Haim Permuter 与他的合作者提出将经典的 BA 算法推广到计算定向信息²³。这篇论文利用了输入分布的凹性和定向信息的因果结构,并结合动态规划原理,提出了面向定向信息的 BA 算法。
基于互信息的 Donsker-Varadhan 表示²⁴,Belghazi 等人在互信息神经估计器(Mutual Information Neural Estimator,MINE)取得重要进展²⁵。受此启发,Permuter 及其合作者进一步提出了基于 RNN 的定向信息神经估计器(Directed Information Neural Estimator,DINE)²⁶。更进一步地,他们最近的工作则提出 Transformer 本身就可以用来估计传递熵(TRansfer Entropy Estimation via Transformers,TREET),即有限长度版本的定向信息²⁷。TREET 将传递熵的估计问题转化为一个离散序列的自回归预测问题,利用 Transformer 的上下文学习能力来精确计算条件概率的对数似然差。从这个角度看,Transformer 和定向信息是天然结合在一起的。
Granger 因果与 Pearl 因果
在本系列的第一篇《统计物理篇》和第二篇《信号处理篇》中,我们都指出:大模型推理的本质,是通过预测下一个 Token 这一看似简单的训练目标,实现逼近人类水平的 Granger 因果推断。
Granger 因果是由 2003 年诺贝尔经济学奖得主 Clive Granger 提出的。令 Ui 表示整个宇宙在时刻 i 的所有知识, 则表示一个经过修改的宇宙在时刻 i 的所有知识,这里的 “修改” 指的是排除了
这个时间序列。称
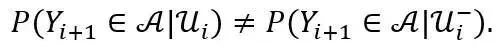 引起了
引起了 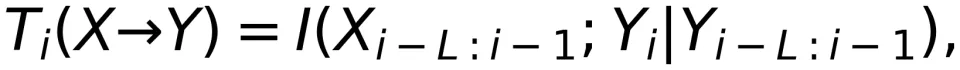 ,如果
,如果
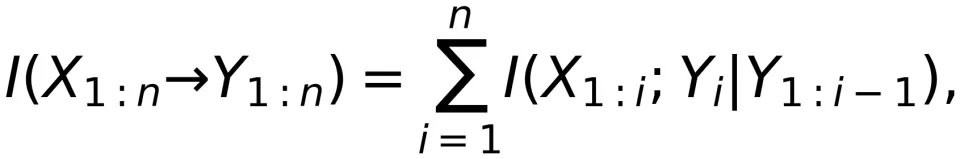
这个定义是非常普适的,但没有可操作性。为了用信息论测度来衡量两个时间序列的 Granger 因果性,物理学界提出了传递熵的概念²⁸。从序列 X_(1:n) 到序列 Y_(1:n) 的传递熵定义为
其中 L 为相互影响的长度。后续的相关研究则进一步印证:对于向量高斯自回归过程,传递熵和 Granger 因果是等价的²⁹。回忆定向信息的定义:
可见,传递熵是有限长度版本的定向信息。关于 Granger 因果和定向信息的详细讨论可参阅综述论文³⁰。
机器学习领域的著名专家,2011 年图灵奖得主,Judth Pearl 教授曾严厉批评 Granger 因果,认为它混淆了因果的定义,给这一领域带来了误导。在 Pearl 看来,Granger 因果并非本质上的因果关系,而是属于具有时间顺序的统计。进一步地,Pearl 认为没有模型假设的数据,永远无法推导出真正的因果结论。可以这样概括两种因果概念如下:
Granger 因果在哲学上属于经验主义,关注的是数据驱动的预测;
Pearl 因果在哲学上属于结构主义,关注的是模型假设下的干预和反事实。
具体来说,Pearl 因果分为三个层级:
Level-A(关联问题):从数据中观察 X 和 Y 是否有关联,即 P(Y∣X).
Level-B(干预问题):执行 do(⋅) 算子,观察干预 X 后 Y 的情况,即 P (Y∣do(X)).
Level-C(反事实问题):观察到事件 {X=x,Y=y} 后,强行假设 x' 发生时 Y 的情况,即P (Y_(x' )∣X=x,Y=y).
Pearl 证明:仅凭较低层级的信息,无法推导出较高层级问题的答案,除非引入额外的、不可从数据中识别的因果假设³¹ ³²。容易看出,Granger 因果属于 Level-A(关联问题),但定义了时序关系,因此是数据驱动的预测能力极限。根据 Pearl 的定理,如果大模型只在 Level-A 的语料上训练,则永远无法做出 Level-B/C 的推理。
随着强化学习和 Mote Carlo 树搜索等算法与大模型相结合³³ ³⁴,大模型的推理能力得到了显著提升。然而本质上,这类算法是在模型固定的前提下,极致模仿人类语料中的干预问题和反事实问题。简言之,大模型可以写出非常像干预和反事实的句子,因为它模仿了人类的语言模式。但这只是大模型在做数据驱动的预测,而不是真正进行因果推理³⁵。从另一个角度看,当前人类与大模型互动的价值,正是引入了不可从数据中识别的因果假设,从而将大模型作为工具来大幅提升人们的工作效率。
结语:一个新时代的开始
本篇是系列解读文章的最后一篇,它围绕 TOKEN 为大模型建立语义信息论框架。在这里我要解释一下,原论文的题目叫 Forget BIT, It is All about TOKEN 没有丝毫贬低 BIT 的意思。事实上,我始终认为信息时代最伟大的发明就是 BIT。这是 2023 年初我和 5G Polar 码发明人、2019 年香农奖得主,Erdal Arikan 教授的圆桌论坛上,他在回答吴博士的问题时提出的核心观点。这一观点启发我一直思考 AI 时代的核心概念 —— 和 BIT 同等重要的概念 —— 到底是什么?BIT 连接了计算和通信,两个理论基础和哲学理念完全不同,却又相互促进、相互限制的学科。我现在坚信 Kolmogorov 的观点是对的:信息论不应该建立在概率论的基础上,信息论比概率论更加基础,它和 Turing 的计算理论一样,建立在逻辑的基础上。这也就是为什么 Kolmogorov 提出了基于 Turing 机的 Kolmogorov 复杂度,并由此推导出 Shannon 熵是 Kolmogorov 复杂度的数学期望。另一方面,直觉主义逻辑的 Brouwer-Heyting-Kolmogorov 释义(BHK Interpretation),即一个数学命题的意义等同于证明这个命题的方法,则是现代计算机科学中的柯里-霍华德对应(Curry-Howard Correspondence)的逻辑基础。它告诉我们:命题即类型和证明即程序。人类已迈向 AI 时代,其核心概念我认为就是 TOKEN。从这个角度出发,可以大胆推测,正如 BIT 连接了计算和通信一样,TOKEN 将连接经验(记忆、推断)和理性(推理),或者按照 Daniel Kahneman 的说法就是连接了系统 1 和系统 2³⁶。因此,BIT 定义了信息时代,而 TOKEN 则将定义 AI 时代。
无论大模型当前的技术路径是否能真正通往通用人工智能(Artificial General Intelligence,AGI) 和超级人工智能(Artificial Super Intelligence,ASI),我想通过这篇论文和这个系列的解读文章来说明:AI 时代的大幕已经正式开启,我们要围绕新的核心概念开展研究与开发,构筑新的理论和系统。也许大模型的下一个 Token 预测并非真的在思考,但无论是谁也无法否认大模型革命性地提升了自动化整合和处理信息的能力。也许正如电影《模仿游戏》中 Turing 的那句震撼心灵的台词:有趣的问题是,只因为某样东西与你思考的方式不同,就意味着它不思考吗?(The interesting question is, just because something thinks differently from you, does that mean it's not thinking?)
参考文献
¹ B. Bai, "Forget BIT, it is all about TOKEN: Towards semantic information theory for LLMs," arXiv: 2511.01202, Nov. 2025.
² C. Shannon, "A mathematical theory of communication," The Bell System Technical Journal, vol. 27, no. 7, pp. 379-423, Oct. 1948.
³ W. Weaver and C. Shannon, "Recent contributions to the mathematical theory of communications," The Rockefeller Foundation, Sep. 1949.
⁴ C. Shannon, "A mathematical theory of communication," The Bell System Technical Journal, vol. 27, no. 7, pp. 379-423, Oct. 1948.
⁵ R. Ash, Information Theory. New York, NY, USA: Dover Publications, 1990.
⁶ N. Alon and J. Spencer, The Probabilistic Method, 4th ed. Hoboken, NJ, USA: John Wiley & Sons, 2016.
⁷ R. Sutton, "The Oak architecture: A vision of super intelligence from experience," Invited talk at NeurIPS ’25, San Diego, CA, USA, Dec. 03, 2025.
⁸ C. Shannon, "A mathematical theory of communication," The Bell System Technical Journal, vol. 27, no. 7, pp. 379-423, Oct. 1948.
⁹ T. Berger, Rate Distortion Theory: A Mathematical Basis for Data Compression. Englewood Cliffs, NJ, USA: Prentice Hall PTR, 1971.
¹⁰ R. Blahut, "Computation of channel capacity and rate-distortion functions," IEEE Transactions on Information Theory, vol. 18, no. 4, pp. 460-473, Jul. 1972.
¹¹ S. Arimoto, "An algorithm for computing the capacity of arbitrary discrete memoryless channels," IEEE Transactions on Information Theory, vol. 18, no. 1, pp. 14-20, Jan. 1972.
¹² S. Wu, W. Ye, H. Wu, H. Wu, W. Zhang, and B. Bai, "A communication optimal transport approach to the computation of rate distortion functions," arXiv: 2212.10098, Dec. 2022.
¹³ J. Massey, "Causality, feedback and directed information," in Proc. IEEE International Symposium on Information Theory ’90, Waikiki, HI, USA, Nov. 1990.
¹⁴ R. Ash, Information Theory. New York, NY, USA: Dover Publications, 1990.
¹⁵ H. Marko, "The bidirectional communication theory: A generalization of information theory," IEEE Transactions on Communications, vol. 21, no. 12, pp. 1345-1351, Dec. 1973.
¹⁶ G. Kramer, "Directed information for channels with feedback," Ph. D Dissertation, ETH Zurich, Zurich, Switzerland, 1998.
¹⁷ D. Tsur, O. Sabag, N. Kashyap, H. Permuter, and G. Kramer, "Directed information: Estimation, optimization and applications in communications and causality," arXiv: 2602.09711, Feb. 2026.
¹⁸ R. Dobrushin, "General formulation of Shannon's main theorem in information theory," American Mathematical Society Translations: Series 2, vol. 33, no. 2, pp. 323-438, 1963.
¹⁹ V. Strassen, "Asymptotische abschätzungen in Shannon's informationstheorie," in Transactions of 3rd Prague Conference on Information Theory '62, Prague, Czech Republic, 1962.
²⁰ Y. Polyanskiy and Y. Wu, Information Theory: From Coding to Learning. Cambridge, UK: Cambridge University Press, 2025.
²¹ R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. Manning, and C. Finn, "Direct preference optimization: Your language model is secretly a reward model," arXiv: 2305.18290, Jul. 2024.
²² D. Williams, Probability with Martingales. Cambridge, UK: Cambridge University Press, 1991.
²³ I. Naiss and H. Permuter, "Extension of the Blahut-Arimoto algorithm for maximizing directed information," IEEE Transactions on Information Theory, vol. 59, no. 1, pp. 204-222, Jan. 2013.
²⁴ M. Donsker and S. Varadhan, "Asymptotic evaluation of certain Markov process expectations for large time, IV," Communications on Pure and Applied Mathematics, vol. 36, no. 2, pp. 183-212, Mar. 1983.
²⁵ M. Belghazi et al., "MINE: Mutual information neural estimation," arXiv: 1801.04062, Aug. 2021.
²⁶ D. Tsur, Z. Aharoni, Z. Goldfeld, and H. Permuter, "Neural estimation and optimization of directed information over continuous spaces," IEEE Transactions on Information Theory, vol. 69, no. 8, pp. 4777-4798, Aug. 2023.
²⁷ O. Luxembourg, D. Tsur, and H. Permuter, "TREET: Transfer entropy estimation via transformers," arXiv: 2402.06919, Jul. 2025.
²⁸ T. Schreiber, "Measuring information transfer," Physical Review Letters, vol. 85, no. 2, pp. 461-464, Jul. 2000.
²⁹ L. Barnett, A. B. Barrett, and A. K. Seth, "Granger causality and transfer entropy are equivalent for Gaussian variables," Physical Review Letters, vol. 103, no. 23, pp. 238701, Dec. 2009.
³⁰ P. Amblard and O. Michel, "The relation between Granger causality and directed information theory: A review," Entropy, vol. 15, no. 1, pp. 113-143, Jan. 2013.
³¹ J. Pearl, Causality: Models, Reasoning, and Inference, 2nd ed. New York, NY, USA: Cambridge University Press, 2009.
³² J. Pearl and D. Mackenzie, The Book of Why: The New Science of Cause and Effect. New York, NY, USA: Basic Books, 2018.
³³ D. Silver et al., "Mastering the game of Go without human knowledge, Nature, vol. 550, no. 7676, Oct. 2017.
³⁴ DeepSeek-AI, "DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning," DeepSeek, Hangzhou, China, Jan. 2025.
³⁵ L. Berglund et al., "The reversal curse: LLMs Trained on 'A is B' fail to learn 'B is A'," arXiv: 2309.12288, May 2024.
³⁶ D. Kahneman, Thinking, Fast and Slow. New York, NY, USA: Farrar, Straus and Giroux, 2013.