万帧实时!流式3D重建天花板,被国产开源模型打破了

编辑|杨文
蚂蚁灵波,下了盘大棋。
今年 1 月,蚂蚁灵波一口气开源了 4 款大模型,包括高精度空间感知模型 LingBot-Depth、具身大模型 LingBot-VLA 与具身世界模型 LingBot-VA,以及世界模型 LingBot-World。
其中,LingBot-Depth 负责从图像中估算深度、感知空间距离,LingBot-World 负责对环境进行模拟和理解,LingBot-VLA/VA 负责机器人的决策和动作控制。
这四款模型「各司其职」,分别覆盖感知底层、环境理解和行动输出,但中间一直缺少一个关键环节,就是如何把连续的感知数据实时构建成稳定的三维空间模型,让后续模块有据可依。
现在,这个空缺被填上了。
最近,蚂蚁正式开源 LingBot-Map,一个基于几何上下文 Transformer(Geometric Context Transformer,GCT)的纯自回归的流式 3D 重建基础模型。
它能在几近恒定内存约束下,实现超万帧长视频的实时三维重建,处理速度约 20 FPS,并在多个基准测试中超越了现有流式方法。
LingBot-Map 与最先进的流式重建方法的比较
给定连续视频流,LingBot-Map 可同步输出精确的相机位姿估计与高质量点云。比如真实世界航拍俯瞰,LingBot-Map 保持稳定的定位能力与高精度 3D 重建效果:

即便在穿越多房间的长序列中,面对环境剧变与大幅视角变换,模型依然能表现出极强的鲁棒性:

在生成视频建模场景中,LingBot-Map 与主流生成视频高度兼容,实现稳定的位姿锁定:

针对长序列户外场景,模型在快速运动与频繁视角切换下同样维持了可靠的位姿精度:

建筑环绕场景中,LingBot-Map 则进一步强化了回环重建能力,确保全局一致性:

此次开源内容包括技术报告、核心代码和模型权重,已同步上线 Hugging Face 和 ModelScope 平台。

论文链接:https://arxiv.org/abs/2604.14141
Hugging Face 链接:https://huggingface.co/robbyant/lingbot-map
ModelScope 链接:https://www.modelscope.cn/models/Robbyant/lingbot-map
GitHub 链接:https://github.com/Robbyant/lingbot-map
至此,从单帧深度估计,到纯自回归的流式 3D 重建,再到场景理解和控制输出,一条更为完整的技术链路就此贯通。
机器的空间记忆,为什么这么难?
如果我们在一栋陌生的大楼里转悠二十分钟,能大致描述出刚才走过的路线和空间结构吗?大概率可以。这是因为人类大脑会在行走过程中持续建立空间记忆,把一帧一帧的感官信息整合成一张动态地图。
不过,机器要做到同样的事,难得多。
摄像头可以拍下连续的画面,但把这些二维图像还原成准确的三维空间模型,同时保持实时更新、实时可用,是具身智能和自动驾驶领域长期悬而未决的难题。其难点在于,视频流是没有终点的,历史帧的信息不能丢,当前帧又必须即时处理,而内存还是有限的。
现有方案,大多只能顾一头。
传统 3D 重建方法,比如经典的 SfM(运动恢复结构),通常需要收集完所有帧之后,再进行离线的全局优化。这种离线处理方案精度高,但要等视频录完才能开始算,难以满足实时运行需求。
于是就有了流式重建的思路,让模型在接收每一帧画面的同时,持续更新三维理解,不做事后处理,但现实中有两道坎难以逾越。
一是「灾难性遗忘」。神经网络在处理新输入时,会倾向于覆盖旧有信息。视频越长,模型越容易忘记早期建立的几何关系,导致重建结果在时间维度上前后矛盾、全局漂移。
一是「内存膨胀」。如果想对抗遗忘,最直觉的做法是把历史帧全部保存下来,随时参考。但视频帧数一旦过多,内存就会爆炸。万帧以上的长视频,现有流式方法普遍难以稳定应对。
在这个两难困境里,LingBot-Map 给出了一条不同的路径。

LingBot-Map 流程。该框架处理相对于初始化集 [T, T) 的当前视图。DINO 骨干网络提取图像特征,然后通过交替的帧注意力层和 GCA 层进行细化。在 GCA 模块中,输入视图聚合来自锚点上下文、局部姿态参考窗口 [T, T] 和轨迹记忆上下文的信息。最后,特定任务的头部预测相机姿态和深度图,从而实现对长序列的鲁棒、内存高效的流式 3D 重建。
它是怎么解决「记忆」问题的?
让机器实时看懂三维世界,本质上是个记忆问题,比如记什么、怎么压缩、如何在需要时快速调取。
那么,LingBot-Map 是如何解决这一难题的?这就不得不提一个名为几何上下文注意力(Geometric Context Attention,GCA)的核心机制。
核心机制:几何上下文注意力(GCA)
GCA 的设计灵感,来自机器人领域的经典算法 SLAM。
传统 SLAM 告诉工程师,要让机器人在未知环境里边走边建图,至少需要维护三类空间记忆:锁定坐标系原点的参考帧、捕捉近邻帧几何细节的局部窗口,以及记录全局行走轨迹的稀疏地图。
不过,传统 SLAM 依赖工程师手动编写复杂的几何约束代码,灵活性有限。LingBot-Map 研究团队换了条路,将这些空间规律内化到 Transformer 的注意力机制中,利用因果注意力(Causal Attention)确保模型只利用过去和当前的信息,完全符合机器人边走边看的实时逻辑。
几何上下文注意力(GCA)在处理视频流时,同时维护三类记忆。
第一类是锚点(Anchor),负责记住「我从哪里出发」。它为整个三维坐标系提供稳定基准,空间重建最怕坐标漂移,有了锚点,模型在处理第一万帧时,仍然清楚第一帧发生在什么位置。
第二类叫位姿参考窗口(Pose-reference window),负责捕捉当前位置附近的局部几何细节。这相当于对「我身边有什么」保持清醒的即时感知,保证了逐帧重建的精度。
第三类为轨迹记忆(Trajectory memory),这是整个架构中较为关键的设计。它把庞大的历史信息压缩成极其紧凑的逐帧 Token,以较低的存储代价保留对过去路径的「印象」。正是这一机制,让 LingBot-Map 的内存消耗几乎不随视频长度增长,处理 100 帧和处理 10000 帧,总的计算量和内存占用维持在几近相同的水平。
三类记忆协同工作,让模型在处理当前画面时,能同时调取空间基准、局部细节和历史轨迹。整套机制端到端可学习,模型在训练中自动习得如何分配和压缩信息,不依赖人工设计的规则。
这种设计带来的效率提升相当可观。以一段万帧视频为例,如果采用朴素的因果注意力缓存所有历史,模型需要维护约 500 万个 token,而 GCA 只需要约 7 万个,足足压缩了近 80 倍,且每处理一帧新画面,计算量和内存消耗几乎不随总帧数增长。
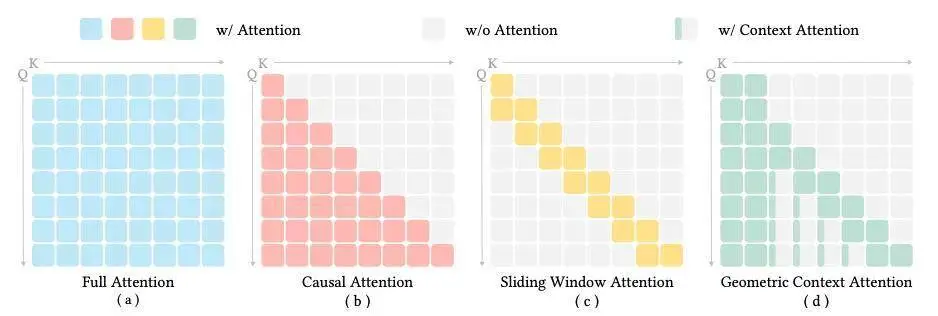
注意力掩码比较。每个方框代表一帧的 Token,由一小段上下文 Token 和一段较大的图像 Token 组成。(a) 全注意力(Full attention)会关注所有帧。(b) 因果注意力(Causal attention)支持流式处理,但计算开销随序列长度线性增长。(c) 滑动窗口注意力(Sliding-window attention)虽然限制了计算成本,但会丢失长程上下文。(d) GCA 将流式上下文划分为锚框 (n=2)、局部窗口 (k=2) 和轨迹记忆,在保持计算成本随序列长度增加而近乎恒定的同时,保留了丰富的长程上下文信息。
如何教会机器「有选择地记忆」?
有了 GCA 机制,还需要配套的训练与推理策略,才能让模型学会在长序列中稳定工作。
直接在长序列上进行训练极具挑战性。早期帧的位姿误差会沿轨迹传播,破坏损失函数的稳定性,导致优化速度缓慢甚至发散。为此,LingBot-Map 采用渐进式视图训练策略:模型从短子序列开始,并在训练过程中逐步增加视角数量,训练视图数量从 24 帧线性递增至 320 帧,让模型先在短序列中获得可靠的局部几何估计,再学习如何在逐渐延长的轨迹上保持全局一致性。
随着训练序列长度的增加,跨帧注意力的计算复杂度呈平方级增长,GPU 内存成为主要瓶颈。对此,LingBot-Map 引入了上下文并行策略,将不同视图分布至多张 GPU,通过高效的全局通信实现并行注意力计算,从而在不牺牲序列长度的前提下完成大规模训练。
损失函数同样经过精心设计,LingBot-Map 采用一个复合损失函数来训练,该函数由深度损失、绝对位姿损失与相对位姿损失组成。模型采用相机到世界坐标系的变换进行监督,规避了世界到相机参数化中旋转与平移耦合带来的误差放大问题。此外,视频时序位置编码将帧序信息注入轨迹记忆 Token,使模型能够感知历史帧之间的时间距离,更有效地抑制长程漂移。
推理层面,LingBot-Map 借鉴自回归大语言模型的 KV 缓存机制,并通过分页 KV 缓存布局避免频繁内存重分配的开销,配合 FlashInfer 框架的稀疏注意力优化,最终在 518×378 分辨率下实现约 20 FPS 的实时推理,相比 PyTorch 基线提速近一倍。
在基准测试上,它表现如何?
LingBot-Map 团队建立了一个全面的评估基准测试,涵盖相机位姿估计与 3D 重建两大任务,横跨室内、室外及大规模场景,结果均显著优于现有流式方法。
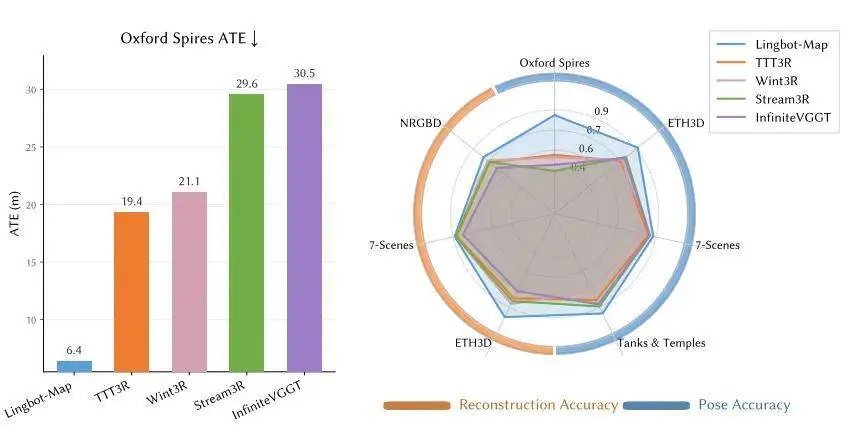
在相机位姿估计方面,Oxford Spires 是一个涵盖复杂室内外环境、场景变化显著的大规模数据集,是检验流式方法长序列鲁棒性的严苛标准。

轨迹对比。(a) 在 Oxford-Spires 场景中,LingBot-Map 甚至优于双向 (DA3-Giant) 和基于优化的方法 (ViPE),能够在复杂的室内外过渡和昏暗楼梯中准确地保持轨迹。(b) 在 Tanks and Temples 以及其他 Oxford-Spires 场景中,LingBot-Map 方法始终能够生成准确的轨迹,而其他流式方法则存在严重的轨迹漂移。蓝色为真实轨迹,橙色为预测轨迹;起点为圆点 (●),终点为叉号 (×)。
在稀疏设置(每隔 12 帧采样,共 320 帧)下,LingBot-Map 在几乎所有指标上取得最优成绩,AUC@15 达到 61.64,AUC@30 达到 75.16,绝对轨迹误差(ATE)仅为 6.42,这一数字不仅大幅领先所有在线方法,甚至超越了需要访问全部帧的离线方法,以及依赖迭代优化的方法。这一结果充分说明,GCA 机制在长序列中的全局一致性保持能力已不输于后处理优化。
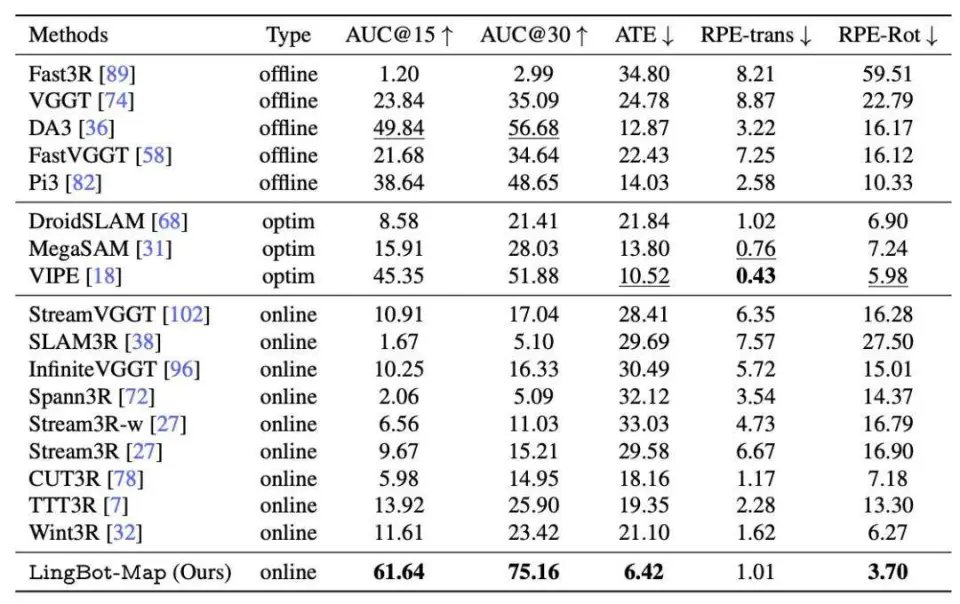
Oxford Spires 数据集上的位姿与轨迹精度对比。在与先前的离线方法、基于优化的方法以及在线方法的对比中,LingBot-Map 的方法在绝大多数指标上均实现了最优性能。
在密集设置(完整 3840 帧序列)下,大多数流式方法因轨迹漂移而性能大幅劣化,比如 CUT3R 的 ATE 从 18.16 升至 32.47,Wint3R 从 21.10 升至 32.90。相比之下,LingBot-Map 始终保持较低的误差,ATE 仅从 6.42 小幅升至 7.11,在序列长度增加 12 倍的情况下,误差仅略微增加了 0.69,表现出极强的长程稳定性。LingBot-Map 还实现了 20.29 FPS 的极具竞争力的推理速度,同时在所有流式方法中保持了最佳的轨迹精度。

在 Oxford Spires 数据集上关于稀疏(Sparse)轨迹与稠密(Dense)轨迹的精度对比。研究者对比了在稀疏设置(320 帧)和稠密设置(3840 帧)下的绝对轨迹误差(ATE),衡量了从稀疏到稠密设置下的精度退化程度。LingBot-Map 保持了近乎恒定的精度,而其他方法则出现了明显的退化。
在 ETH3D、7-Scenes 和 Tanks and Temples 三个数据集上,LingBot-Map 同样全面领先。以 ETH3D 为例,其 AUC@3 达到 27.79,AUC@30 达到 86.20,ATE 低至 0.22;在 Tanks and Temples 上,AUC@30 高达 92.80,ATE 仅为 0.20,均为各方法中最优。
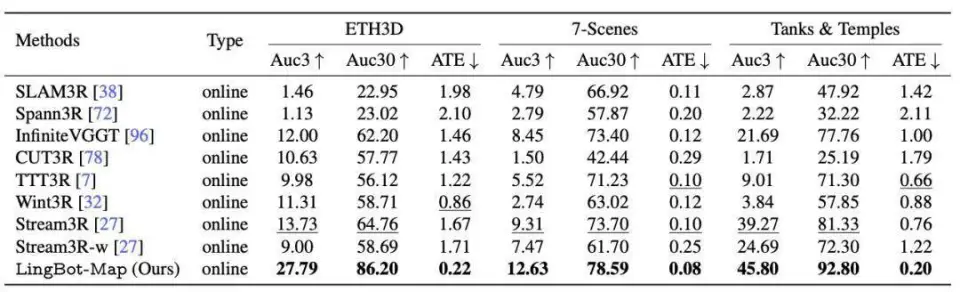
ETH3D、7-Scenes 和 Tanks & Temples 上的位姿与轨迹精度对比。在 ETH3D、7-Scenes 和 Tanks & Temples 数据集上的结果表明,LingBot-Map 方法在所有数据集上均取得了最佳性能。
除了数值指标之外,该团队还提供了重建质量的定性比较。在长时间间隔后重新访问场景时,LingBot-Map 的方法表现出最小的漂移,能够生成清晰一致的建筑结构重建结果。相比之下,其他方法由于记忆遗忘而出现严重的轨迹漂移和点云碎片化。这证明了 LingBot-Map 几何上下文注意力机制在保持长序列一致性方面的有效性。

点云重建的定性比较。
三维重建方面,在 ETH3D 上,LingBot-Map 的 F1 得分为 98.98,比次优方法 Wint3R 高出 22.7 个百分点;在 NRGBD 数据集上,F1 得分达到 64.26,同样大幅超过 StreamVGGT 和 TTT3R 等方法。精度与完整度的双重提升,表明模型在保持重建准确性的同时,对场景覆盖率也有更充分的保障。
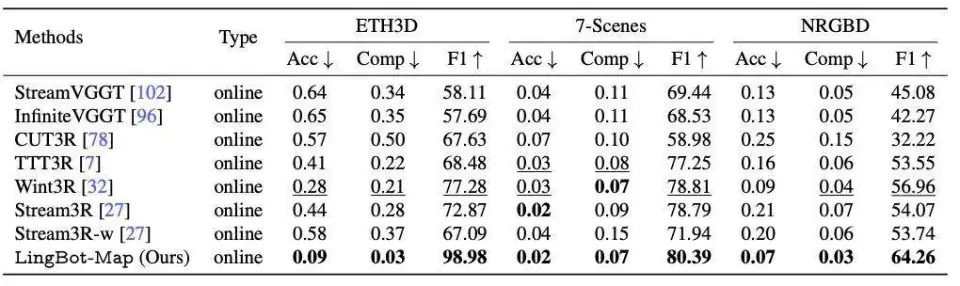
ETH3D、7-Scenes 和 NRGBD 上的点云重建对比。LingBot-Map 方法在准确率、完整性和 F1 分数方面均取得了最佳结果。
消融实验进一步验证了各组件的贡献。
单独加入锚点初始化可将 AUC@3 从 9.80 提升至 13.63,ATE 从 8.59 降至 7.88;引入相对位姿损失对帧间旋转误差的约束尤为关键,去掉后 RPE-rot 从 2.26 恶化至 5.35;而上下文 Token 与视频 RoPE 的联合引入则进一步将 AUC@3 提升至 16.39,ATE 降至 5.98,说明对全局轨迹信息的精确编码是长程一致性的重要保障。
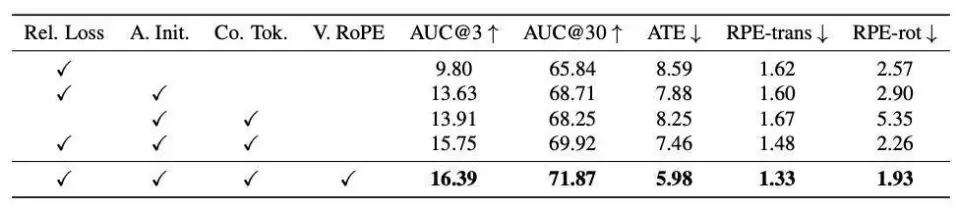
长序列姿态估计和轨迹精度的消融研究。所有组成部分均对最终性能有显著贡献。
效率分析方面,将位姿参考窗口限定为 64 帧而非保留全部历史,不仅将推理速度从 11.87 FPS 提升至 20.29 FPS,显存占用从 36.06 GB 降至 13.28 GB,ATE 也从 6.60 进一步下降至 5.98,这表明 GCA 所保留的精选几何上下文,其信息密度实际上高于不加筛选的完整历史缓存,在效率与精度上实现了双赢。

姿态参考窗口与全窗口的效率比较。姿态参考窗口(大小为 64)在显著提高速度和降低内存占用的同时,实现了更高的精度。
结语
纯自回归流式 3D 重建,是具身智能领域公认的技术难点之一。此前,业内方案普遍面临实时性与内存占用难以兼顾的困境,制约了具身系统在复杂、长时任务中的实际表现。
LingBot-Map 的开源,为这一问题提供了一个可复现、可验证的解法,也将相关技术门槛向下拉了一档。
从更大的视角来看,这也是蚂蚁灵波具身大脑平台趋于完整的一个节点。深度感知、场景理解、决策控制等模块此前已陆续开源,LingBot-Map 的加入,补上了实时空间建模这一关键缺口。一套具身大脑该有的模块,正在逐渐变得完整。
当然,具身智能真正成熟,还需要无数真实场景的打磨和验证,但这类基础能力的开放共享,或将对整体研发节奏产生实质性影响。
文中视频链接:https://mp.weixin.qq.com/s/w_Vt1AylNX9WH3NBaKmUwA