Agent-World:扩展真实世界环境,让智能体与环境协同进化!
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。除此以外,训练环境造得再多,当智能体在面临新的交互环境时,若缺少持续学习的训练算法依旧很难具备泛化性。
为此,本文提出Agent-World:一个通用智能体训练场,将“智能体环境探索”与“自进化训练”相结合,形成智能体与环境协同进化的闭环。
Agent-World由两个核心模块构成:
(1)智能环境-任务探索:通过深度研究智能体,围绕真实世界环境主题,自主从互联网挖掘环境数据库、生成可执行工具和可校验任务。
(2)持续自进化训练:通过多环境强化学习训练智能体,并将合成环境视作天然的训练场,自动诊断智能体的能力短板,针对性地推动环境/任务扩展,实现智能体的自进化。
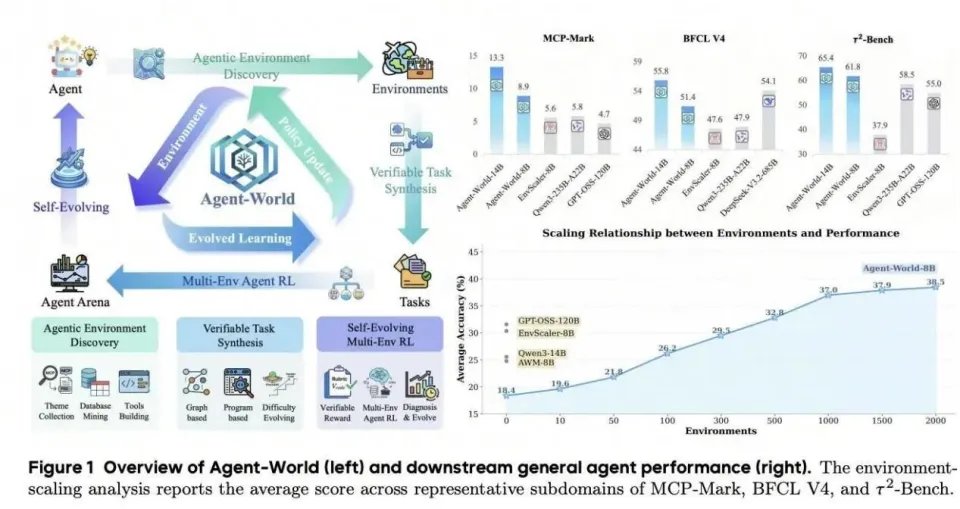
图1:Agent-World总览:左图展示Agent-World智能体与环境的协同进化闭环,右图展示下游性能与环境扩展曲线
最终,Agent-World 构建了1978个环境、19,822 个工具,任务平均交互轮次超过15轮。实验表明,在23 个挑战性的基准上 (包括τ²-Bench、BFCL V4、MCP-Mark、ClawEval、SkillsBench等),Agent-World-8B/14B一致性优于先进的环境扩展方法与强开源基础模型。进一步的实验分析表明,环境多样性、自进化轮次与智能体性能之间存在可扩展关系。


论文标题:
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
论文链接:
https://arxiv.org/pdf/2604.18292
项目主页:
https://agent-tars-world.github.io/-/
目前 Agent-World 在 X 上收获很高关注度,同时荣登 Huggingface Paper 日榜第二名!
Agent-World:
扩展世界环境,让智能体与环境协同进化!
1、智能环境-任务挖掘:从网络中自动挖掘真实世界环境
传统的环境合成方法要么依赖LLM直接生成,要么局限于有限的开源工具数据。Agent-World则选择了一个有趣的思路:从真实世界的环境主题出发,让深度研究智能体自主去广阔的互联网上挖掘环境。
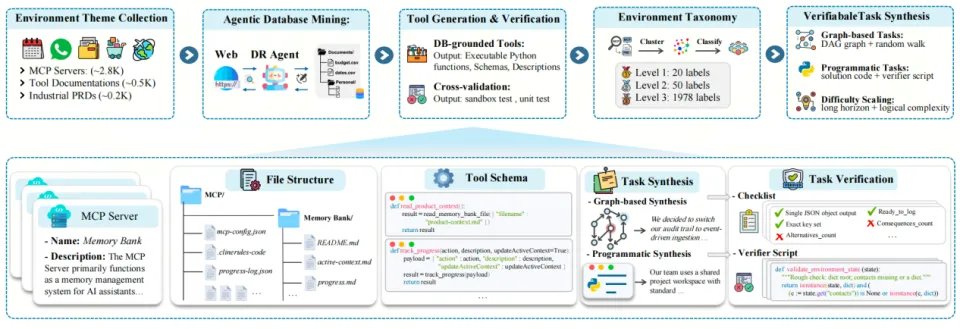
图2:智能环境-任务挖掘流程:包含整体流程概览(上)与各步骤细粒度展示(下)
(1)智能数据库挖掘:Agent-World选定真实MCP服务器数据、开源工具文档、行业需求文档等作为主题锚点(2千余个);对每个主题使用搜索、浏览、代码编译器与文件系统四种工具的深度研究智能体(Deep Research Agent),从海量互联网的网页中自主挖掘主题相关的环境数据库,并通过迭代式地数据复杂化来提升数据库规模与结构真实性。
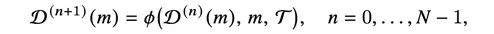
(2)工具接口生成与校验:Agent-World进一步引入代码智能体来为每个环境生成工具接口与单元测试脚本,通过“可编译性、测试准确率、环境最小有效性”三重规则过滤,最终得到一系列包含真实数据库与可执行工具集的交互环境。
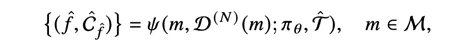
(3)层次化环境分类体系:为了支撑跨环境的任务合成与分层评测,该工作进一步对海量环境生态进行体系构建,通过主题聚类并结合大模型与人工校验,Agent-World将环境生态划分了 20 / 50 /1978的三层级环境标签分类体系(如下图所示)
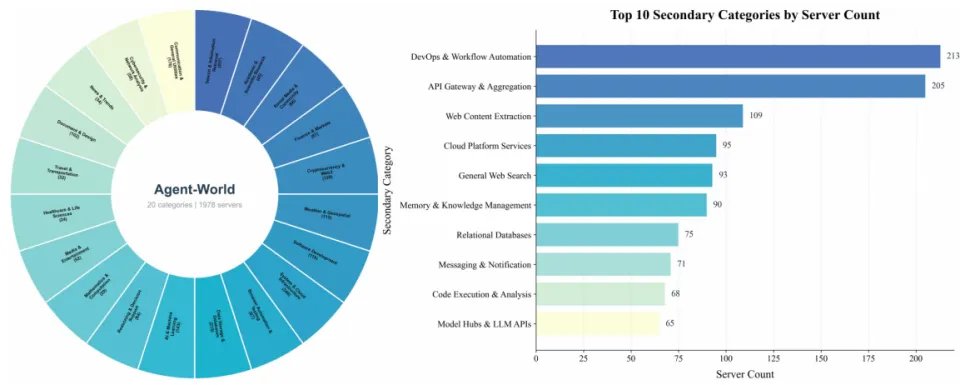
图3:Agent-World的层次环境分类。左图展示20个一级环境,右图展示Top-10二级环境对应三级环境数量。
(4)可验证任务合成:基于高质量的环境生态,Agent-World采用了两种互补的可验证任务合成策略:
• 基于图的任务合成:为环境中的工具构建一个完全连通的依赖图,通过随机游走生成合理的工具调用序列,随后“由链反推”自然语言问题,并配套大模型评分Rubric。这种方法擅长建模顺序依赖的逻辑。
• 程序化任务合成:直接让LLM生成一个需要复杂控制流的Python脚本来解决某个问题,并反向生成对应的问题,可执行验证代码。这种方法能捕捉非线性的复杂推理。
(5)合成环境的统计分析:下图给出了环境与任务分布的详尽统计。经多道过滤后,Agent-World最终沉淀 1,978个环境、19,822 个工具,单环境平均工具数超过10个,体量可观且粒度均衡;环境数据库横跨 JSON、CSV、SQL、HTML、TeX、YAML 等多种文件格式,结构与语义上均呈现高度异质性。
合成任务则以“长程多轮”为主,平均交互轮次超过15轮,对规划、记忆与错误恢复提出持续压力。难度方面,即便是豆包-Seed 2.0在Pass@10设定下仍有相当比例任务无法正确完成,反映出整体任务的极具挑战性。
综上,静态统计从规模、格式、交互长度、难度四个维度共同验证了 Agent-World 合成交互环境在多样性、异质性与复杂性上的显著优势。
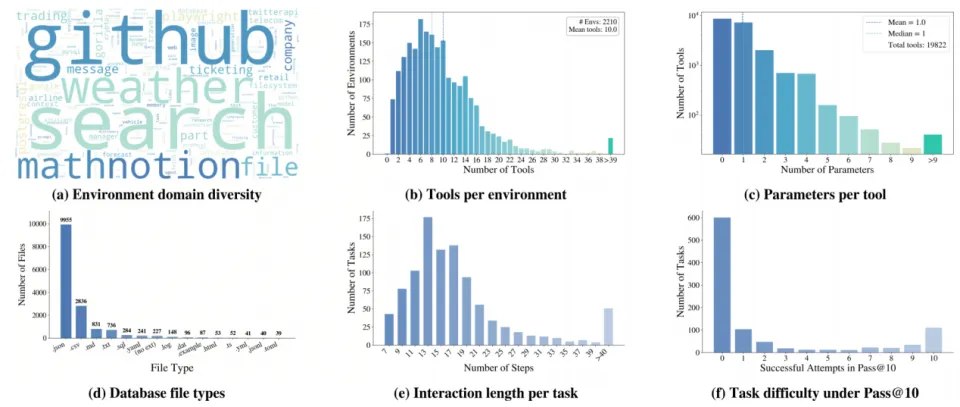
图4:Agent-World合成环境与任务的六维统计分析。
2、持续自进化智能体训练:让智能体与环境协同进化
在构建可扩展,真实的环境生态系统后,Agent-World将其转化为一个动态的智能体训练场(如下图)。
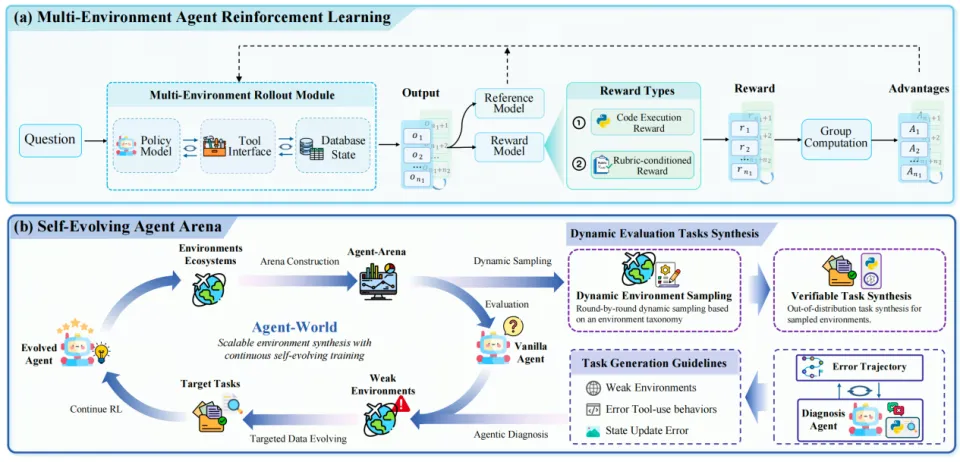
图5:持续自进化智能体训练框架。上方是多环境强化训练,下方是诊断与协同进化循环。
(1)多环境强化学习:与传统 Agent RL 不同,我们的训练在 「智能体–工具–数据库」 的闭环交互中展开。智能体在不同环境中进行 Rollout,调用工具的同时也会改写底层数据库状态,使学习信号真正根植于可执行世界环境。算法上,Agent-World 采用广泛使用的 GRPO 最大化上述可验证奖励,稳定提升Agent性能。
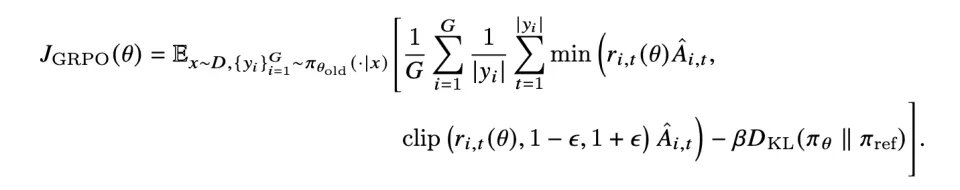
奖励侧亦按任务类型分化:基于图合成的任务由大模型依校验rubric评分细则逐项打分;程序式任务则直接执行验证脚本,依最终答案或状态的正确性给分。
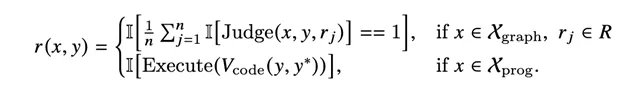
(2)自进化智能体竞技场:Agent-World的核心在于把整个环境生态视作天然的智能体训练竞技场。训练并非一蹴而就,而是一个多轮迭代的自进化过程:
动态评测任务合成:每轮训练结束后,从竞技场的环境池中按环境分类体系均衡采样一批新环境,并为其合成全新的评估任务,避免"刷过的题再考一遍"。
智能体化诊断:让当前轮次的智能体在这批新任务上跑评估;诊断智能体随后分析其失败轨迹、错误分布与环境元信息,定位能力短板(例如"Notion环境下的二级标题创建出错"),输出弱点环境排序与针对性任务生成指南。
智能体–环境协同进化:依据诊断结果,在弱点环境上合成更具挑战性的训练任务,并按需进一步复杂化对应环境数据库;再以这批"薄弱能力定制化数据"驱动下一轮的持续强化学习。
以上流程形成了一个有趣的训练飞轮:“训练提升智能体 →评估暴露弱点 →诊断指引环境/任务扩展 →新数据驱动智能体进一步进化”。这一闭环让智能体与其训练环境实现了真正的“协同进化”。

实验结果:
23 个基准验证Agent-World的跨域智能体能力
实验设置:为充分评估泛化,Agent-World评测5大类领域,共覆盖23个评测基准:
• 智能体工具使用:
MCP-Mark, BFCL V4, τ²-Bench
• 前沿AI助手:
SkillsBench, ARC-AGI-2, ClawEval
• 通用推理:
MATH500, GSM8K, MATH, AIME24/25, KOR-Bench, OlympiadBench 等
• 深度搜索与软件工程:
WebWalkerQA, SWE-Bench, Terminal-Bench, GAIA, HLE 等
• 知识与MCP:
MMLU, SuperGPQA, MCP-Universe 等
对比基线包括前沿闭源模型(GPT-5.2 High, Claude Sonnet-4.5,Seed2.0等)、强开源基础模型(DeepSeek-V3.2-685B, Qwen3-235B-A22B)以及先进的环境扩展方法(EnvScaler,AWM,ScaleEnv)。
1. 核心智能体任务上表现卓越
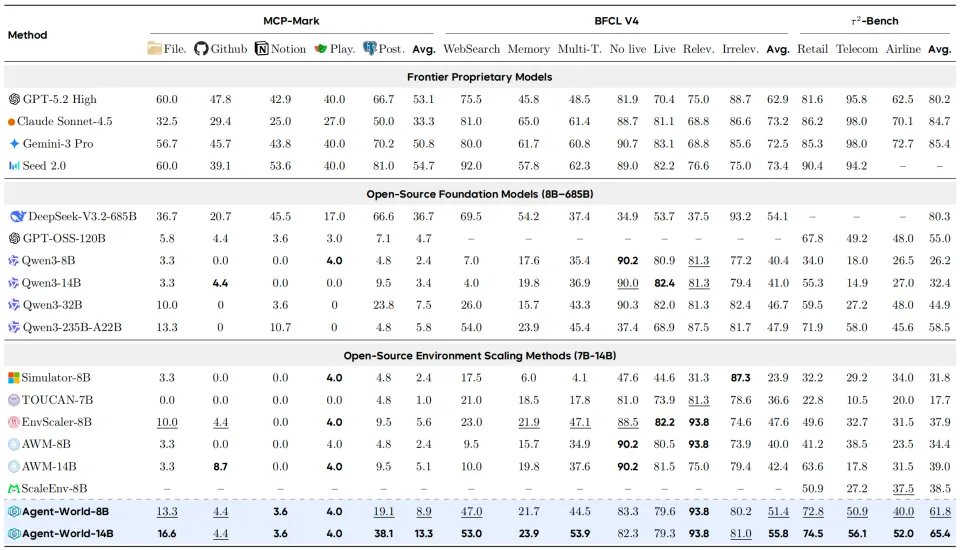
表1:在核心智能体工具使用基准上结果。
如上表所示,在当下最具挑战性的三大智能体工具使用基准—MCP-Mark、BFCL V4、τ²-Bench 上,Agent-World-8B与14B稳定超越所有开源环境扩展基线。这三套基准分别考察多轮有状态交互、跨域工具调用与长程对话,连闭源前沿模型在MCP-Mark上也仅停留在50左右的分位。
更有意思的是,Agent-World-14B在BFCL V4上取得 55.8%,反超 685B 参数的DeepSeek-V3.2-685B(54.1%),这也表明更真实的可执行环境与可验证奖励,比参数更能对齐复杂的智能体交互模式。
2. 长程智能体推理能力显著
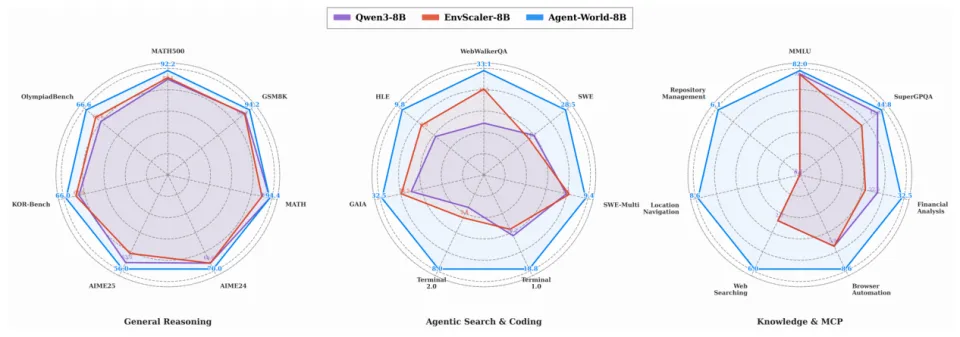
图6:Agent-World-8B在通用推理、智能体搜索与编码、知识与MCP三大能力组上的泛化表现雷达图,全面领先基线。
如上图所示,当我们把评测扩展到17个覆盖长程推理、深度搜索、软件工程与知识应用的基准,Agent-World-8B依然在所有维度上保持领先:通用推理(MATH500, AIME, OlympiadBench等)未因为Agent 相关训练而退化,甚至微微涨幅;在深度搜索,软件工程领域(GAIA, SWE-Bench, Terminal-Bench等)这类超长轮次任务上优势极为明显。
除此以外,在其他知识类与MCP基准表现同样十分优秀,这证明了Agent-World其通过环境训练获得的技能是可迁移、可组合的,而非针对特定基准的过拟合。
图7:Agent-World系列模型在SkillsBench、ARC-AGI-2、ClawEval等前沿AI助手基准上展现优异性能。
3. 先进AI助手场景显著提升
如上图所示,Agent-World在SkillsBench、ARC-AGI-2和ClawEval这三个要求长程规划和真实世界执行的最新基准上同样表现出色,且从8B到14B规模提升稳定,而其他的基线模型则出现了能力波动。
定量分析:
环境规模与自进化如何驱动性能?
除了主实验结果,Agent-World还进行了一系列有趣的定量分析。
1、训练环境规模扩展分析
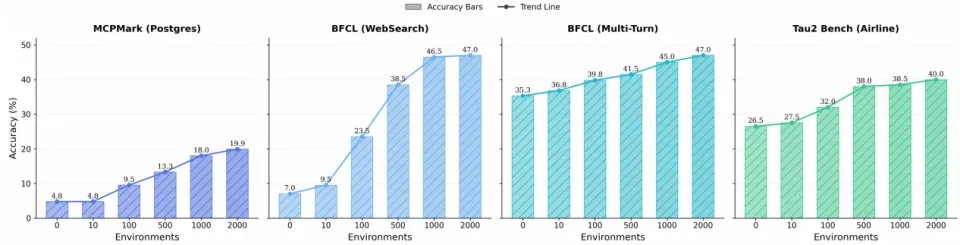
图8:下游智能体性能随着训练环境数量的增加而显著提升,呈现明确的缩放规律。
随着逐步增加训练环境的数量(从0到近2000个),智能体性能与环境数量呈明显的正相关。初期(10到100个环境)性能提升迅猛,说明覆盖关键交互模式至关重要;后期提升放缓但持续,表明更大规模的环境带来了更细粒度的能力提升。
2、自进化轮次分析
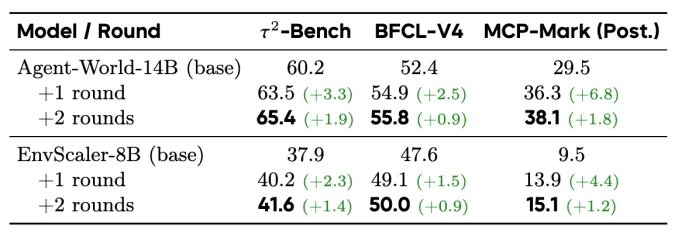
表2:持续自主进化的效果。
研究验证了自进化竞技场闭环的有效性。无论是Agent-World模型自身还是基线模型EnvScaler-8B,经过两轮“评估-诊断-针对性训练”的循环后,一致性地在多个基准上的性能获得一致性增益。这证明将环境作为训练场,针对性驱动数据合成,是持续提升智能体环境泛化能力的有效机制。
3、多环境强化学习曲线分析
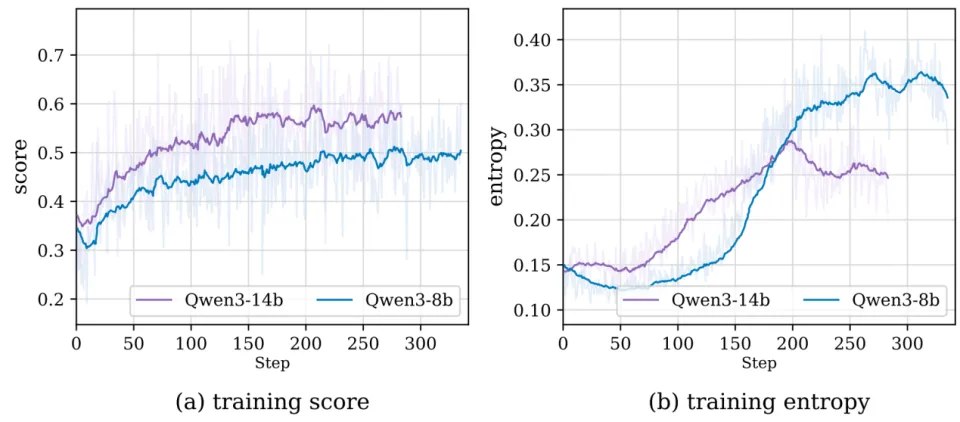
图8:多环境智能体强化学习曲线展示。
Agent-World虽然在复杂,混合的环境与多样化合成任务(基于工具图与程序化)上进行强化学习,其奖励分数随步数稳步上升,而策略熵保持相对稳定甚至增长,表明智能体在适应新环境的同时,保持了良好的探索性,没有过早地陷入局部最优的“固化”行为。
总结与展望
Agent-World希望通过扩展真实世界环境,实现智能体与环境的持续协同进化。作为本文作者,我们也想抛出一些在推动这项研究中发现的几点启示,供研究通用智能体训练方向的朋友们参考与共同探索:
真实性是环境扩展的底座:构建高真实、逻辑可校验的环境,是训练通用智能体的前提。Agent-World 以智能体化流水线对接真实主题与海量网络信息,自动挖掘数据与工具;我们相信这只是起点,未来会有更自动、更贴近真实世界复刻的环境合成范式涌现。
进化是环境训练的动力:规模化环境生态一旦建成,单次静态训练既不够、也浪费高成本构建的环境。Agent-World构建了可自动诊断弱点、定向生成挑战的闭环系统,让智能体与环境协同进化。如何把环境生态与训练算法深度耦合,仍是一条漫长但值得持续押注的路。
环境/任务可扩展性通往泛化性:我们在Agent-World中观察到 “环境规模、自演化轮次、任务难度”与智能体性能之间清晰的scaling关系。这提示未来应同步扩展“更多样的环境、更复杂的任务、更多轮的进化”—这或许正是通往通用智能体交互能力的一把钥匙。
作者简介:本文第一作者是董冠霆,中国人民大学高瓴人工智能学院博士二年级,导师为窦志成教授和文继荣教授。他的主要研究方向为通用智能体训练。以第一/共同第一作者身份在ICLR、ACL等国际顶级会议发表论文10余篇;代表工作包括 ARPO, AUTOIF, Search-o1, Webthinker, FlashRAG等。谷歌学术引用量1万余次,个人GitHub项目星标8000余枚,并在字节跳动Seed、阿里通义千问等基座大模型团队实习。曾获首届腾讯青云奖学金,国家奖学金、北京市优秀毕业生等荣誉。本文的通信作者为中国人民大学的窦志成教授与字节跳动Seed的钟宛君。