ICLR2026 Oral | 北大彭一杰团队提出高效优化新范式,递归似然比梯度优化器赋能扩散模型后训练
在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。近日,北京大学彭一杰教授团队在国际顶会 ICLR 2026 上发表重磅研究,提出递归似然比(RLR)优化器,为扩散模型后训练提供了兼顾效率与性能的半阶微调新方案。该研究第一作者为彭教授指导的博士生任韬,相关成果已被 ICLR 2026 接收为 oral。

论文链接:https://openreview.net/forum?id=AZ6lqcvHLX
开源代码:https://github.com/RTkenny/RLR-Optimizer

生成效果
现有方法瓶颈凸显,扩散模型后训练亟待突破
扩散模型通过递归去噪过程生成数据,其强大的表达能力依赖于海量数据预训练。但在实际应用中,需要通过后训练对模型进行精准对齐,以满足特定场景的质量要求或人类偏好。当前主流的后训练方法主要分为两类:基于强化学习(RL)的方法和基于截断反向传播(BP)的方法,但两者均存在显著缺陷。
截断 BP 方法为降低内存开销,会终止部分梯度计算,导致梯度估计存在结构性偏差,严重时会引发模型崩溃,生成内容退化为纯噪声;而 RL 方法虽能降低内存需求,但梯度估计方差极高,样本效率低下,训练收敛缓慢。例如,使用全 BP 训练 Stable Diffusion 1.4 仅需 50 个时间步就需约 1TB GPU 内存,完全不具备实用价值;而截断 BP 和 RL 方法又难以兼顾训练稳定性与生成质量。
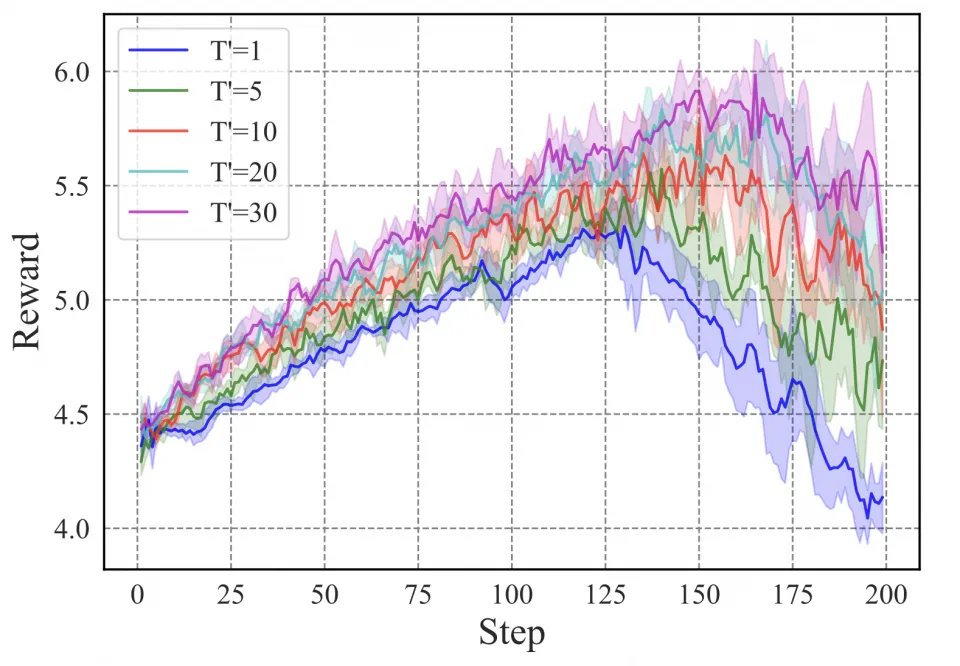
截断 BP 导致训练崩溃,奖励曲线在后期快速下降
RLR 优化器,实现无偏低方差梯度估计
为突破上述困境,彭一杰教授团队提出递归似然比(RLR)优化器,创新性地设计了半阶梯度估计范式(Half-Order Estimator)。该方法通过利用扩散模型固有的噪声特性,重构递归扩散链中的计算图,实现了无偏且低方差的梯度估计,同时有效平衡了计算成本与优化效果。
RLR 优化器的核心设计包含三大模块:
1. 一阶估计模块:在第一个时间步直接对奖励模型进行反向传播,充分利用模型结构信息,避免黑箱处理带来的精度损失;
2. 半阶优化模块:引入长度为 h 的局部子链,随机选择起始位置,精准捕捉多尺度视觉信息,同时最小化方差;
3. 零阶估计模块:对剩余时间步采用参数扰动策略,确保梯度估计的无偏性,且无需缓存中间潜变量,大幅降低计算开销。

算法框架
半阶估计量的核心可控参数为局部子链长度 h,而 h 的取值直接决定了内存开销与梯度方差的此消彼长关系,这也是 RLR 优化器实现 memory-variance tradeoff 的核心调控旋钮。研究团队将 h 的求解转化为带内存预算约束的方差最小化优化问题,从理论上定量解决了扩散模型微调的内存 - 方差的权衡,为 h 的选择提供了明确的数学依据。
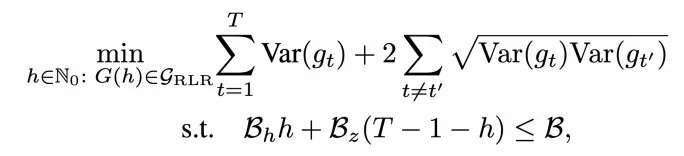
给定内存约束下的方差最小化问题
研究团队基于该方差最小化问题推导出半阶估计量子链长度 h 的最优解析解 h*,并经消融实验验证了工程最优取值:理论上 h * 取内存约束下最大可行 h 与方差最小化理论最优 h 的较小值。在 30~40GB 主流 GPU 内存预算(8 张 V100 GPU)下,h=2 为工程黄金取值,该取值可让半阶子链捕捉扩散链关键尺度信息、将整体方差降至饱和区间,若将 h 增至 3 或 4,单步训练时间从 1.61 分钟飙升至 5.65 分钟、9.23 分钟,奖励分数却仅微幅提升,性价比较低。这一设计实现了内存与梯度方差的定量最优权衡,让 RLR 在有限硬件下兼顾无偏性、低方差与高计算效率。
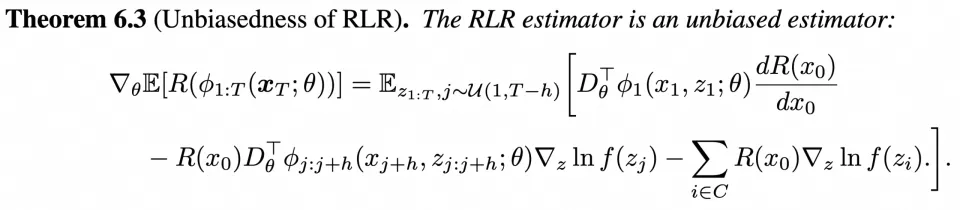
无偏性证明
团队通过严格的理论分析,证明了 RLR 估计器的无偏性,并给出了方差边界和收敛速率保证。与现有方法相比,RLR 既解决了截断 BP 的偏差问题,又克服了 RL 方法的高方差缺陷,在计算效率与优化性能之间实现了最优平衡。

收敛性证明
实验结果惊艳,图像视频生成任务全面超越 SOTA
为验证 RLR 优化器的有效性,团队在文本到图像(Text2Image)和文本到视频(Text2Video)两大核心任务上开展了大规模实验,与 DDPO、AlignProp、VADER 等基于 RL 和截断 BP 的主流方法进行了全面对比。
在 Text2Image 任务中,基于 Stable Diffusion 1.4 和 2.1 的实验结果显示,RLR 在 PickScore、HPSv2、AES 等多个人类偏好奖励模型上均取得最高奖励分数。其中,在 HPD v2 数据集上,RLR 将 Stable Diffusion 1.4 的 ImageReward 分数从 32.90 提升至 76.55,较 DDPO 提升约 47%,较 AlignProp 提升约 14%。

图像任务的测评表现
在 Text2Video 任务的 VBench 基准测试中,RLR 在主体一致性、运动流畅度、动态程度等 6 个核心指标上表现突出,加权平均分数达到 84.63,超越了 VideoCrafter、Pika、Gen-2 等开源及 API-based 模型,其中动态程度指标达到 70.69,显著领先于其他方法的最高值 66.94。
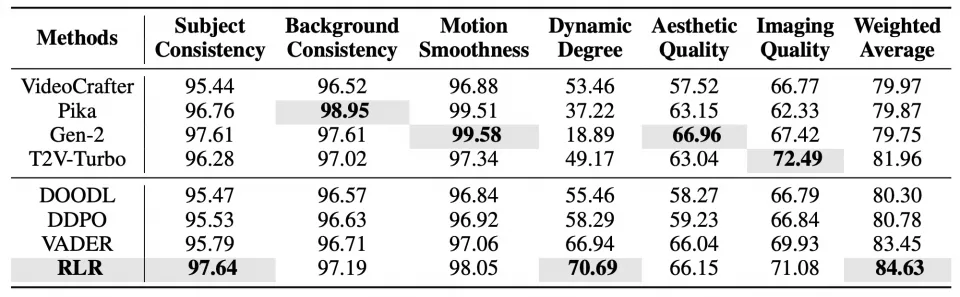
视频任务上的测评表现
此外,团队还为 RLR 优化器量身设计了扩散思维链提示词技术,通过将原始提示词分解为粗、中、细多尺度提示词,让半阶子链精准针对生成缺陷的尺度进行梯度更新,进一步挖掘 RLR 的性能潜力,在手部生成等细粒度任务中实现了显著的性能提升。
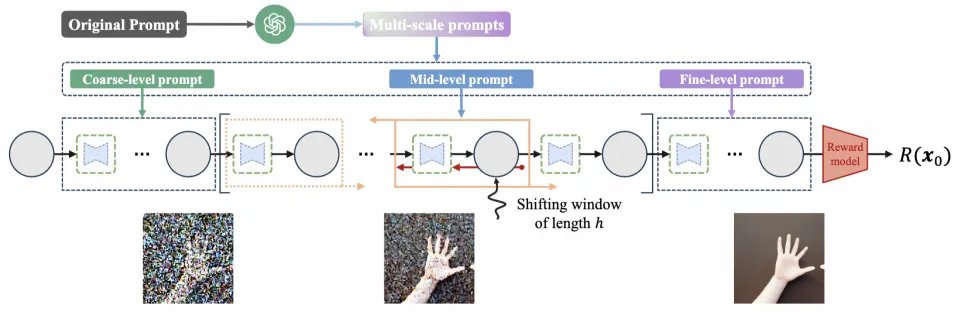
适配 RLR 优化器的扩散思维链