TPAMI 2026 | 北大彭宇新团队提出CPL++框架,实现视觉定位模型的「自知之明」和「自我纠错」
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

论文标题:Confidence-aware Pseudo-label Self-Correction for Weakly Supervised Visual Grounding
论文链接:https://ieeexplore.ieee.org/document/11433810/
开源代码:https://github.com/oceanflowlab/CPL
实验室网址:http://mipl.pku.edu.cn
背景与动机
视觉定位(Visual Grounding)旨在根据自然语言查询准确定位图像中的目标区域。然而,全监督方法严重依赖密集的「图像 - 文本 - 物体框」细粒度标注,这在处理大规模复杂场景时面临巨大的标注成本挑战。因此,仅利用「图像 - 文本」进行训练的弱监督视觉定位受到了广泛关注。
现有弱监督方法通常将该任务视为一个目标检索过程,依赖跨模态匹配分数或重构损失来挑选候选区域。但语言描述的高层抽象概念与图像区域的像素级特征之间存在着巨大的「异构鸿沟」,这使得跨模态匹配往往极不可靠。模型在训练中一旦学到了这些错误的「伪关联」,就会陷入错误传播和累积的死循环。此前的无监督方法尝试用模板生成伪查询,但生成的句子生硬且缺乏多样性,同样忽略了错误关联对模型的严重影响。
针对这一难题,北京大学彭宇新教授团队提出了置信度感知的伪标签学习框架(CPL)及其进阶版 CPL++,通过引入大模型生成多样化描述,并结合「自监督关联验证」机制,让模型在训练过程中学会动态发现并纠正自己的错误,实现弱监督视觉定位性能的提升。
技术方案
本文提出的 CPL 框架不仅能过滤错误的区域 - 文本关联,更能利用模型自身在训练中不断增强的定位能力,动态地「纠正」这些错误标签。其核心亮点包含以下几个方面:
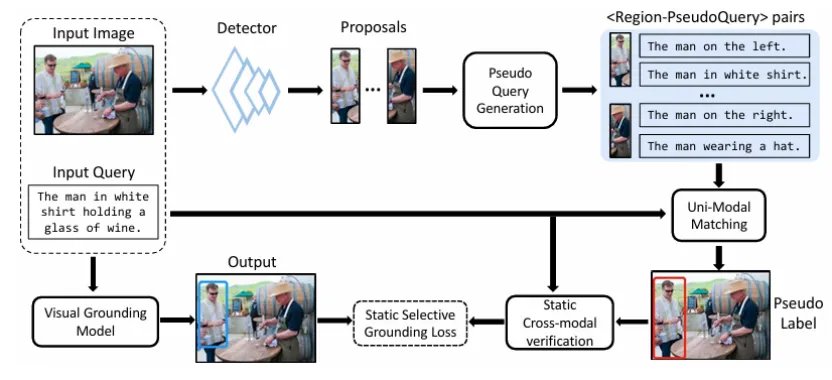
图 1. 置信度感知的伪标签学习框架 CPL
1. 高质量伪查询生成与单模态匹配
由于跨模态匹配的困难,本文转换思路,利用单模态内的匹配构造伪标签。如上图所示,CPL 框架提出了三条互补的生成管线(启发式增强 Heuristic+、以对象为中心描述 Object-Centric、以关系为中心描述 Relation-Aware),为图像中的每个候选区域生成描述性强、真实且多样化的伪查询文本。随后,模型在文本特征空间内计算真实查询与伪查询之间的单模态相似度,挑选最匹配的区域作为初始伪标签,从而避开了跨模态对齐带来的挑战。
2. 静态跨模态验证模块
为了减少虚假关联对模型训练的影响,CPL 框架引入了一个静态跨模态验证模块。该模块利用冻结的预训练视觉 - 语言大模型,在训练前对「区域 - 查询」对进行评估,输出一个静态置信度得分。基于此得分,CPL 通过阈值过滤掉不可靠的关联,有效抑制了错误样本在训练中的负面影响。
虽然 CPL 取得了显著效果,但其验证模块是孤立于定位模型之外的「静态」评估,不仅无法在训练中动态发挥作用,更缺乏对错误关联的「纠正」机制。为此,研究团队进一步扩展得到 CPL++ 框架,在以下核心方面进行了自监督升级。
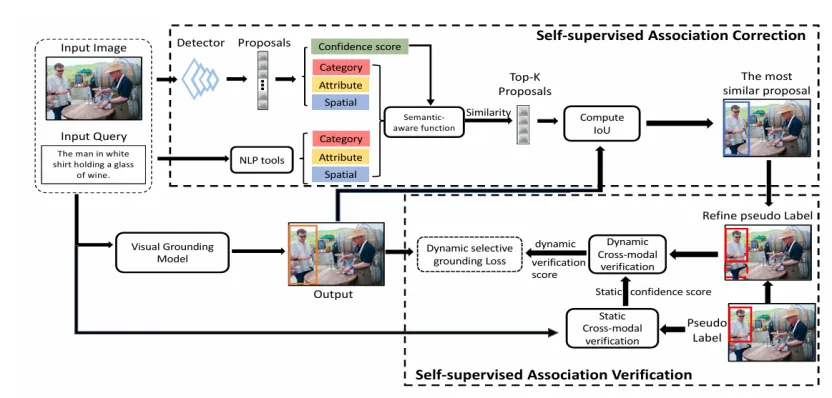
图 2. 置信度感知的伪标签学习框架的进阶版本 CPL++
3. 自监督关联校正与动态伪标签优化
为了纠正错误的「区域 - 查询」关联,CPL++ 进一步引入了自监督关联校正模块。首先,模型不仅仅依赖检测器的置信度,而是结合了查询文本中的类别、属性和空间关系,构建了一个高质量的语义感知候选池。其综合评分函数定义为:

该评估函数综合性地结合了查询文本和候选区域在类别、属性、空间关系上的匹配程度,并结合检测器的置信度,对「区域 - 查询」伪标签提供了全面、可靠的评估手段,用于发现可能错误的「区域 - 查询」关联,过滤得到高质量的伪查询候选池,用于训练模型。
训练过程中,CPL++ 框架动态利用模型的输出对伪标签进行优化。如果模型自身的预测框 与候选池中最优区域
的重合度(IoU)低于阈值
,模型会认为当前关联有误,并动态地将其进行加权融合,生成更精确的新伪标签:
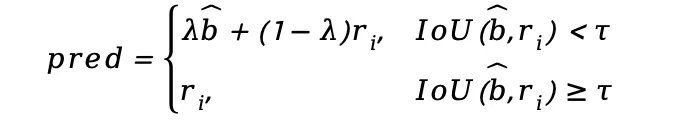
4. 自监督关联验证
除了纠错,CPL++ 将原本孤立的静态验证升级为动态机制。研究发现,随着训练的深入,模型对错误样本(噪声)会产生较大的训练损失。因此,CPL++ 引入了动态选择性定位损失,利用模型当前轮次样本
的训练损失
来动态调整样本权重:
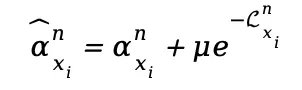
这种自监督验证机制巧妙融合了强大的静态预训练模型的先验知识与不断动态进化的定位模型的能力,降低了误差传播的风险。
实验结果
本文在弱监督视觉定位领域的五大数据集(RefCOCO、RefCOCO+、RefCOCOg、ReferItGame、Flickr30K Entities)上进行了全面评估。
CPL 基础框架在这五个数据集的测试集上超越现有的弱监督与无监督方法。具备自纠错能力的 CPL++ 框架在 CPL 的基础上进一步实现了 2.78%、5.81%、1.08%、2.03% 和 2.55% 的绝对性能提升。CPL++ 框架将弱监督方法与全监督方法之间的性能差距缩小,展现了伪标签自校正机制的巨大潜力。
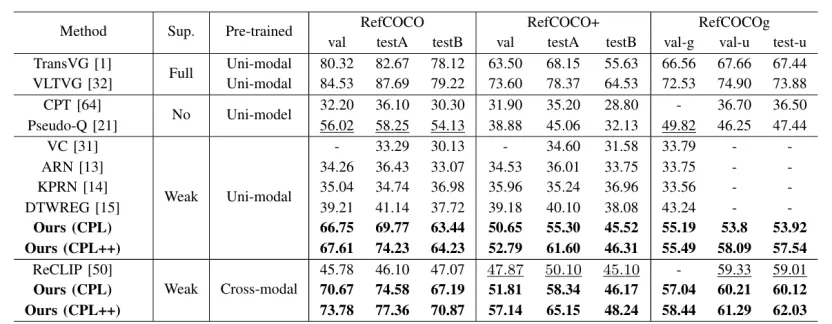
表 1:RefCOCO、RefCOCO+、RefCOCOg 数据集结果

表 2:ReferItGame、Flickr30K Entities 数据集结果
为了进一步直观展示模型生成伪标签的实际效果,图 3 中给出了伪标签的可视化结果,可以看出,CPL 能够为图像候选区域生成描述准确、句式丰富且包含复杂交互关系的高质量伪查询,提供了高度互补的多样化监督信息。此外,图 4 展示了自监督关联校正模块的动态纠错全过程:从图 4(a)中最初建立的初步伪查询关联,到图 4(b)中经过单模态匹配后可能产生的偏差关联,最终在校正模块的干预下,图 4(c)中模型的预测框被成功纠正并精准锁定到了与图 4(d)中的真实文本完全对应的正确目标区域上。这些案例证明了 CPL++ 框架在动态识别并修正错误监督信号方面的强大能力。

图 3:CPL 框架伪标签可视化

图 4:CPL++ 框架自监督关联校正可视化
总结
本文提出了一种弱监督视觉定位框架 CPL++ 。该框架不仅通过单模态匹配建立了更可靠的初始区域 - 文本关联,更重要的是,它为模型赋予了「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。