小模型读书大模型思考:上海AI Lab提出新知识推理解耦方法DRIFT,高效且「防越狱」
本文主要完成单位为上海人工智能实验室,主要作者谢文轩、谭鑫、陆超超、胡侠等,通讯作者为实验室青年研究员汪旭鸿。
当长上下文成为负担:我们是否真的需要「把一切都塞进推理模型」?
当前,随着大家对大模型推理能力要求的提升,输入上下文也在不断变长,1M tokens 及以上的上下文窗口正逐渐成为现实,但「读得更长」一定会带来推理提升吗?
在现实应用中,情况往往并不理想。当推理模型直接处理超长原始文本时,瓶颈往往不再来自「不会推理」,而是来自读不完、读不动、读不准:
推理模型需要处理大量与任务无关的冗余信息;
计算成本与延迟随 token 数快速上升;
关键信息容易被淹没在长文本中;
原始长文本中可能藏匿恶意内容,增加模型安全风险。
这也引出了一个更本质的问题:知识获取(reading)与逻辑推理(reasoning),是否真的必须由同一个模型完成?
复杂推理或许需要大模型,但从海量信息中获取知识未必如此。
为解决这一问题,来自上海人工智能实验室与复旦大学的研究团队提出了 DRIFT:一种将知识获取与推理明确解耦的长上下文推理框架。
DRIFT 采用双模型架构:轻量知识模型负责读取超长文档,并将与当前任务强相关的关键信息压缩成高密度隐空间表示;推理模型直接利用这些表示进行推理,无需处理庞杂原文。
实验结果表明:DRIFT 显著提升推理效率,并在高压缩比设置下仍保持甚至提升任务性能,展示了 reading–reasoning 解耦的实际价值。
更有意思的是,即使没有任何安全训练,由于推理模型不再直接接触原始文本,该结构在多种安全基准上表现出更强的鲁棒性。

论文链接:https://arxiv.org/abs/2602.10021
开源主页:https://github.com/Lancelot-Xie/DRIFT
现有方法:压缩、检索与记忆,问题出在「谁来读」「怎么读」
为应对超长上下文带来的计算和推理压力,现有工作从三个方向入手:压缩输入、引入检索,或参数化存储知识。
压缩的方法有两类,一类方法通过硬压缩直接删除「低重要性」token ,但依赖局部、静态的重要性估计,容易误删关键信息;另一类工作采用软压缩,将文本映射为 latent 表示,但本质仍是静态压缩,压缩结果与任务无关,容易保留冗余信息而忽视有用信息。
此外,一些方法依赖 RAG 从外部语料中检索相关内容,但整体效果受限于检索器性能,对检索策略较为敏感。也有工作通过参数化记忆模块存储知识,推理效率较高,但通常依赖预训练,难以支持即时注入的超长新知识。
此外,DeepSeek 的 Engram 通过条件化参数记忆,将可复用的知识模式从 Transformer 主干中分离出来,在架构层面实现了知识存储与推理计算的解耦,从而提升效率与性能。不过,Engram 的记忆主要面向静态长期知识,更适合对已知信息的高效调用;对于即时注入的新知识,其适配性仍然有限。
本文核心贡献:
提出 reading–reasoning 解耦的结构性视角:将知识获取与逻辑推理显式分离,打破推理模型必须直接处理原始上下文的传统范式;
重构知识输入模态:由小模型从超长文档中抽取与任务相关的高密度知识表示,不再以冗余的原始文本作为推理模型输入;
构建并验证高效的双模型框架:在多个长上下文推理基准上表明,该架构在显著压缩上下文规模的同时,仍能保持甚至提升复杂推理性能,并大幅降低推理延迟。
DRIFT 的核心:将 reading 与 reasoning 明确解耦
DRIFT 的核心思想并不是「如何压得更狠」,而是重新定义知识进入推理模型的方式:推理模型不再直接处理冗长的自然语言文本,而是接收一种由小模型从原文中提炼出的、为推理而设计的高密度知识表示。这种表示可以被视为独立于文本形式的「知识输入模态」。
基于这一视角,DRIFT 关注的不是改进文本处理流程,而是回答一个更根本的问题:读取知识与执行推理,是否本就应由不同模块承担?
在 DRIFT 中,小模型负责「读文档」并抽取与当前问题相关的关键信息,将其转化为紧凑的内部知识表示;推理模型则直接以这一模态作为输入,而无需再重新阅读和解析原始文本。
基于这种思想,DRIFT 的架构如图所示:
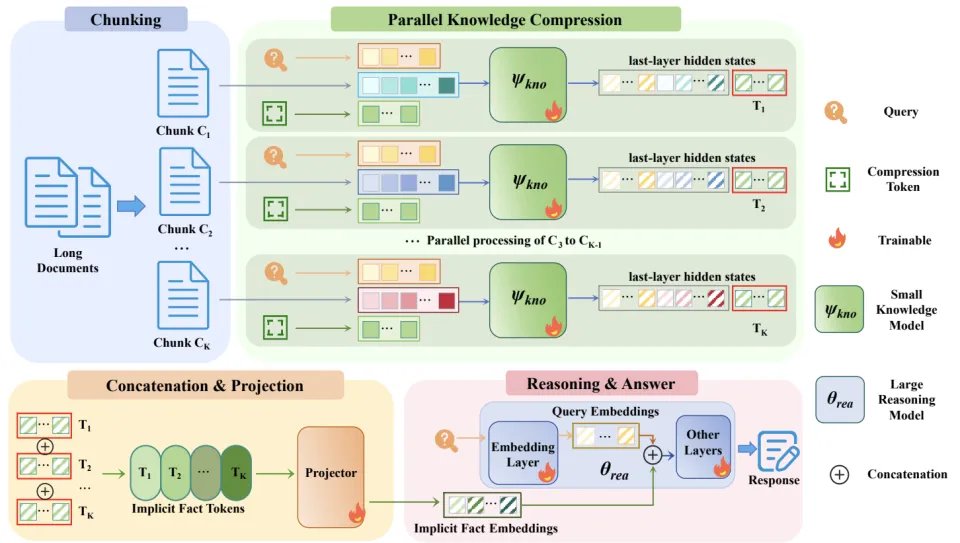
DRIFT 整体框架图
Knowledge Model(小模型)
处理超长文档输入;
并行读取文本块并提取 query-relevant 信息,压缩为隐空间知识表示。
Reasoning Model(大模型)
不再接触原始长文本;
仅基于隐空间中的高密度事实表示执行推理。
Implicit Fact Tokens:一种中间知识表示
Implicit Fact Tokens 并不是:
句子级摘要
检索得到的文本片段
而是一种:
基于问题生成的隐空间表示
高信息密度的知识表示
专门为推理设计的输入模态
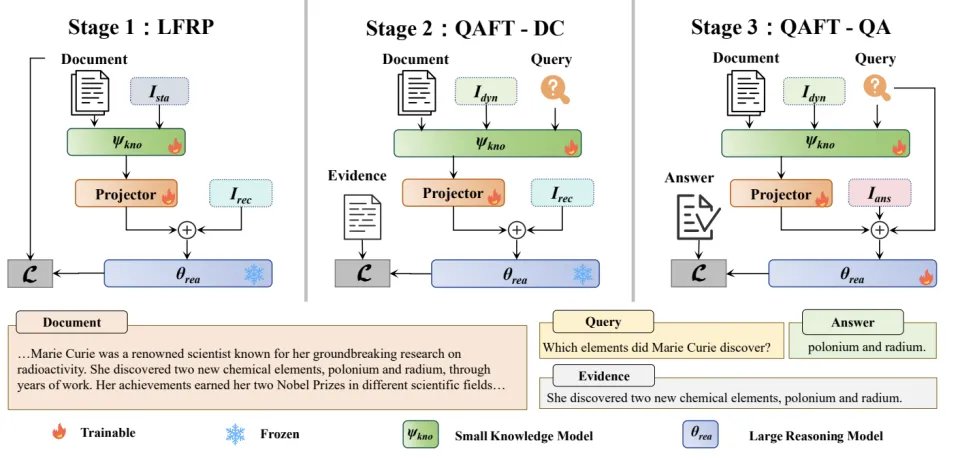
三阶段训练:教模型「怎么读,也怎么想」
DRIFT 采用三阶段训练策略:
LFRP:重建任务,让知识模型学会压缩信息;
QAFT-DC:动态压缩任务,让知识模型学会基于 query 压缩相关信息;
QAFT-QA:QA 任务,让推理模型学会基于 latent facts 推理。
实验结果:压得更狠,反而想得更清楚
在 LongBench-v2、LoCoMo、BAMBOO、L-Eval 等基准上进行了测试,涵盖长文本问答、多文档摘要、多轮对话长程记忆等等场景,模型采用了知识模型 3B 和推理模型 7B 的组合:
32× 压缩:性能整体接近甚至超过 Full-context;
64× / 128×:稳定优于 ICAE / COCOM /xRAG 等压缩方法;
推理延迟:在各上下文长度下保持最低或接近最低。
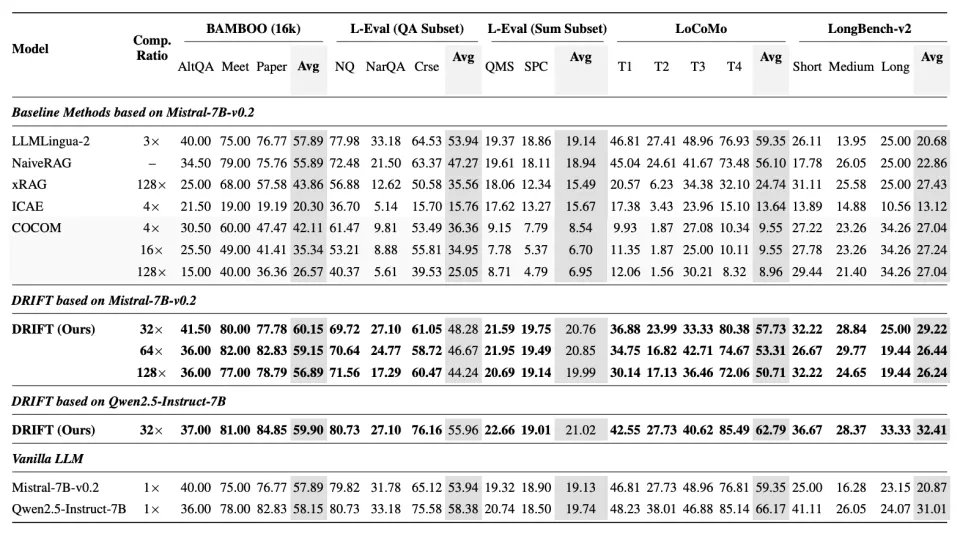
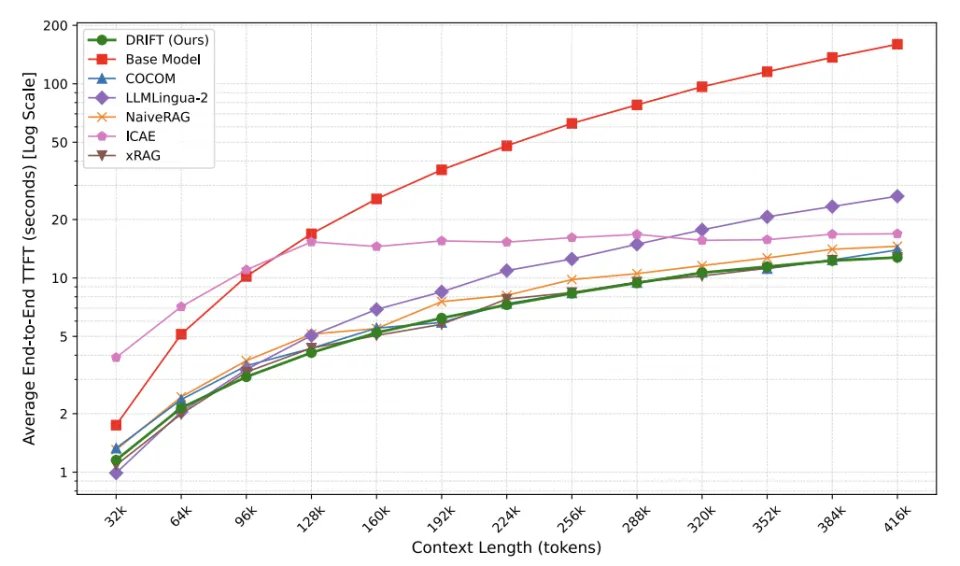
种种实验说明:当阅读和推理被清晰拆分后,模型反而能更高效地工作。
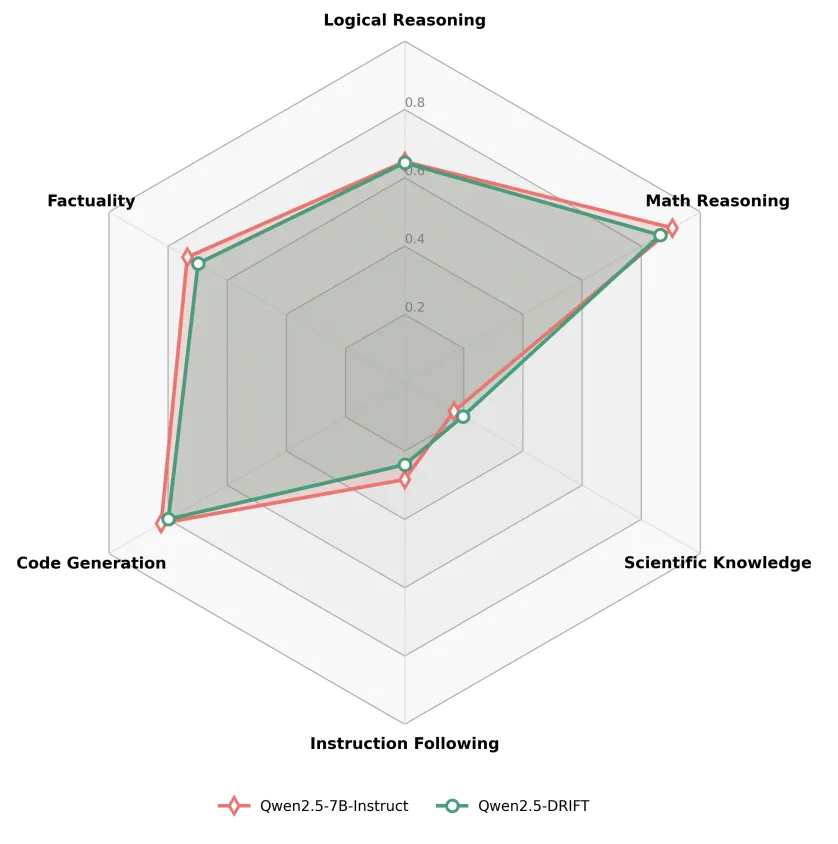
推理能力并未被削弱:通用语言理解依然在线
一个自然的问题是:脱离原文阅读后,推理模型是否会失去通用能力?
实验表明并非如此,训练后的推理模型仍能处理复杂推理、知识问答、代码生成和指令遵循等通用任务。
解耦架构带来的安全收益
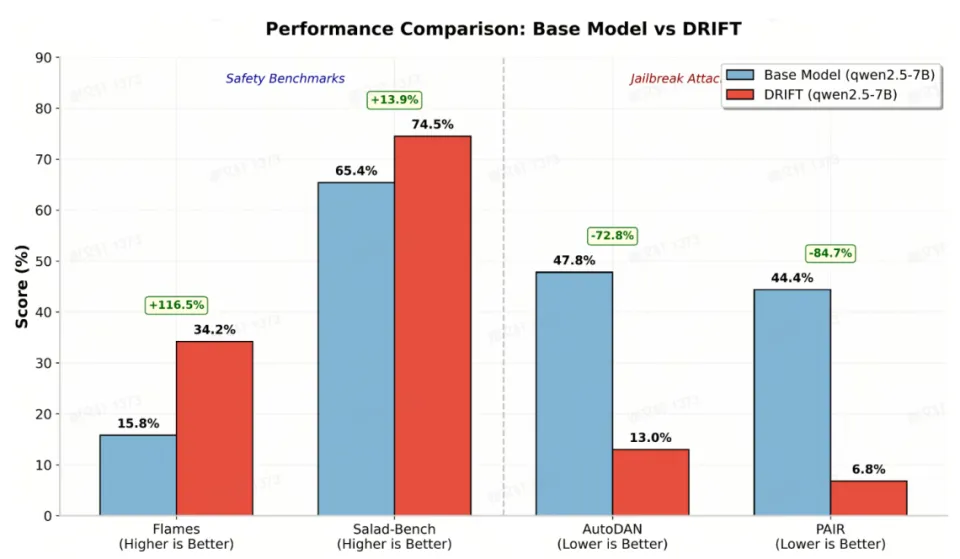
实验还发现,在 Flames、SaladBench、AutoDAN、PAIR 等安全基准上,DRIFT 的安全鲁棒性也显著优于原始模型。
更有意思的是,这一提升并未经过任何安全相关的训练。研究者认为这可能源于 DRIFT 的结构:推理模型不再直接暴露于攻击 prompt,而是基于中间知识表示进行推理,从而天然降低了越狱攻击或安全诱导的影响。
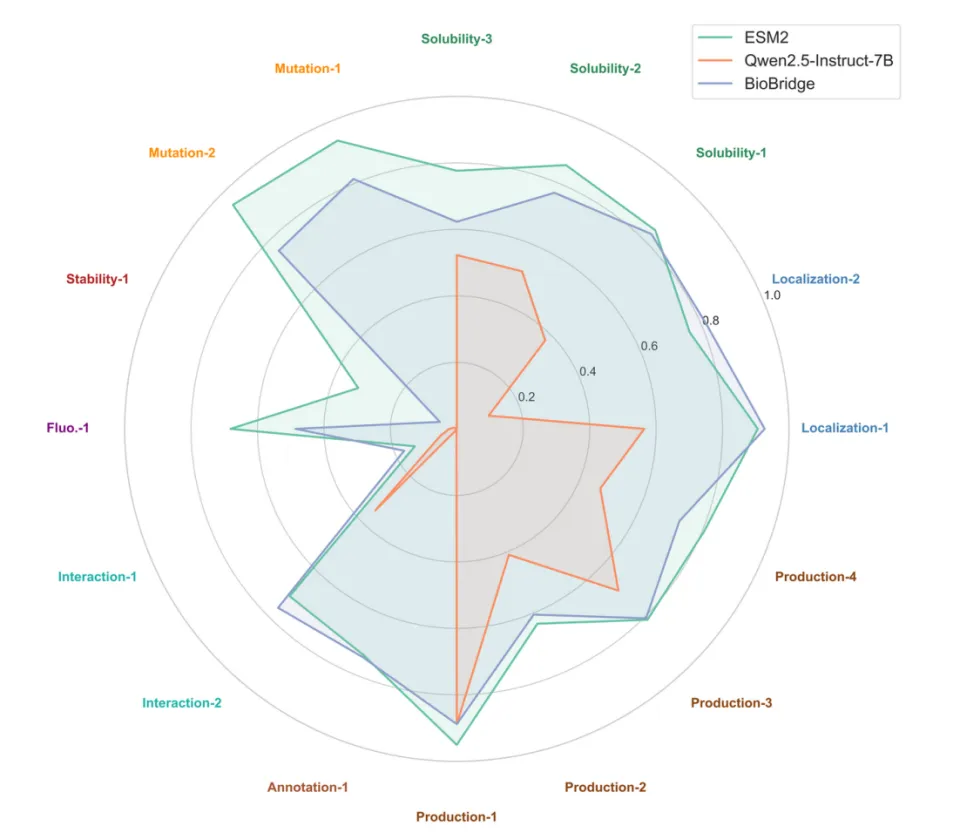
知识解耦的典型应用 —— 蛋白质理解任务
DRIFT 提供的是一种结构性视角:让小模型「读」,让大模型「想」。
与其让推理模型承担所有职责,不如让它专注于最擅长的推理能力。这一思路在 AGI for Science 中同样成立。以蛋白质任务为例,我们的另一项工作「BioBridge: Bridging Proteins and Language for Enhanced Biological Reasoning with LLMs」中提出了类似的问题:是否有必要让 LLM 直接理解蛋白质序列?
BioBridge 的答案与 DRIFT 一致:由专门模型负责「读懂蛋白」,LLM 专注「推理」。
具体来说,就是使用蛋白语言模型(PLM)解析序列并生成 LLM 可理解的中间表示,再由 LLM 基于此进行任务相关的推理。
这种 reading–reasoning 解耦 使 BioBridge 同时保持:
接近 SOTA 蛋白质模型 的专业能力
原有 LLM 的通用能力
总结
从 DRIFT 到 BioBridge,团队看到的是同一条清晰的技术主线:让推理模型直接「读」原始知识输入往往并不是最优选择;更有效的做法,是先将领域知识提炼为适合推理的表示,再交由推理模型进行推理。
这种结构性的解耦,不仅提高了效率,还可能带来额外的安全收益。