CVPR 2026 Highlight | 超越传统检索方法!我们的激光雷达重定位方法在精度和效率上双丰收
在自动驾驶的日常测试视频里,我们常能看到这样的场景:
一辆无人车驶入幽深的地下车库,GPS 信号瞬间罢工,它只能靠激光雷达扫描周围环境,试图弄清楚 “我在哪”。然而,车辆可能已经原地掉头,拐过了好几个弯,周围只有冰冷的墙壁和立柱。就像你蒙上眼睛转了几圈,再睁开眼,面对一片空白的天花板,要准确说出自己面对的方向和所处的位置。
激光雷达重定位要解决的正是这个难题:仅凭一帧点云片段,估计出自己在全球坐标系中的 6 自由度位姿。
目前主流方法遵循 “检索 - 配准” 范式,其精度可达分米级,但其存储和计算压力会随场景规模急剧膨胀;另一种使用神经网络直接预测位姿的方法(包括 APR 和 SCR),可实现十毫秒级的迅速响应,但其对角度敏感,精度仅在亚米级。就像天平的两端,精度和效率似乎难以兼得,但
我全都要!厦门大学、布里斯托大学联合提出激光雷达重定位方法 LEADER,不仅实现十毫秒级的 “睁眼” 即定位,而且精度超越传统的 “检索 - 配准” 方法!
这项工作已被 CVPR 2026 接收为 Highlight,代码和模型将全面开源!

论文标题:LEADER: Learning Reliable Local-to-Global Correspondences for LiDAR Relocalization
论文链接:https://arxiv.org/abs/2604.11355
仓库链接:https://github.com/JiansW/LEADER
从效率专长,到效率性能两开花
场景坐标回归(SCR)方法在预测位姿时不需要显式存储地图,而是使用神经网络预测场景点的世界坐标,再通过 RANSAC 类方法预测当前的位姿。由于采用了 RANSAC 类几何约束,在稳定性方面通常优于绝对位姿回归(APR)方法。
相比传统的 “检索 - 配准” 模式,SCR 省去了显式存储点云特征的开销,也不会因地图增大导致存储和计算成本飙升。但长期以来,SCR 方法精度维持在米级到亚米级,和 “检索 - 配准 “方法相比呈现明显的劣势。于是作者提出了一个问题:
SCR 方法精度上真的无法比拟 “检索 - 配准” 方法吗?
这是论文出发的核心:既然 SCR 在存储开销和计算延迟上都存在明显的优势,如何让其在保留这些优势的基础上,精度比肩甚至超越 “检索 - 配准” 方法?
作者发现,有两个明显影响 SCR 精度的因素:
旋转敏感:汽车在行驶过程中,如果转个弯,精度会大幅下降,甚至会从亚米漂移到 10m 开外;
退化区域:环境中存在大量的噪声和重复结构区域,比如长直走廊、空旷的地面等。要在这些高度相似的区域中找到其对应的世界坐标,就像让人盯着白墙找指纹,只会输出一堆 “幻觉对应”。
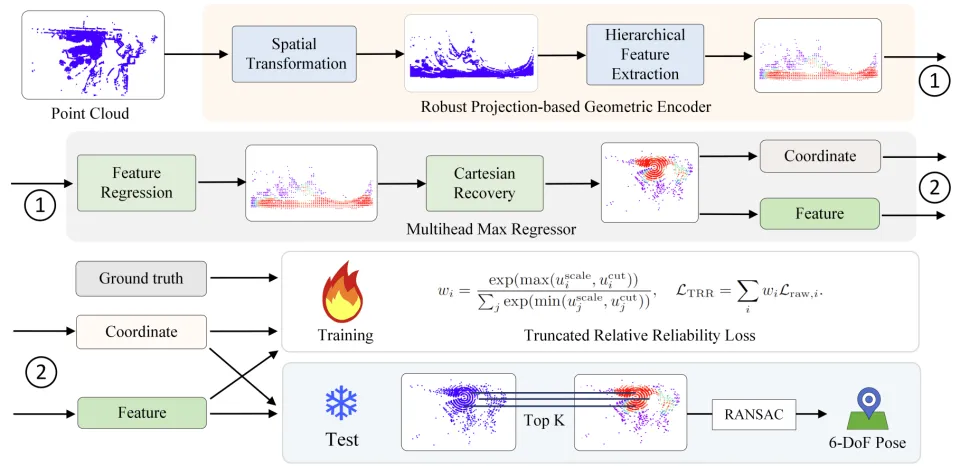
图 1:LEADER 框架图
LEADER:让点云 “转不晕”,
让坏点 “靠边站”
作者提出的 LEADER 框架,用以下几乎零开销的组件解决了以上痛点:
柱面投影 + 循环稀疏卷积(Spatial Transformation + Cartesian Recovery):在自动驾驶中,旋转问题往往集中在偏航角上。因此作者将点云进行柱面投影,并辅以循环稀疏卷积来处理角度衔接的问题,从而实现对偏航角不变的特征,不管车头朝南还是朝北,都拥有同一套稳定表示。此外,通过检测地面点来将点云校正至水平,获得了一定的俯仰角和横滚角鲁棒性。
TRR 损失(Truncated Relative Reliability Loss):每个点的质量不同,预测的难易程度差距很大,但我们不可能为场景中的每个点去人工标注质量信息。实际上,哪些点难以预测,模型在训练时就已经 “告诉” 我们了,那就是每个点训练时的欧氏距离损失。因此,在预测世界坐标的同时,作者还让模型预测每个点 “好不好预测”,即 “置信度”。对于容易预测的点,置信度更高,反之则低。
那么,如何让模型在无置信度相关真值的情况下实现置信度的预测呢?作者设计了以下的 TRR 损失:
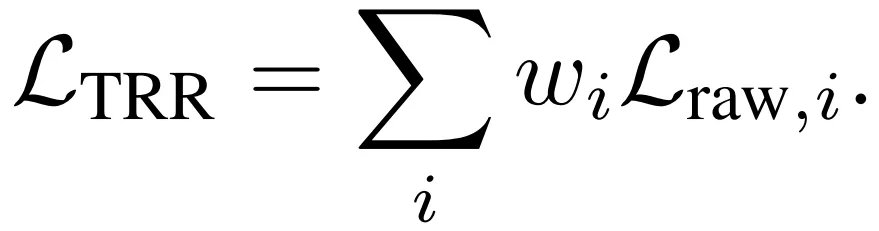
等号右侧的求和符号内,是每个点的训练权重 w 和其欧氏距离损失 L 相乘。而训练权重则是由置信度归一化得到的,这就相当于给模型指明了一条路:
如果某个点很难精准预测,即损失很难下降,那么模型可以给其输出一个很低的置信度,这样该点的训练权重就会降低,最终降低总损失。而在置信度归一化的过程中,作者限制了其范围,这避免置信度范围过大,从而出现模型只专注于学习少数点的问题。
在 RANSAC 阶段,作者选择高置信度的点来拟合位姿,进一步削弱了 “坏点” 的影响。
实验结果:全面领先
在 NCLT 数据集上,LEADER 大幅超越了当前的隐式神经网络方法(APR 和 SCR),定位精度从 APR 的 1.19 m 和 SCR 的 1.51 m 提升至 0.31 m:
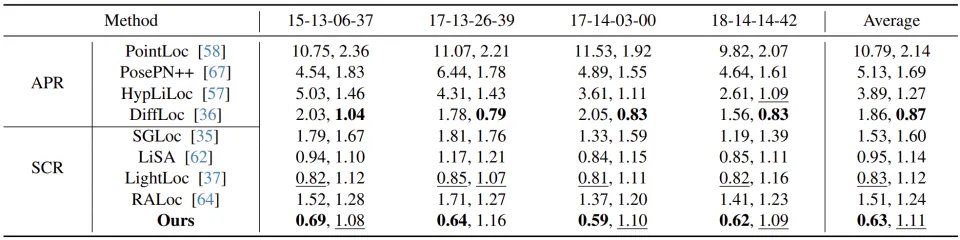
表 1:NCLT 数据集上的实验结果
作者还与同样具有旋转鲁棒性的 “检索 - 配准” 方法 RING/RING++ 进行了对比,并取两种方法中最优值作为参考。在同样 xy 平面上的定位精度中,LEADER 的平均定位精度达到 0.28 m,大幅超越了 RING/RING++ 方法;5 m 内的失败率仅 0.28%,不到 RING/RING++ 失败率的 1 / 25,甚至在基本不受失败率影响的中位数上,LEADER 的 0.21 m 也明显领先:
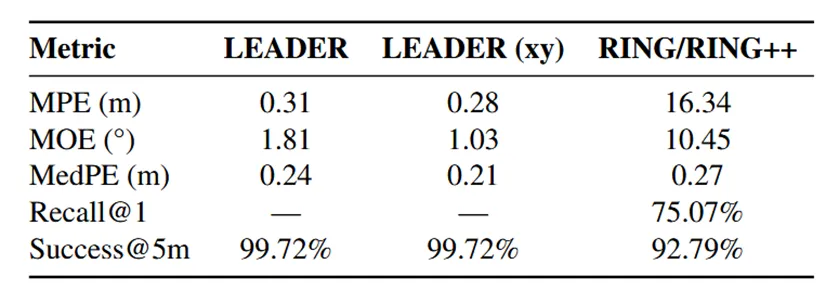
表 2:与 “检索 - 配准” 方法的对比结果
置信度分析:
让模型学会 “有所取舍”
在 NCLT 数据集上,旋转问题并不突出,为什么 LEADER 仍然有如此大的提升?TRR 损失引入了置信度信息,作者对该模块进行了分析,首先对测试集中所有点按其置信度进行了排序,并绘制了点的置信度和预测误差之间的关系:
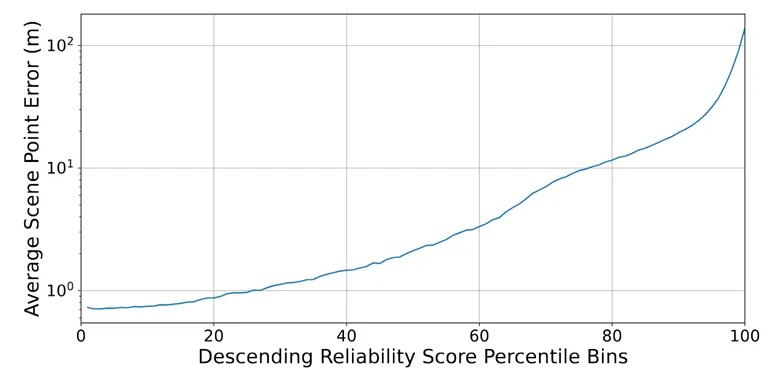
图 2:点置信度与预测误差的关系
可以看到,两者呈现明确的反相关,说明在预测阶段置信度信息非常有效。而预测阶段仅使用置信度高的点也进一步排除了 “坏点” 的影响。
作者还将 TRR 和常规的欧式距离损失进行了对比:
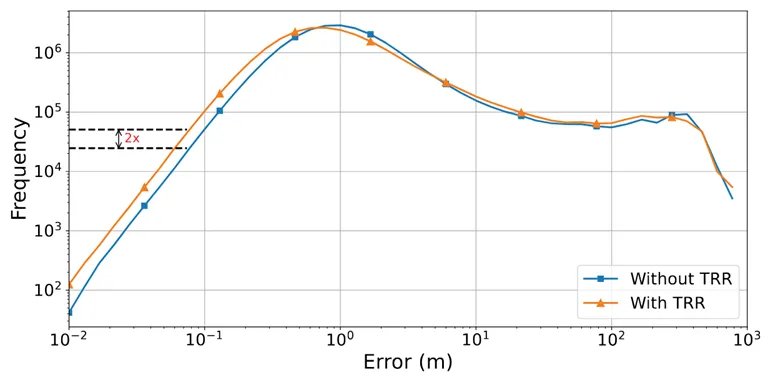
图 3:TRR 模块的消融实验
结果表明,TRR 损失不仅能让模型在训练中自适应调整每个点的权重,从而实现置信度预测,而且使预测出的高精度点的比例翻倍。
后记
这给了我们一个启示,在并不需要完整记忆所有内容的场景中,与其让模型去死记硬背那些难以学习的数据,不如让模型自己选择应该记住什么。因为参数一旦确定,模型的记忆容量就是固定的,“坏点” 会消耗模型大量的容量去尝试记住它们,结果不仅记不住,反而会干扰训练,影响 “好点” 的数量。
有时候,模型并非越复杂越有效,核心模块往往恰恰是其中简单的部分,如果能分析出模型的瓶颈因素,并为其 “引流”,即可能引发质变,简约而不失优雅。
作者介绍
本文第一作者来自厦门大学信息学院空间感知与计算实验室(ASCLab)2023 级硕士生吴建实,通讯作者为厦门大学敖晟助理教授,并由朱明航、刘敦强、李文(布里斯托大学)、沈思淇副教授、温程璐教授、王程教授共同合作完成。研究团队长期聚焦定位相关的算法研究。
实验室主页:https://asc.xmu.edu.cn/