OpenClaw带火AI记忆,DeepMind用混合记忆把3D重建拉到近2万帧
过去两天,全球爆火的 Agent 私人助手 OpenClaw,接连更新了两个版本,让人直呼「开发团队是不睡觉了吗?」
之所以如此爆火,很大程度上归功于 OpenClaw 的长期记忆能力,它能够记住用户的对话历史、偏好设置、任务上下文、个性化调整、常用信息和数据、交互偏好,等等。更新之后,OpenClaw 实现了上下文管理(记忆)的自由插拔。
记忆机制是大模型处理复杂任务的重要能力之一。在聊天对话、自动化工作流等场景中,模型需要通过记忆保持长期上下文。而在 3D 重建领域,尤其是大范围场景或长序列视频重建,跨帧信息的持续传播同样至关重要,记忆机制正是实现这一能力的重要手段。
现有的前馈 3D 重建模型往往依赖短时上下文窗口,难以有效建模长序列中的依赖关系。随着几何基础模型(如 DUSt3R、MonST3R、VGGT)的出现,可以从大规模数据中提炼复杂的几何先验,使得即便在传统方法较难处理的场景中,仍能实现稳健的前馈推理。不过,当前模型仍然存在一个关键空白:尽管经典处理流程可以扩展到城市级别,但现有的前馈模型在处理更大规模的场景时,仍然受到限制。
主要障碍源自两个方面,即当前架构中固有的上下文壁垒和训练过程中严重的数据壁垒。从架构角度看,虽然双向注意力对于学习复杂的几何先验至关重要,但其二次复杂度使得它只能应用于短时上下文窗口。而从数据角度看,当前的模型主要在短时上下文「气泡」(几十到一百多帧)上进行训练,这使得它们在推理时无法有效整合长距离依赖(数千到数万帧)。因此,像 FastVGGT 这样的推理时启发式方法,虽然成功缓解了内存瓶颈,但仍无法在大规模 VBR 数据集上进行泛化。
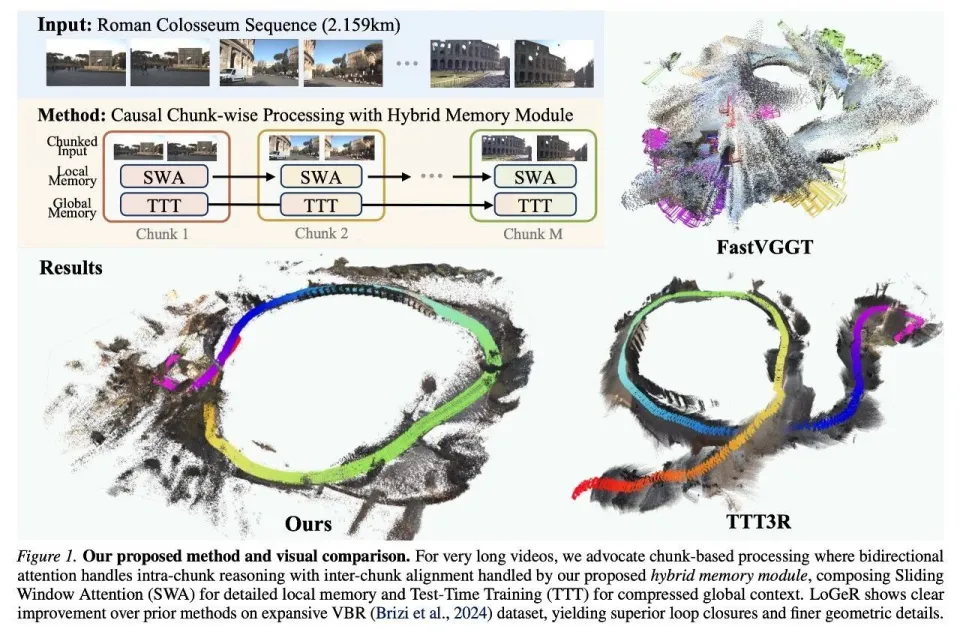
针对这一痛点,近日,谷歌 DeepMind 联合加州大学伯克利分校提出了 LoGeR(长时上下文几何重建)。这是一种新颖的架构,在无需后期优化的情况下将密集的 3D 重建扩展到极长的序列。过程中,LoGeR 通过将视频流分块处理,利用强大的双向先验进行高保真度的块内推理。
为了应对跨块边界一致性的挑战,研究者提出了一种基于学习的混合记忆模块。这个双组件系统结合了参数化的测试时训练(TTT)记忆模块,用于锚定全局坐标框架并防止尺度漂移,同时使用非参数化的滑动窗口注意力(SWA)机制来保持未压缩的上下文,从而实现高精度的相邻块对齐。

论文标题:LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
arXiv 链接:https://arxiv.org/pdf/2603.03269
项目地址:https://loger-project.github.io/
值得注意的是,这种记忆架构使得 LoGeR 能够在 128 帧的序列上进行训练,并在推理过程中泛化到数千帧。
在标准基准测试和重新设计的 VBR 数据集(包含最多 19000 帧的序列)上进行评估时,LoGeR 明显超越了先前的前馈方法,在 KITTI 数据集上将绝对轨迹误差(ATE)降低了超过 74%,并且在前所未有的时间跨度上实现了稳健、全球一致的重建。
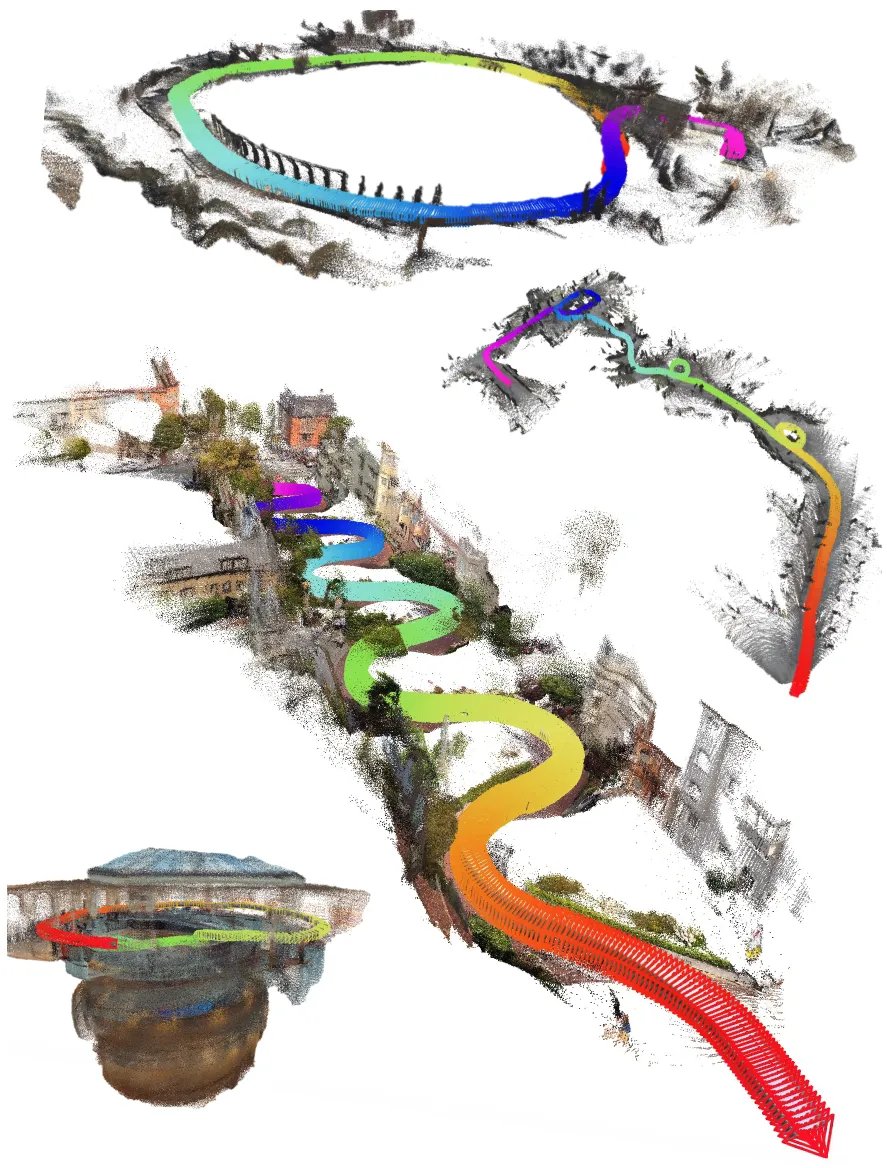
视觉展示,在大规模真实场景(in-the-wild)以及 VBR 序列上的定性结果。本文的全前馈方法能够在数千帧的长序列中准确保持大尺度结构,并实现稳定的回环闭合。
方法概览
为了将前馈密集型 3D 重建扩展到分钟级视频,必须克服全局注意力的二次复杂度和长时训练数据的稀缺问题。端到端的分块处理成为自然的解决方案,它严格限制了计算成本,并确保局部推理保持在现有短时上下文训练数据的分布范围内。然而,独立处理每个块会导致全局一致性的丧失。
因而需要这样一种前馈架构,它能够同时提供: (i) 强大的局部双向推理能力,以保持密集的几何保真度;(ii) 无损的短程信息传递通道,以保持跨相邻块边界的高精度几何对齐;(iii) 一个线性时间、固定大小的记忆机制,用于在数千帧的长距离内传播全局信息。
研究者通过分块顺序处理输入视频流,如图 1 和图 2 所示。
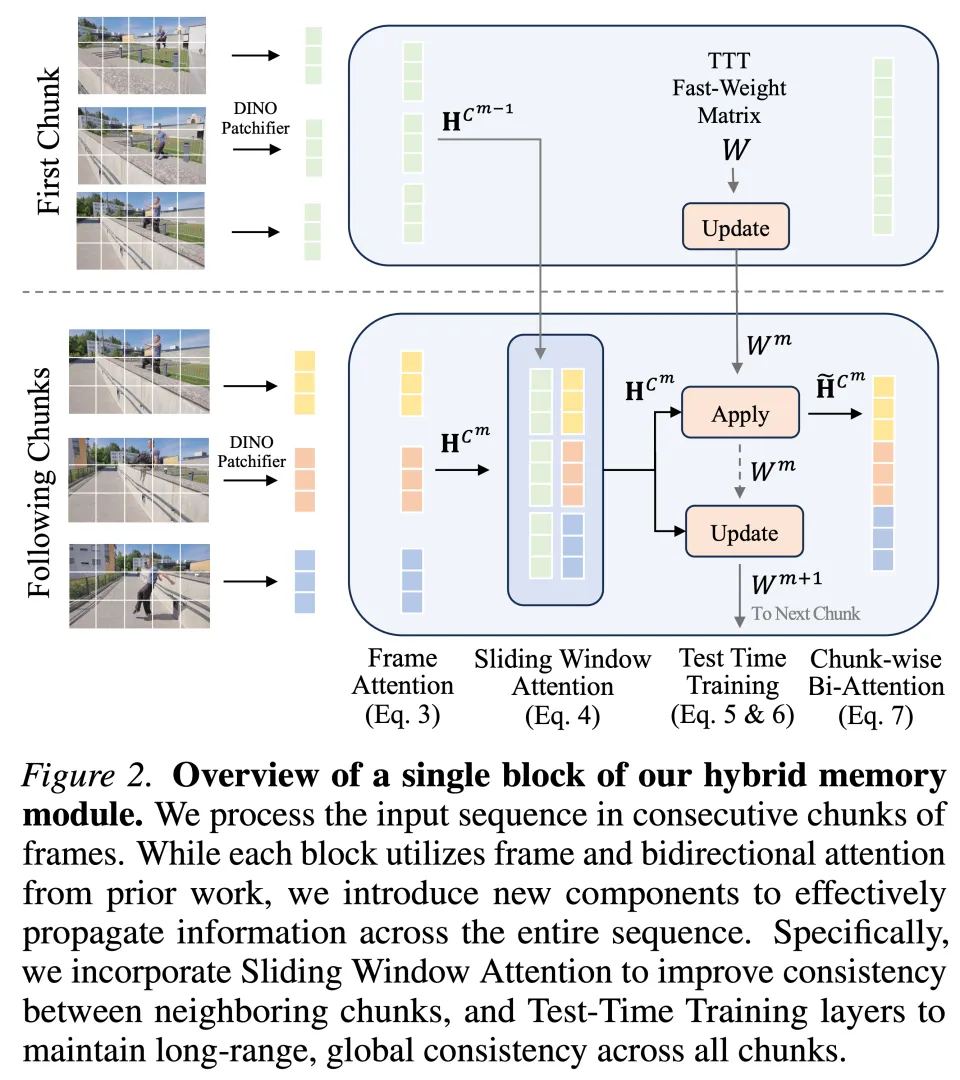
为了在块之间传播信息,研究者引入了两种互补的机制:
一是:通过分块 TTT 实现长时、有损压缩。
通过插入 TTT 层,保持跨多个块的快速权重集 W。与分块处理方式一致,研究者利用大块测试时训练(LaCT),并证明它比标准 TTT 更高效。在推理过程中,权重会对每个块进行更新和应用操作。在应用操作中,TTT 层利用存储在权重中的历史信息来调节网络处理当前块的方式。
在更新操作中,权重会被编辑,存储来自当前块的信息,从概念层面压缩重要但冗余的几何信息,例如粗略的几何形状和场景的尺度。虽然这些快速权重理论上提供了无限的接收场,但它们的实际容量本质上受到训练上下文长度的限制。
二是:通过滑动窗口注意力(SWA)实现短时、无损传递。
单纯依赖 TTT 样式的状态传递本质上是有损的,这对于密集型 3D 重建尤其构成问题,因为在相邻帧之间保持几何一致性至关重要。为此,研究者以稀疏方式插入滑动窗口注意力层,关注来自前一个和当前块的帧注意力层输出的 tokens,即 C^m−1 ∪ C^m。
这建立了一个无损的信息传递通道,直接传播来自前一个块的高保真特征。值得注意的是,这一操作保持了有限的计算和内存效率,因为滑动窗口注意力仅应用于相邻块之间,并且只插入在网络的部分深度(仅四层)。
以上两种跨块路径是互补的:TTT 提供了可扩展的长距离记忆,而 SWA 确保了相邻块之间的细粒度几何一致性。
接下来的重点是 LoGeR 前馈对齐。尽管引入了 TTT 和 SWA,但在处理非常长的流时,仍可能积累预测误差。
为了解决这一问题,研究者提出了 LoGeR,它是一个变种模型,在原始预测中加入了纯前馈对齐步骤,以确保预测结果与一致的全局坐标系统对齐。
最后还要面临「数据壁垒」和「课程学习」的挑战。
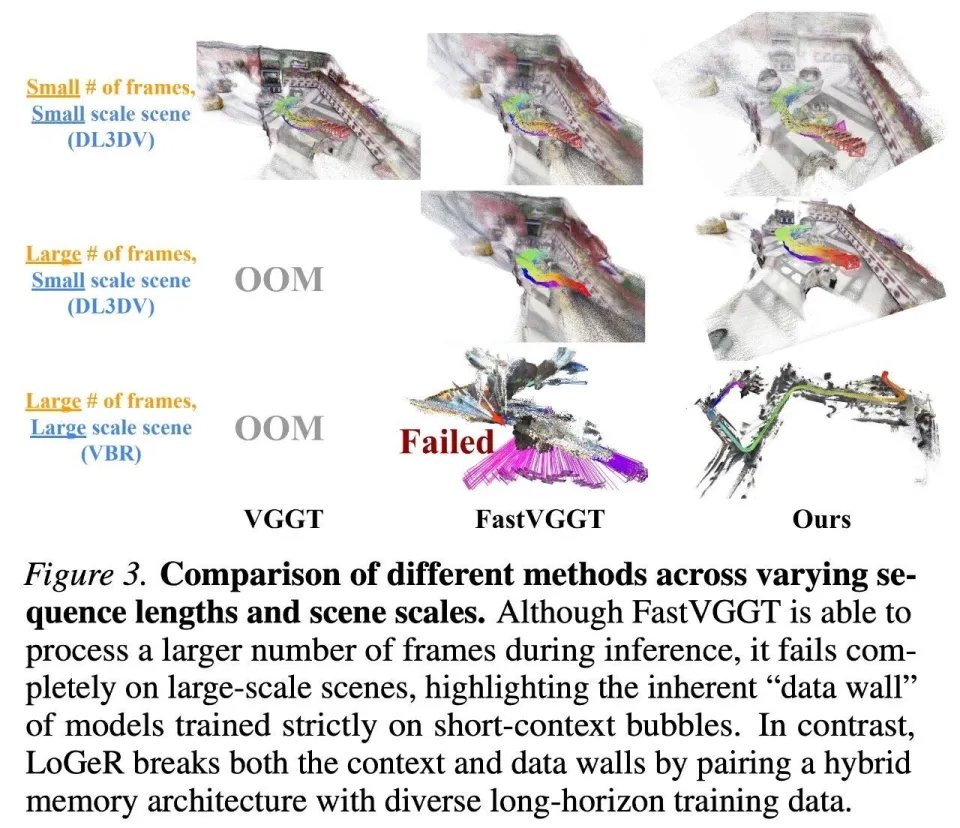
研究者认为,仅靠架构上的改进不足以实现无限上下文的重建。如图 3 所示,像 VGGT 这样的强基线方法,即使配备了推理时的架构效率提升(如 FastVGGT),在仅使用短时上下文或小规模场景数据进行训练时,依然无法很好地泛化到大规模场景。为了克服这个「数据壁垒」,研究者构建了一个训练数据集,重点增加大规模场景数据集的比例,例如 TartanAirV2,它为学习有效的几何压缩提供了必要的长时信号。
为了稳定优化递归 TTT 层的训练,研究者采用了渐进式课程策略。通过从简单序列开始,并逐渐增加复杂度,迫使模型从局部的滑动窗口注意力(SWA)转向全局的 TTT 隐藏状态。训练进度分为三个阶段: (1) 首先从 48 帧的序列开始,分成 4 个块;(2) 然后逐步增加块的密度,达到 12 个块,同时保持序列长度不变;(3) 最后,利用 H200 GPU,将上下文长度扩展到 128 帧,并逐步增加到 20 个块。
对于 LoGeR,研究者从第一阶段的模型开始,集成前馈对齐步骤,并在接下来的课程中进行微调。
实验结果
首先,从定量结果来看,LoGeR 以及本文提出的基线方法 Pi3-Chunk,在 KITTI 基准测试上均显著优于现有的前馈式方法(见表 2)。
值得注意的是,LoGeR 的平均性能甚至超过了当前最强的基于优化的方法 VGGT-Long,优势达到 32.5%。这一优势在开环场景中尤为明显(如序列 01、03、04、08 和 10)。在这些场景下,LoGeR 无需依赖回环检测,就能够有效抑制长序列中不断累积的漂移误差。
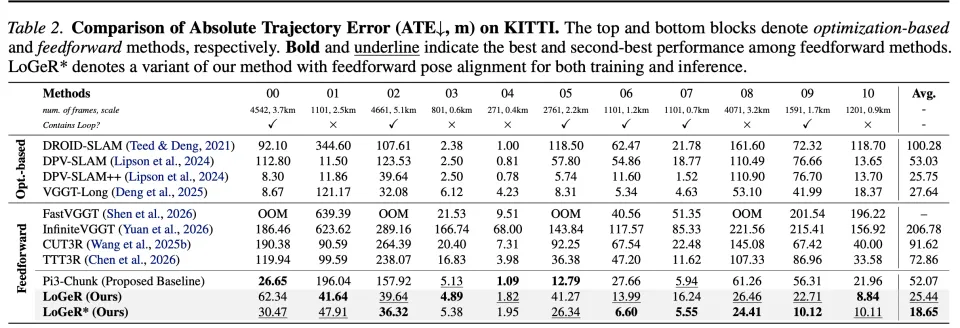
在 VBR 基准上,LoGeR 同样表现出稳定的性能提升。定量结果如图 4 所示,定性结果如图 5 所示。与基线方法相比,LoGeR 中的 TTT 模块能够天然锚定全局尺度,从而保持全局一致性。
从可视化结果可以看到,在长达 2 万帧的超长序列中,LoGeR 依然能够保持稳定的全局尺度,而基线方法在如此长的序列中会出现明显的尺度漂移问题。

其次是短序列评测。
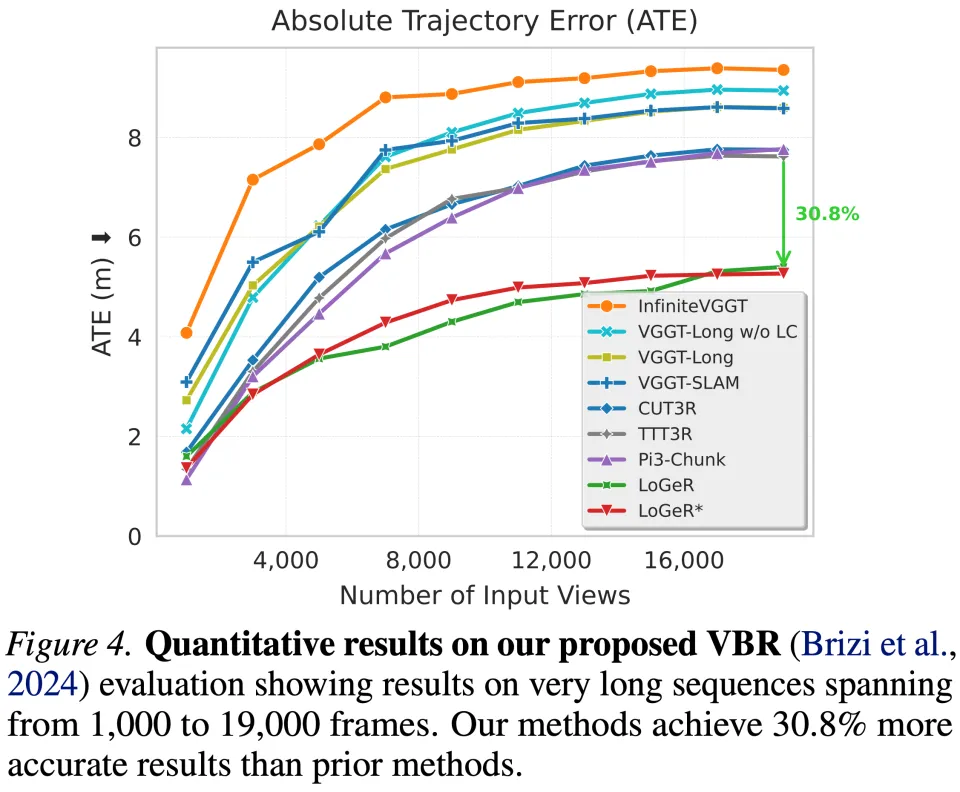
在 TTT3R 的实验设置基础上,研究者进一步将评测扩展到较短视频序列(最长约 1000 帧)。首先,在 7-Scenes 数据集上评估 3D 点云重建效果,序列长度在 50 到 500 帧之间。
研究者将 LoGeR 与多种学习式的亚二次复杂度方法进行对比,包括显式状态方法 Point3R、隐式状态空间模型 CUT3R、TTT3R、StreamVGGT 以及双向注意力基线模型 VGGT 与 π^3。在 7-Scenes 数据集上的结果如图 6 和图 7 所示:

在 ScanNetV2 和 TUM-Dynamics 数据集上的相机位姿评估结果,分别展示在图 8 和图 9 中:
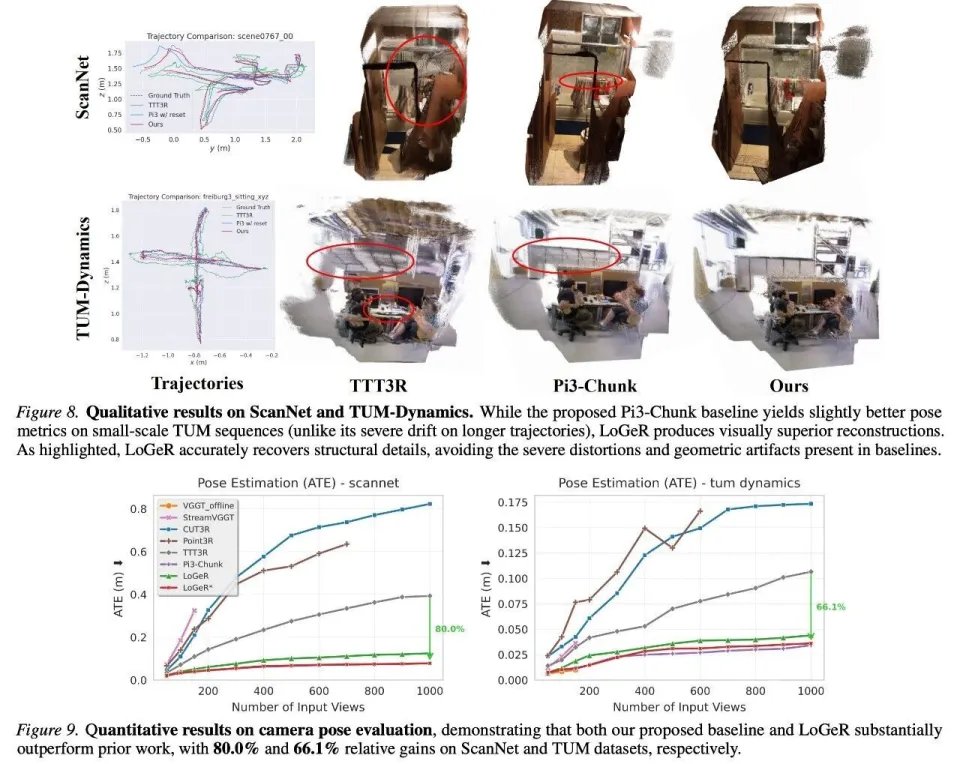
整体来看,无论是在 3D 重建质量还是位姿估计精度方面,LoGeR 及其提出的基线方法均显著优于现有方法。
更多实验结果请参阅原论文。