ICML 2026 | 打破「回音室」效应!人大孟澄团队&华为提出集成剪枝视角下的MoE新架构
本文已被 ICML2026 接收,第一作者康欣来、共同第一作者薛敦耀来自中国人民大学统计与大数据研究院。通讯作者为中国人民大学孟澄助理教授与华为基础大模型部研究员陈汉亭。
导语
近年来,Mixture-of-Experts(MoE)已经成为大模型扩展的重要架构之一。相比稠密 Transformer,MoE 通过稀疏激活机制,在每个 token 上只调用少量专家,从而在控制计算成本的同时扩大模型容量。然而,一个长期存在的问题是:专家越多,并不意味着专家真的学得越 “专”。
在标准 MoE 中,路由器通常根据 gating score 选择 top-k 专家。这个机制简单高效,但也容易造成一个问题:训练阶段高分专家被反复共同选中,不同专家持续处理高度重叠的 token 分布,最终导致专家表征趋同。换言之,多个专家可能只是 “看起来不同”,但实际上在学习相似的模式,陷入了一个专家之间彼此强化的 “回音室”。

针对这一问题,来自中国人民大学、华为基础模型部等机构的研究团队提出了 Mahalanobis-Pruned Mixture-of-Experts(MP-MoE)。该工作已被 ICML 2026 接收。
MP-MoE 的核心思想是:不要只选择最高得分的专家,而是从 “集成剪枝”(ensemble pruning)的角度,将 MoE 路由看作一个专家子集选择问题,在选择高置信专家的同时显式鼓励专家之间的多样性。

论文标题:Breaking the Echo Chamber: A Dynamic Ensemble Pruning Perspective on MoE
代码地址:https://github.com/kxlkxl1999/MP-MoE
论文地址:https://github.com/kxlkxl1999/MP-MoE/blob/main/ICML_camera_ready.pdf
MP-MoE 是怎么做的
MP-MoE 的思路可以概括成三步。
第一,从 top-k Routing 到 Mahalanobis Ensemble Routing。

MP-MoE 则进一步引入专家之间的相关性,构造如下目标:
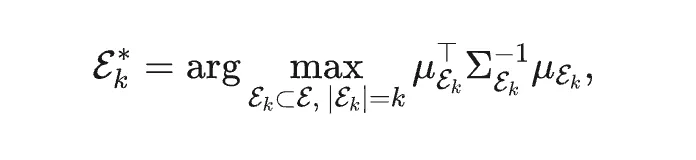

第二,不额外激活专家:使用专家共现矩阵刻画专家相似度。

通常的方法是直接利用专家输出的表征来计算相似度,此类方法往往需要提前激活专家来得到表征,这需要极大的计算代价并且违背了MoE稀疏激活的思想。本文中,作者创新得从概率建模的角度,将某个专家是否被选中看作一个伯努利随机变量,其对应的协方差估计如下:
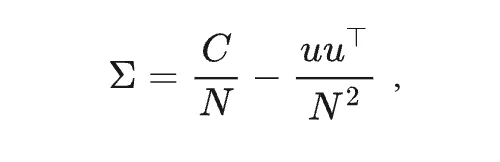

数值实验表明,专家共现矩阵和专家相似矩阵在结构上是高度正相关的,这表明该方法和通常的利用专家输出的表征来计算相似度具有一定一致性,是一种高效的替代。
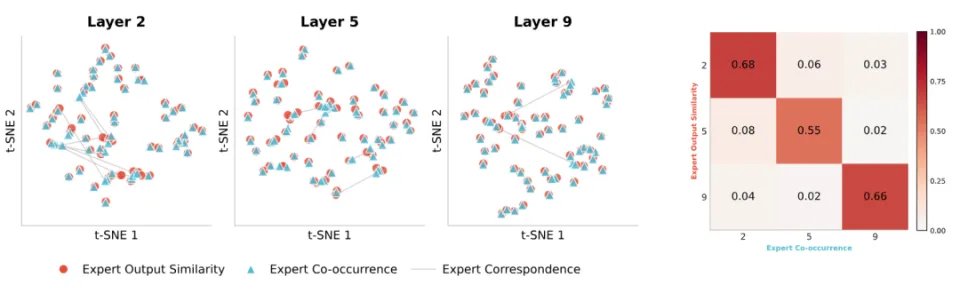
左:专家输出相似度矩阵和共现矩阵的 t-SNE 图,连线代表对应专家配对。该图表明二者在结构分布上具有较高一致性。右:不同层之间专家输出和专家共现的 CKA 相似度。

第三,贪心求解组合优化问题:训练略增开销,推理完全不变。
直接求解上述子集选择问题代价很高,因为需要在所有专家组合中寻找最优子集。为保证可扩展性,MP-MoE 设计了一种高效贪心算法。
每一步中,算法都会评估候选专家加入当前专家集合后的边际收益。这个收益同时考虑两个因素:专家自身的路由分数,以及它与已选专家之间的冗余程度。
为了避免每一步都重新计算矩阵逆,MP-MoE 使用增量 Cholesky 更新,从而显著降低计算复杂度。论文还给出了相应的理论近似保证,说明该贪心选择可以在一定条件下逼近最优专家子集。
最终,MP-MoE 形成了一个训练阶段的动态专家选择机制:一边训练模型,一边更新专家共现矩阵,一边用马氏距离选择更互补的专家组合。
实验结果
专家多样性
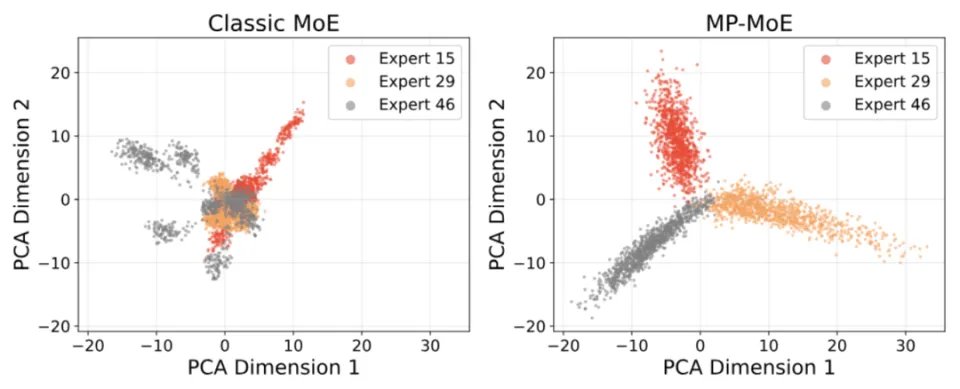
使用线性 CKA 衡量专家之间的输出相似性。结果显示,在相同训练条件下, MP-MoE 的专家间相似度显著低于标准 MoE。具体而言,在 2、5 和 9 层上,标准 MoE 的线性 CKA 分别为 0.43、0.36 和 0.37,而 MP-MoE 分别降至 0.31、0.28 和 0.30,说明专家输出之间的重叠程度明显降低。
在 PCA 可视化中,标准 MoE 的多个专家输出分布存在明显重叠,而 MP-MoE 中不同专家的输出分布更加分离。这说明 MP-MoE 训练出的专家具有更明显的功能区分。
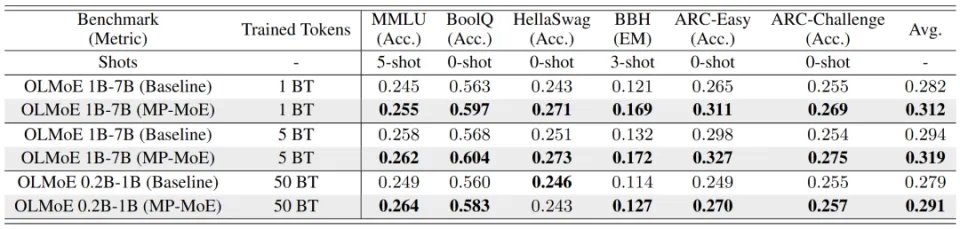
Benchmark 结果
实验结果显示,在相同预训练预算下,MP-MoE 在多个任务上稳定优于标准 MoE 1-3 个百分点。

总结
MP-MoE 提供了一个简单但有效的视角:MoE 路由不应只是选择分数最高的专家,而应选择一个整体互补的专家集合。通过将 MoE 专家选择的思路与集成剪枝联系起来,MP-MoE 巧妙地利用专家共现矩阵计算专家相似度,将其融入基于集成剪枝的优化目标中来提升专家的多样性,并通过高效贪心算法实现可扩展的训练路由。
整体来看,MP-MoE 具有三个突出特点:
第一,它揭示了专家共现和专家相似度之间的关系,显式促进专家多样性。
第二,它是即插即用的路由改造,不需要额外激活所有专家,也不需要改变 MoE 主体结构。
第三,它只在训练阶段引入轻微额外开销,推理阶段可以仍然使用标准 top-k 路由,因此不会增加部署成本。
随着大模型继续向更大规模、更高稀疏度发展,MoE 的关键挑战将不只是 “如何激活更少参数”,还包括 “如何高效地激活专家”。MP-MoE 给出的答案是:不只看分数,也看关系;不只选强者,也选队伍。