突发|arXiv严惩「用AI不核查」行为,违者拉黑一年,连坐所有作者

机器之心编辑部
全球研究者注意:论文预印本上传平台 arXiv 又出新规了!
今天凌晨,俄勒冈州立大学杰出教授(荣休)、arXiv 计算机科学分区 CoRR 的机器学习板块首席版主 Thomas G. Dietterich 宣布:根据我们的行为准则,在论文上署名即表示每位作者对其全部内容承担完全责任,无论这些内容是如何生成的。

如果生成式 AI 工具产生了不当言论、抄袭内容、偏见内容、错误、失误、不实引用或误导性内容,并且这些输出用在了论文中,相关责任均由其作者承担。近期已经明确了针对此类行为的处罚措施。
如果某篇投稿中存在无可辩驳的证据表明,作者并未核查大语言模型(LLM)生成的结果,即意味着我们无法信任该论文中的任何内容。
这里,无可辩驳的证据示例包括:虚构的参考文献、来自大语言模型的元注释(如「这是 200 字的摘要,您需要我做任何修改吗?」「此表中的数据为示意性质,请填入实验的实际数据」等)。
处罚结果为:一年内禁止向 arXiv 投稿。此后再次向 arXiv 投稿时,论文必须先被声誉良好的同行评审平台接收。
从评论区的反馈来看,支持者有很多,「非常好,请坚决执行。」

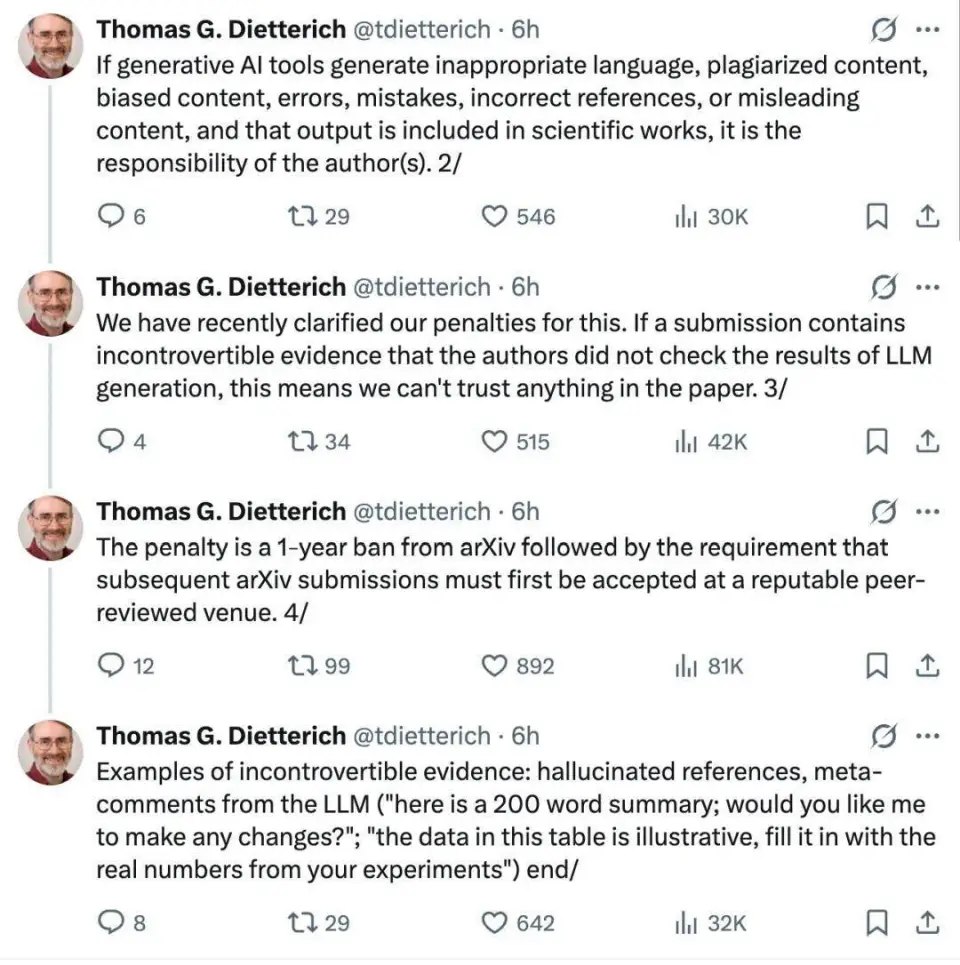
质疑者同样存在,有人认为「这项政策恐怕会根据机构特权和个人的知名度选择性执行,并最终会沦为一种工具,用来让没有背景关系的人闭嘴,而不是促进更良性的科学讨论。」
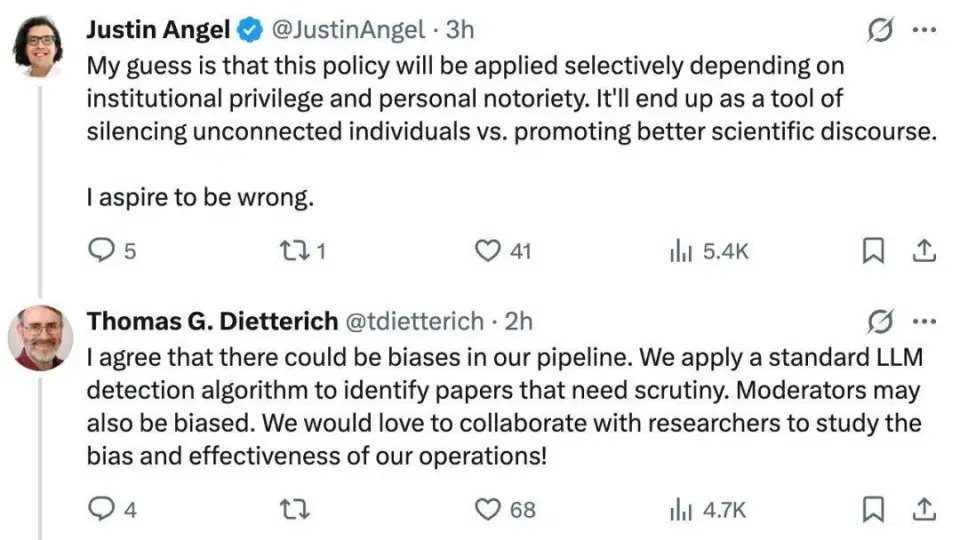
对此,Dietterich 给出了解释,「我承认我们的处理流程中可能会存在偏见。我们会使用一套标准的大语言模型检测算法来识别需要审查的论文。审核人员也可能带有偏见。我们非常乐意与研究者合作,共同研究我们工作中的偏见与成效。
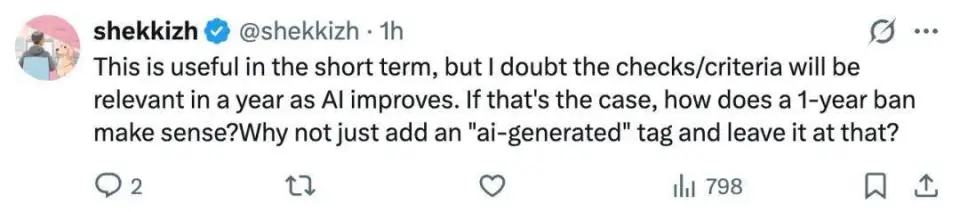
有人觉得「新规在短期内是有用的,但随着 AI 的进步,一年之后这些核查手段和标准是否还能奏效。既然如此,禁投一年的处罚又有什么意义呢?为什么不能直接打上 AI 生成的标签,到此为止就好?」
另外,还有人提出了一些其他问题,比如对每个作者的连坐处罚是否合理,「你如何判断作者是否同意署名?如果某人 X 写了一篇 AI 生成的垃圾论文,在我不知情的情况下把我的名字加上去,然后上传到 arXiv,我也会被连带禁投吗?反过来,如果我和某人 X 一起写了 AI 垃圾论文,他投稿到 arXiv 后被禁了,我能不能假装对这个项目毫不知情来逃避处罚?」

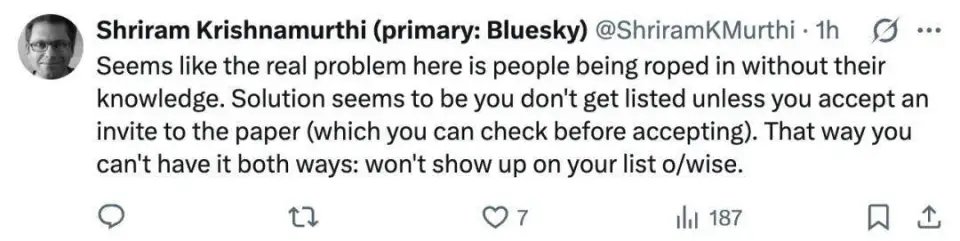
对于上述情况,有人提议,「看起来真正的问题在于有人在自己不知情的情况下被强行署了名。解决方案似乎是:除非你接受了对这篇论文的邀请,而且你在接受前可以先行审阅,否则你的名字就不会出现在作者列表里。」
此次,arXiv 的新规将「使用 AI 辅助写作」的责任边界划分得更加清楚,完全由作者承担。
其实,一些 AI 顶会早已出台了针对论文作者与审稿人「滥用 AI」的规定:
ICLR 2026 惩罚不主动披露滥用 AI 的论文作者,对违规使用 AI 审稿的评审人,他们自己的论文也可能被直接拒稿;
ICML 2026 严禁将 LLM 列为作者,严禁任何形式的隐藏提示词注入;
CVPR 2025 明令在任何审稿阶段都不得使用 LLM 撰写或翻译评审意见。若审稿人被认定高度不负责任(如提交 AI 生成的意见),其自己投稿的论文也可能被直接拒绝。
EMNLP 2025 要求被接收的论文必须附带一份「负责任 NLP 检查清单」。
这些新规标志着,学术界对生成式 AI 的治理已经从讨论进入到了「设立红线、明确惩罚」的实操阶段。