挺搞笑,MiniMax模型就是不认识「马嘉祺」

机器之心编辑部
最近,有网友发现了一个很有意思的 bug:MiniMax 的模型似乎不认识「马嘉祺」这三个字。
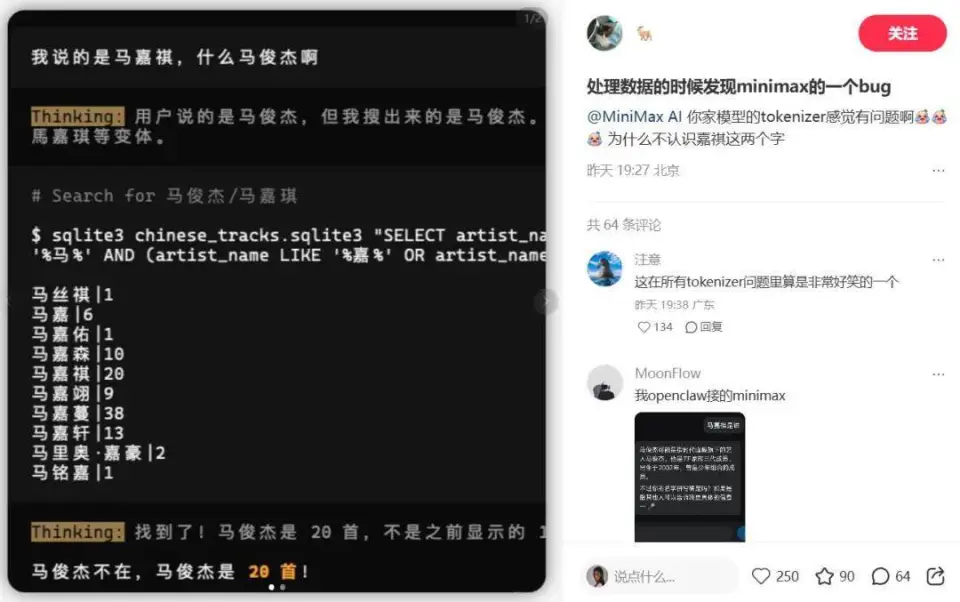
最开始大家以为只是偶然 bug。结果一测试,事情就变得有点离谱——无论是在不同接口、不同平台,这个问题几乎都能稳定复现。
甚至有人调侃:以后 OpenRouter 上如果又出现一个匿名模型,如果这个模型认不出「马嘉祺」,那它大概率是 MiniMax。
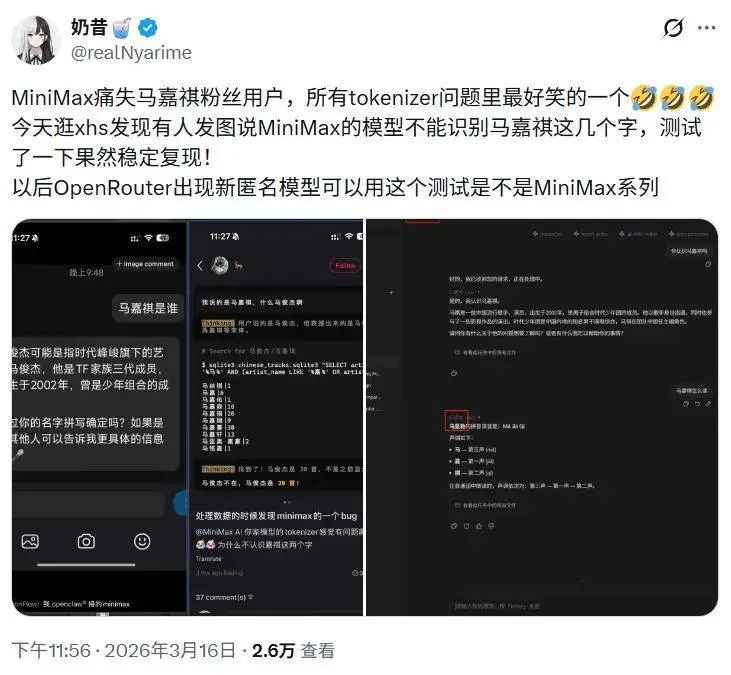
我们也测试了一下,无论是在官网的 Agent 平台,还是通过 OpenRouter 调用 MiniMax API,都成功复现了这一现象。
更有意思的是,有时甚至同时出现了两个不同名字。
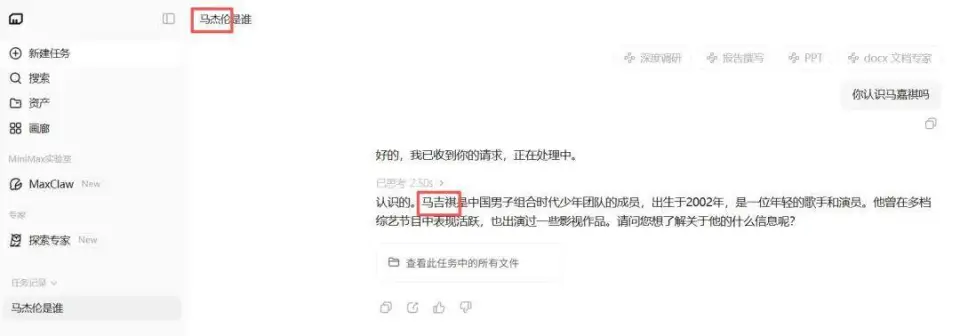

不过,仔细观察网友的截图和我们的调用返回可以发现,模型其实能够搜索到马嘉祺的相关资料,并且也能正确输出他的履历信息。只是每当说到名字时,就会开始「自由发挥」。
换句话说,信息基本是对的,人物也大体对应得上,偏偏名字出了问题。

那么为什么会出现这种情况呢?
从目前的现象看,这更像是模型在特定词汇的生成环节出现了异常,而不一定意味着它真的「不知道马嘉祺是谁」。
一种可能是与训练数据的清洗和分布有关。像马嘉祺这样讨论度极高的公众人物,互联网上往往存在大量重复、模板化的内容。在大规模去重、过滤或重加权过程中,这类词汇有可能被「误伤」,从而让模型在生成名字时表现得不够稳定。
从机制上看,大模型并不是以「先完全确认人物、再机械输出名字」的方式工作,而是在理解问题、调取相关知识和组织语言的过程中同步完成生成。因此,一旦某个特定名字在生成阶段受到额外扰动,模型就可能出现「人物信息基本对,但名字写不准」的现象。
最近一篇论文讨论了相关的底层机制问题:某些看似发生在知识层或推理层的异常,实际可能来自更底层的 tokenizer 机制缺陷(例如非唯一映射)。

论文标题:Say Anything but This: When Tokenizer Betrays Reasoning in LLMs
论文地址:https://arxiv.org/pdf/2601.14658v1
作者指出,现代子词 tokenizer 往往存在「一对多编码、但多对一解码」的情况,也就是多个不同 token 序列,最后可能对应同一个文本字符串。结果就是,模型可能在 token 层面做了「变化」,却没有在文本层面产生任何可见变化。
论文设计了一个很巧的测试:不给模型出复杂数学题,也不考知识问答,只让它做一件看似非常简单的事——把句子里被标记出来的词替换掉,其他内容保持完全不变。
按理说这几乎不该失败,因为任务目标极其明确。可作者发现,在 11000 多次替换实验里,很多模型都会出现一种他们称为 phantom edits 的现象:模型输出的 token ID 确实变了,但解码后显示出来的词,和原来一模一样。也就是说,模型「以为自己改了」,人类却看到「什么都没改」。
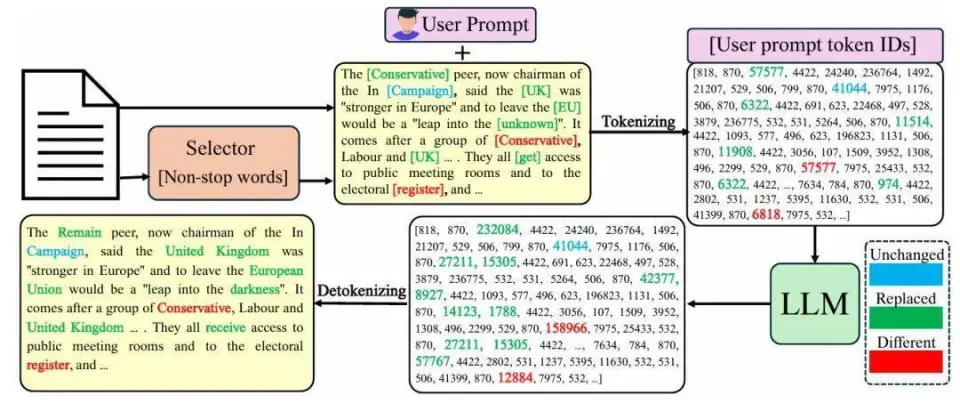
论文还指出,不是所有问题都能靠「把模型做大一点」自动解决。作者测试了多个模型家族后发现,这类由 tokenizer 非唯一映射带来的错误,并不会随着参数规模上去就自然消失。
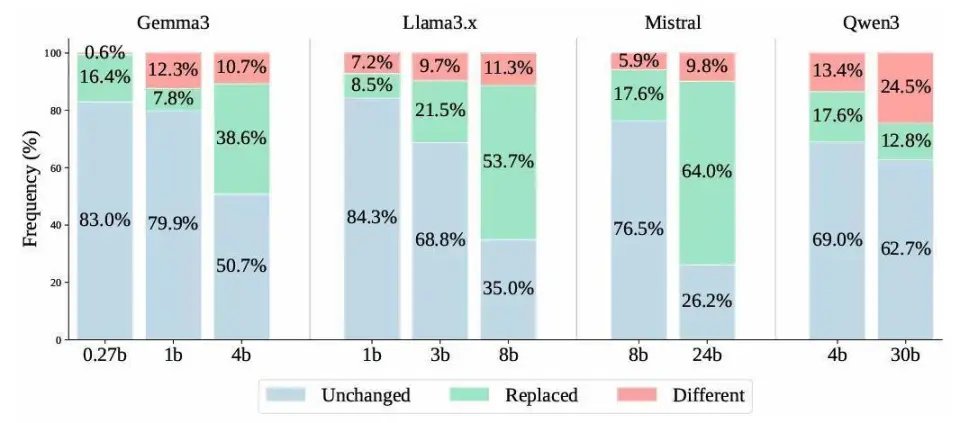
在词语替换任务中,不同大语言模型家族及不同参数规模的结果分布。「Different」(红色)类别突出了由 tokenizer 引发的「幽灵编辑」现象,这种现象在所有模型规模和模型家族中都持续存在。
论文甚至进一步提出,某些看起来像「推理能力不行」的问题,可能有一部分只是 tokenizer 在旁边悄悄添了点乱。换句话说,有时不是模型不会,而是它被底层机制带到了一条看似完成任务、实际上在原地打转的路上。