ACL 2026|答得更准还写得更短?华为泰勒实验室提出SHAPE,给LLM推理装了个「推理税」
用强化学习训练大模型做数学推理,一个经典的尴尬局面是:模型要么答对了但废话连篇,要么写了一大堆最后答错了,而你根本不知道它到底在哪一步走偏的。
来自华为泰勒实验室、北京大学和上海财经大学的研究团队提出了 SHAPE(Stage-aware Hierarchical Advantage via Potential Estimation),给推理链装上了一套「里程碑 + 推理税」机制——不仅告诉模型每一步推得对不对,还让它为啰嗦付出代价。结果是:准确率平均提升 3%,token 消耗直降 30%。
该工作已被 ACL 2026 主会接收。

论文标题:SHAPE: Stage-aware Hierarchical Advantage via Potential Estimation for LLM Reasoning
论文链接:
1. 痛点:模型推理的「稀疏信号」困境
目前强化学习的主流做法(GRPO)只在推理链的最末尾给一个对/错的信号。这就好比一个学生写了三页解题过程,老师只在最后批一个「❌」——学生完全不知道自己哪一步出了问题。
过程奖励模型(PRM)可以给每一步打分,但标注成本极高,而且模型容易钻空子(reward hacking)。近年来 MRT、SPO 等方法另辟蹊径:通过让模型在推理中间多次「快速试答」来估计当前走到哪了,以此构造中间信号。但这些方法各有各的短板。
团队认为,一步好的推理应该同时满足三件事:1️⃣ 得有实质进展(不能原地踏步)、2️⃣ 越难的阶段突破越值钱(雪中送炭>锦上添花:困惑时的突破更重要)、3️⃣ 越简洁越好(同样的进展用更少的字完成应该得到奖励)。
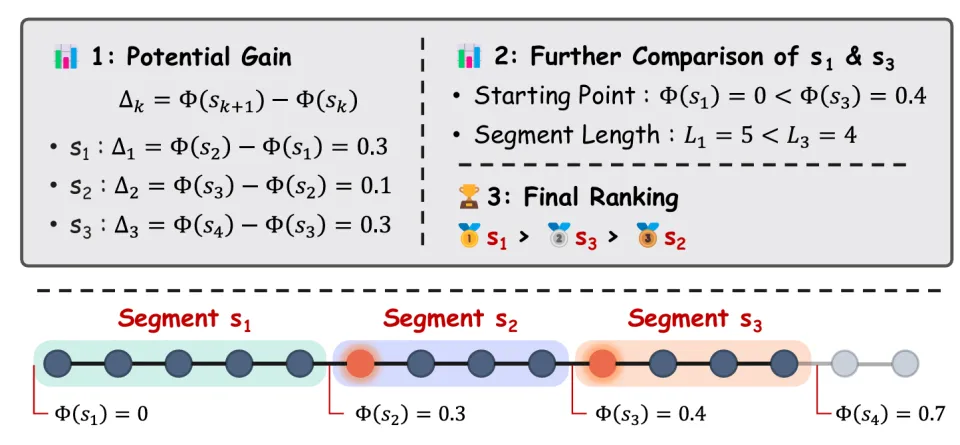
现有方法要么只管进展不管效率,要么只加长度惩罚但缺乏语义引导。SHAPE 就是为了把这三件事统一到一个框架里。
2. SHAPE 怎么做的?
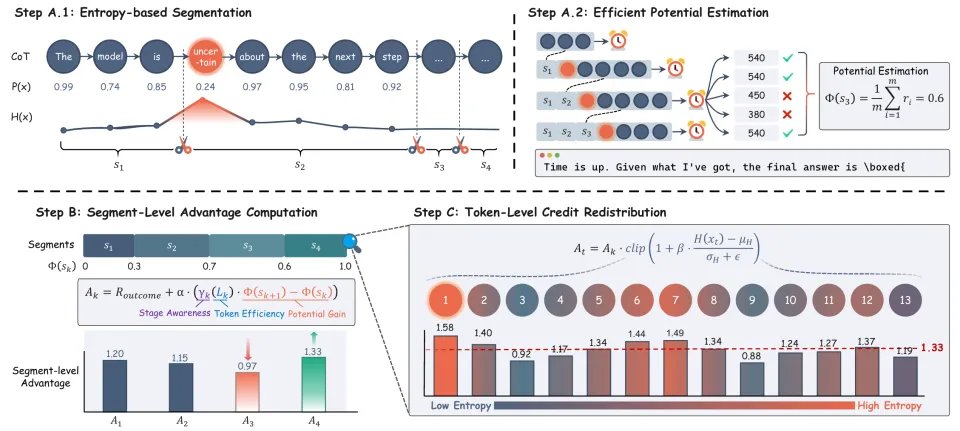
整个框架分三步走:(A)切段+估势能 → (B)段级奖励计算 → (C)token 级信用再分配。
Step A:切段 + 估「推理势能」
先把推理链按语义切成个段落。切在哪?用每个 token 位置的预测熵来决定——熵高的地方说明模型正在犹豫「接下来该走哪条路」,这些位置就是天然的逻辑分叉点,比用换行符硬切靠谱得多。
切完之后,在每个段落边界处做
次短 rollout:把已有推理当 prompt,让模型快速尝试给出最终答案,统计答对率,就是该位置的推理势能:
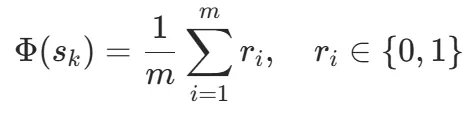
打个比方:8 次试答对了 6 次,,模型此刻有七成半把握做对;只对 1 次,
,还在迷雾里。相邻段落的势能差
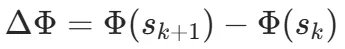 直接反映了这段推理有没有实质推进。
直接反映了这段推理有没有实质推进。
工程上,团队用vLLM的Prefix Caching避免重复算共享前缀,rollout限制在max_tokens=16,开销可控。
工程上,团队用 vLLM 的 Prefix Caching 避免重复算共享前缀,rollout 限制在 max_tokens=16,开销可控。
Step B:段级奖励——「推理税」机制
有了势能,怎么变成 RL 能用的奖励?这里借鉴了经典的势函数奖励塑形(PBRS):在每一步构造一个额外奖励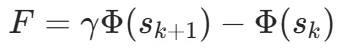 ,势能涨了就给正反馈,跌了就罚。当
,势能涨了就给正反馈,跌了就罚。当是常数时,理论保证不改变最优策略。
但 LLM 推理有个特殊问题:原始策略倾向「写多保平安」。所以团队把固定换成了跟段落长度挂钩的动态折扣——段落越长折扣越狠:
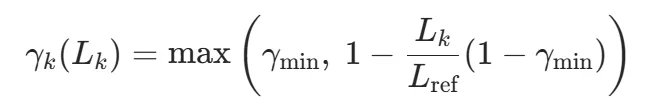
代入后,每段的优势函数为:
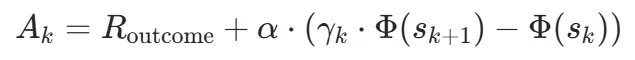
其中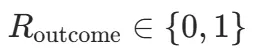 是最终答案对错,
是最终答案对错,是过程奖励系数。对塑形项展开,会出现一个很漂亮的结构:
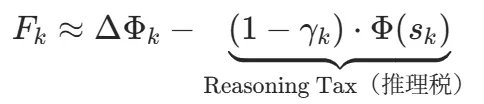
第二项就是「推理税」,它同时干了两件事:税基是当前势能——推理早期势能低,税几乎为零,放心探索;后期势能高,税就重了,不许靠反复确认来刷分。税率跟段落长度正相关——越啰嗦税越高,逼模型精练表达。一个动态折扣因子,同时搞定了阶段感知和效率约束。
Step C:token 级信用再分配
段级还是粒度太粗,关键决策 token 和抄题 token 不该拿一样的信号。SHAPE 在段内用 token 预测熵做 Z-score 标准化得到重要性权重
,最终每个 token 的优势值为:
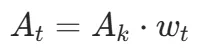
高熵的关键决策点,信号放大;低熵的常规 token
,保持不变。这种调制锚定在段级优势这个局部、密集的信号上,比直接在全局 outcome reward 上做 token 级调制稳定得多。
3. 实验结果
3.1 主实验
三个基座模型(DeepSeek-R1-Distill-Qwen-1.5B、DeepScaleR-1.5B、Qwen3-4B),五个数学推理 benchmark,全面评估。
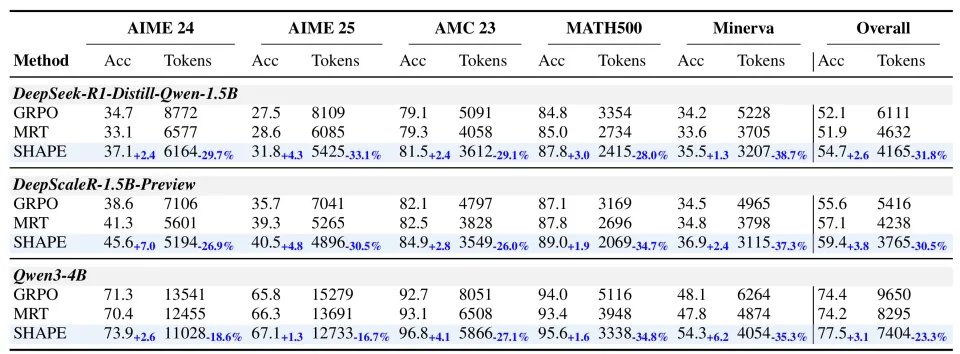
跨模型一致性: 无论 1.5B 还是 4B 规模,SHAPE 均同时提升准确率并降低 token 消耗。
准确率: Overall 平均提升约 3%,其中 DeepScaleR-1.5B 在 AIME 2024 上提升 7.0 个百分点(38.6% → 45.6%),Qwen3-4B 在 MinervaMATH 上提升 6.2 个百分点。
Token 效率: Overall 平均减少约 30%,最大降幅达 38.7%(DeepSeek-1.5B on MinervaMATH)。
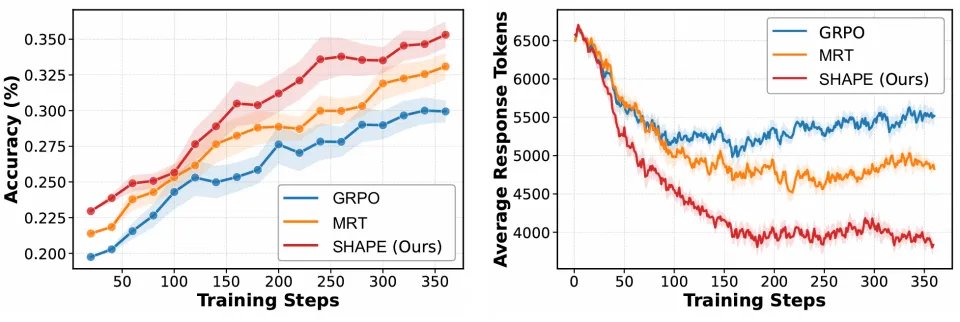
训练曲线进一步佐证了这一结论:SHAPE 在训练全程保持准确率领先,同时驱动 response 长度持续下降,两条曲线的走势完美体现了又准又快的双重优化目标。
3.2 消融实验
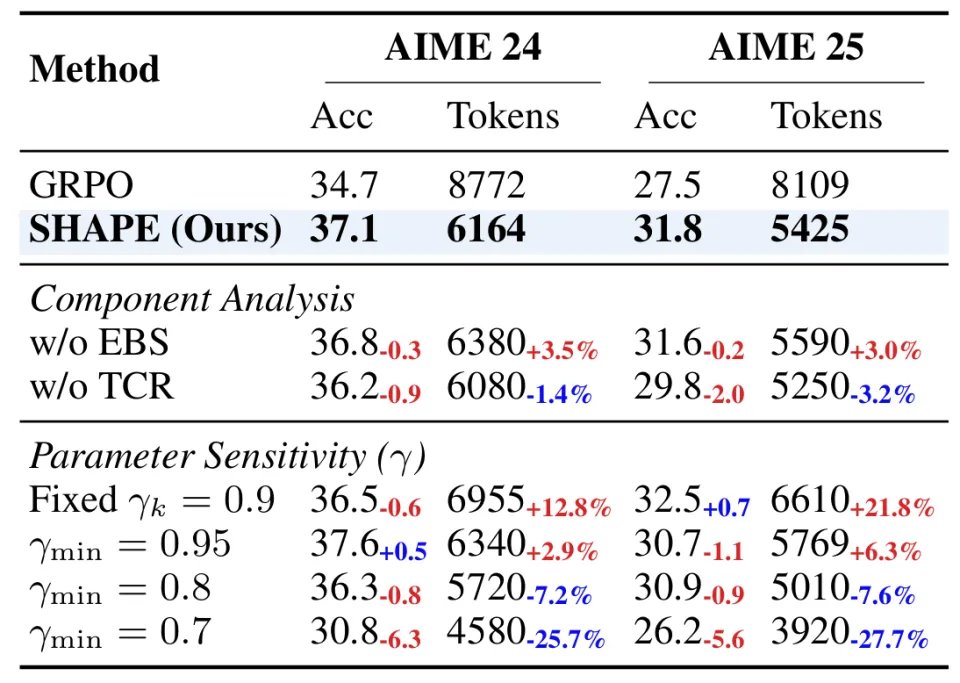
消融实验揭示了几个关键发现:
熵分段(EBS)的移除导致 token 消耗增加约 3%,验证了语义对齐的分段策略优于硬规则。
Token 级信用再分配(TCR)的移除导致准确率下降达 2.0 个百分点(AIME 2025),表明细粒度信号在关键决策点的放大作用不可或缺。
的灵敏度:
![]() 为最佳平衡点;过于宽松(0.95)导致 token 膨胀,过于激进(0.7)则引发性能崩溃——模型为了逃避「推理税」而过早截断推理链,产出「短但错」的答案。
为最佳平衡点;过于宽松(0.95)导致 token 膨胀,过于激进(0.7)则引发性能崩溃——模型为了逃避「推理税」而过早截断推理链,产出「短但错」的答案。
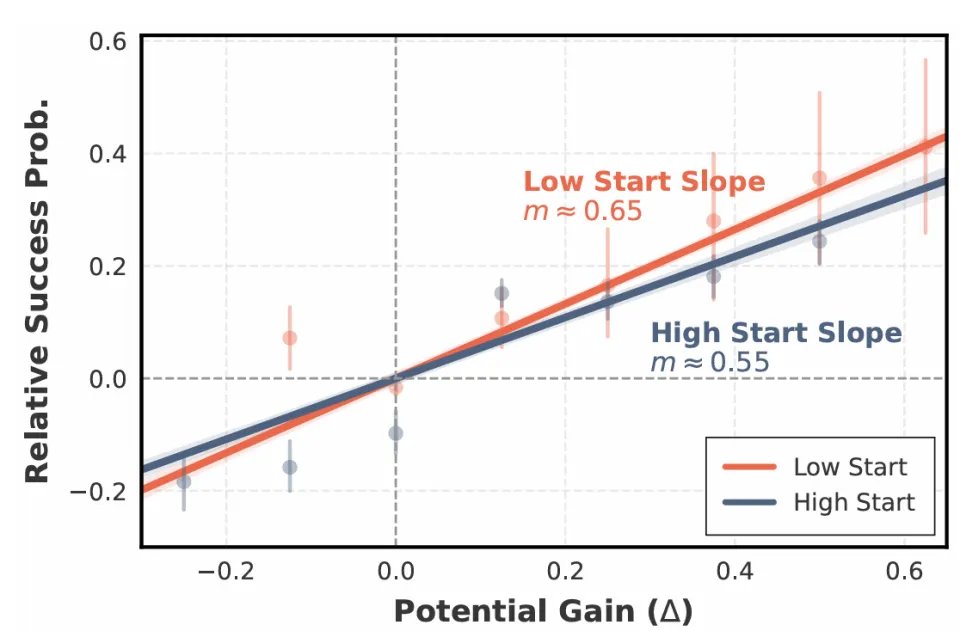
4. 深度分析
阶段感知验证。 团队对约 41 万条 segment 转移数据做了回归分析:低势能起点()上实现的势能增益,对最终正确率的边际贡献比高势能起点(
)高出约 18%。
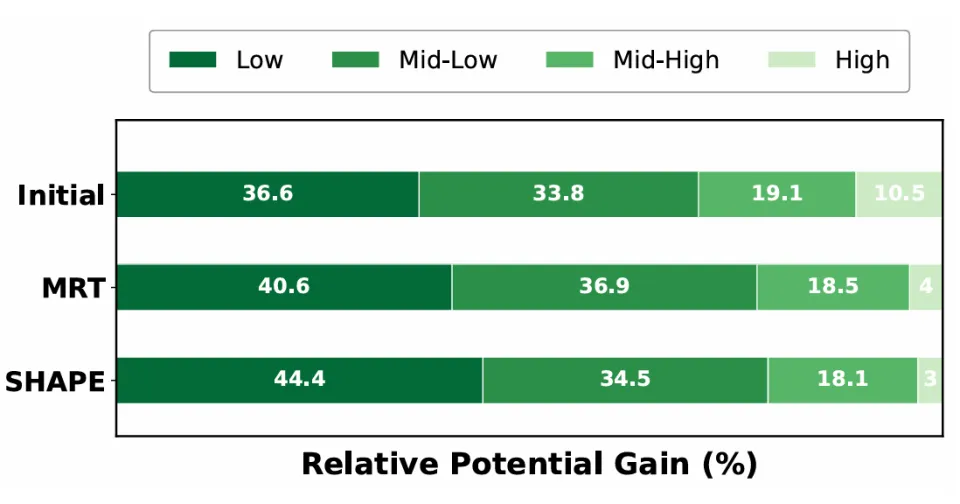
进一步地,经过 SHAPE 训练后,模型在势能增益来源分布上呈现了显著变化:来自低势能状态的增益贡献占比从初始的 40.6% 上升到 44.4%,而来自高势能状态的贡献从 10.5% 降至 3%。模型学会了把脑子🧠集中在最需要突破的地方。
自适应计算。 SHAPE 按题目难度动态分配 token 预算,长度-难度缩放斜率比 GRPO 更陡、方差更小,这意味着:SHAPE 不是简单地「写得少」,而是精准地根据题目难度分配 token 预算。
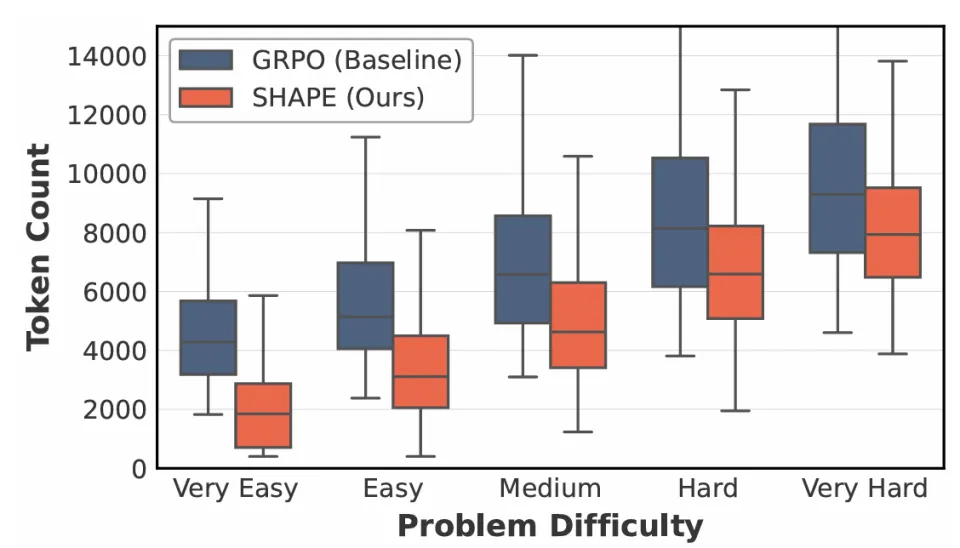
消除推理坍缩。 GRPO 在难题上存在一个显著的病理现象:response 长度分布在 32k 上下文上限处出现异常 spike。SHAPE 基本消除了这类现象——分布曲线在远低于上限处就平滑衰减至零。这进一步印证了推理税的效力:当模型在某条推理路径上持续消耗 token 却无实质进展时,累积的税会迫使模型及时止损。
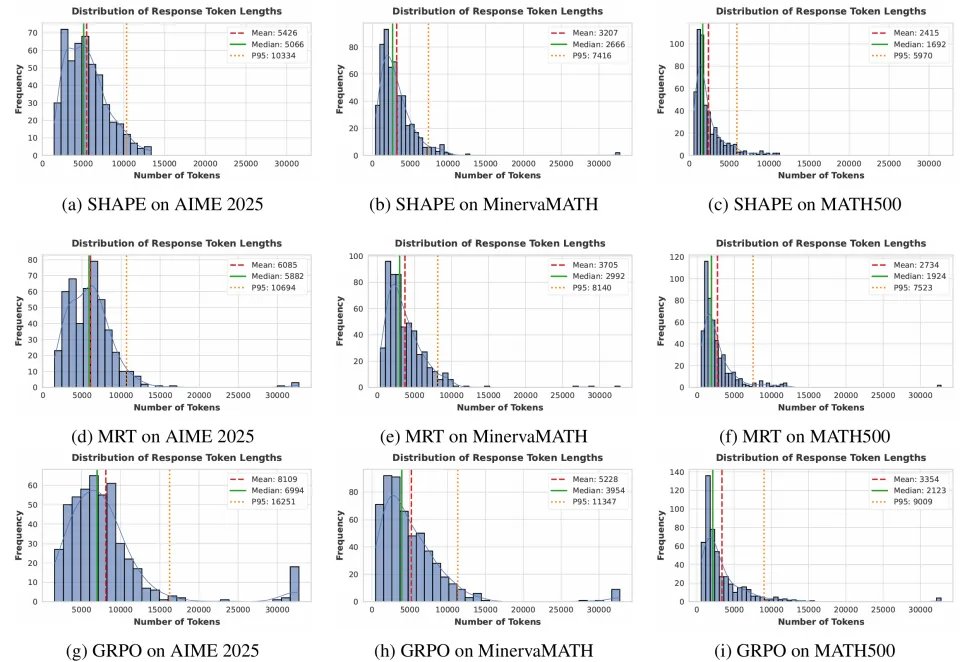
5. 总结
SHAPE 用一个统一的数学框架——动态折扣的势函数塑形——同时解决了过程监督中的三个核心问题:势能增益度量、阶段难度感知和 token 效率约束。SHAPE 的核心贡献不仅在于具体的准确率和效率数字,更在于提出了推理税这一优雅的机制设计范式,为理解和优化 LLM 推理过程提供了新的理论透镜。